 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePPEDCRF: Privacy-Preserving Enhanced Dynamic CRF for Location-Privacy Protection for Sequence Videos with Minimal Detection Degradation
Mar 02, 2026Dashcam videos collected by autonomous or assisted-driving systems are increasingly shared for safety auditing and model improvement. Even when explicit GPS metadata are removed, an attacker can still infer the recording location by matching background visual cues (e.g., buildings and road layouts) against large-scale street-view imagery. This paper studies location-privacy leakage under a background-based retrieval attacker, and proposes PPEDCRF, a privacy-preserving enhanced dynamic conditional random field framework that injects calibrated perturbations only into inferred location-sensitive background regions while preserving foreground detection utility. PPEDCRF consists of three components: (i) a dynamic CRF that enforces temporal consistency to discover and track location sensitive regions across frames, (ii) a normalized control penalty (NCP) that allocates perturbation strength according to a hierarchical sensitivity model, and (iii) a utility-preserving noise injection module that minimizes interference to object detection and segmentation. Experiments on public driving datasets demonstrate that PPEDCRF significantly reduces location-retrieval attack success (e.g., Top-k retrieval accuracy) while maintaining competitive detection performance (e.g., mAP and segmentation metrics) compared with common baselines such as global noise, white-noise masking, and feature-based anonymization. The source code is in https://github.com/mabo1215/PPEDCRF.git
Decoupled Continuous-Time Reinforcement Learning via Hamiltonian Flow
Feb 16, 2026Many real-world control problems, ranging from finance to robotics, evolve in continuous time with non-uniform, event-driven decisions. Standard discrete-time reinforcement learning (RL), based on fixed-step Bellman updates, struggles in this setting: as time gaps shrink, the $Q$-function collapses to the value function $V$, eliminating action ranking. Existing continuous-time methods reintroduce action information via an advantage-rate function $q$. However, they enforce optimality through complicated martingale losses or orthogonality constraints, which are sensitive to the choice of test processes. These approaches entangle $V$ and $q$ into a large, complex optimization problem that is difficult to train reliably. To address these limitations, we propose a novel decoupled continuous-time actor-critic algorithm with alternating updates: $q$ is learned from diffusion generators on $V$, and $V$ is updated via a Hamiltonian-based value flow that remains informative under infinitesimal time steps, where standard max/softmax backups fail. Theoretically, we prove rigorous convergence via new probabilistic arguments, sidestepping the challenge that generator-based Hamiltonians lack Bellman-style contraction under the sup-norm. Empirically, our method outperforms prior continuous-time and leading discrete-time baselines across challenging continuous-control benchmarks and a real-world trading task, achieving 21% profit over a single quarter$-$nearly doubling the second-best method.
Effect-Level Validation for Causal Discovery
Feb 09, 2026Causal discovery is increasingly applied to large-scale telemetry data to estimate the effects of user-facing interventions, yet its reliability for decision-making in feedback-driven systems with strong self-selection remains unclear. In this paper, we propose an effect-centric, admissibility-first framework that treats discovered graphs as structural hypotheses and evaluates them by identifiability, stability, and falsification rather than by graph recovery accuracy alone. Empirically, we study the effect of early exposure to competitive gameplay on short-term retention using real-world game telemetry. We find that many statistically plausible discovery outputs do not admit point-identified causal queries once minimal temporal and semantic constraints are enforced, highlighting identifiability as a critical bottleneck for decision support. When identification is possible, several algorithm families converge to similar, decision-consistent effect estimates despite producing substantially different graph structures, including cases where the direct treatment-outcome edge is absent and the effect is preserved through indirect causal pathways. These converging estimates survive placebo, subsampling, and sensitivity refutation. In contrast, other methods exhibit sporadic admissibility and threshold-sensitive or attenuated effects due to endpoint ambiguity. These results suggest that graph-level metrics alone are inadequate proxies for causal reliability for a given target query. Therefore, trustworthy causal conclusions in telemetry-driven systems require prioritizing admissibility and effect-level validation over causal structural recovery alone.
GRL-SNAM: Geometric Reinforcement Learning with Path Differential Hamiltonians for Simultaneous Navigation and Mapping in Unknown Environments
Dec 31, 2025We present GRL-SNAM, a geometric reinforcement learning framework for Simultaneous Navigation and Mapping(SNAM) in unknown environments. A SNAM problem is challenging as it needs to design hierarchical or joint policies of multiple agents that control the movement of a real-life robot towards the goal in mapless environment, i.e. an environment where the map of the environment is not available apriori, and needs to be acquired through sensors. The sensors are invoked from the path learner, i.e. navigator, through active query responses to sensory agents, and along the motion path. GRL-SNAM differs from preemptive navigation algorithms and other reinforcement learning methods by relying exclusively on local sensory observations without constructing a global map. Our approach formulates path navigation and mapping as a dynamic shortest path search and discovery process using controlled Hamiltonian optimization: sensory inputs are translated into local energy landscapes that encode reachability, obstacle barriers, and deformation constraints, while policies for sensing, planning, and reconfiguration evolve stagewise via updating Hamiltonians. A reduced Hamiltonian serves as an adaptive score function, updating kinetic/potential terms, embedding barrier constraints, and continuously refining trajectories as new local information arrives. We evaluate GRL-SNAM on two different 2D navigation tasks. Comparing against local reactive baselines and global policy learning references under identical stagewise sensing constraints, it preserves clearance, generalizes to unseen layouts, and demonstrates that Geometric RL learning via updating Hamiltonians enables high-quality navigation through minimal exploration via local energy refinement rather than extensive global mapping. The code is publicly available on \href{https://github.com/CVC-Lab/GRL-SNAM}{Github}.
Finetuning LLMs for Automatic Form Interaction on Web-Browser in Selenium Testing Framework
Nov 19, 2025Automated web application testing is a critical component of modern software development, with frameworks like Selenium widely adopted for validating functionality through browser automation. Among the essential aspects of such testing is the ability to interact with and validate web forms, a task that requires syntactically correct, executable scripts with high coverage of input fields. Despite its importance, this task remains underexplored in the context of large language models (LLMs), and no public benchmark or dataset exists to evaluate LLMs on form interaction generation systematically. This paper introduces a novel method for training LLMs to generate high-quality test cases in Selenium, specifically targeting form interaction testing. We curate both synthetic and human-annotated datasets for training and evaluation, covering diverse real-world forms and testing scenarios. We define clear metrics for syntax correctness, script executability, and input field coverage. Our empirical study demonstrates that our approach significantly outperforms strong baselines, including GPT-4o and other popular LLMs, across all evaluation metrics. Our work lays the groundwork for future research on LLM-based web testing and provides resources to support ongoing progress in this area.
Fusionista2.0: Efficiency Retrieval System for Large-Scale Datasets
Nov 15, 2025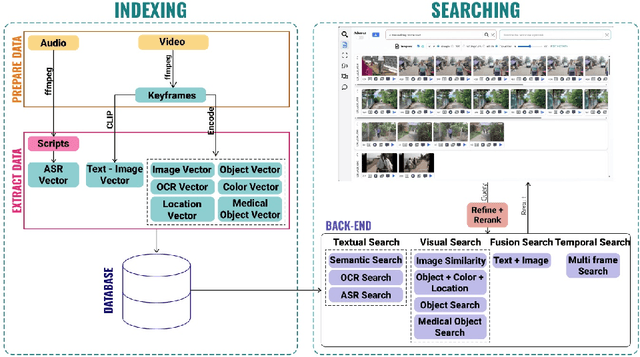

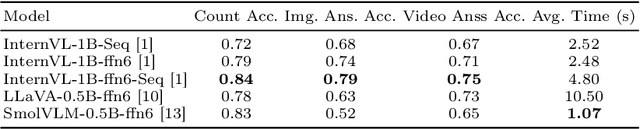
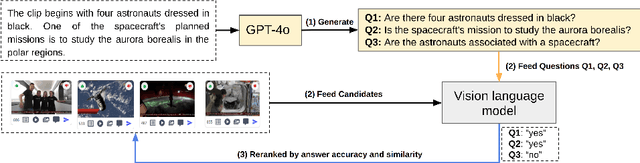
The Video Browser Showdown (VBS) challenges systems to deliver accurate results under strict time constraints. To meet this demand, we present Fusionista2.0, a streamlined video retrieval system optimized for speed and usability. All core modules were re-engineered for efficiency: preprocessing now relies on ffmpeg for fast keyframe extraction, optical character recognition uses Vintern-1B-v3.5 for robust multilingual text recognition, and automatic speech recognition employs faster-whisper for real-time transcription. For question answering, lightweight vision-language models provide quick responses without the heavy cost of large models. Beyond these technical upgrades, Fusionista2.0 introduces a redesigned user interface with improved responsiveness, accessibility, and workflow efficiency, enabling even non-expert users to retrieve relevant content rapidly. Evaluations demonstrate that retrieval time was reduced by up to 75% while accuracy and user satisfaction both increased, confirming Fusionista2.0 as a competitive and user-friendly system for large-scale video search.
Learning Generalized Hamiltonian Dynamics with Stability from Noisy Trajectory Data
Sep 08, 2025We introduce a robust framework for learning various generalized Hamiltonian dynamics from noisy, sparse phase-space data and in an unsupervised manner based on variational Bayesian inference. Although conservative, dissipative, and port-Hamiltonian systems might share the same initial total energy of a closed system, it is challenging for a single Hamiltonian network model to capture the distinctive and varying motion dynamics and physics of a phase space, from sampled observational phase space trajectories. To address this complicated Hamiltonian manifold learning challenge, we extend sparse symplectic, random Fourier Gaussian processes learning with predictive successive numerical estimations of the Hamiltonian landscape, using a generalized form of state and conjugate momentum Hamiltonian dynamics, appropriate to different classes of conservative, dissipative and port-Hamiltonian physical systems. In addition to the kernelized evidence lower bound (ELBO) loss for data fidelity, we incorporate stability and conservation constraints as additional hyper-parameter balanced loss terms to regularize the model's multi-gradients, enforcing physics correctness for improved prediction accuracy with bounded uncertainty.
One STEP at a time: Language Agents are Stepwise Planners
Nov 13, 2024Language agents have shown promising adaptability in dynamic environments to perform complex tasks. However, despite the versatile knowledge embedded in large language models, these agents still fall short when it comes to tasks that require planning. We introduce STEP, a novel framework designed to efficiently learn from previous experiences to enhance the planning capabilities of language agents in future steps. Concretely, STEP functions through four interconnected components. First, the Planner takes on the task, breaks it down into subtasks and provides relevant insights. Then the Executor generates action candidates, while the Evaluator ensures the actions align with learned rules from previous experiences. Lastly, Memory stores experiences to inform future decisions. In the ScienceWorld benchmark, our results show that STEP consistently outperforms state-of-the-art models, achieving an overall score of 67.4 and successfully completing 12 out of 18 tasks. These findings highlight STEP's potential as a framework for enhancing planning capabilities in language agents, paving the way for more sophisticated task-solving in dynamic environments.
Low-cost Robust Night-time Aerial Material Segmentation through Hyperspectral Data and Sparse Spatio-Temporal Learning
Oct 19, 2024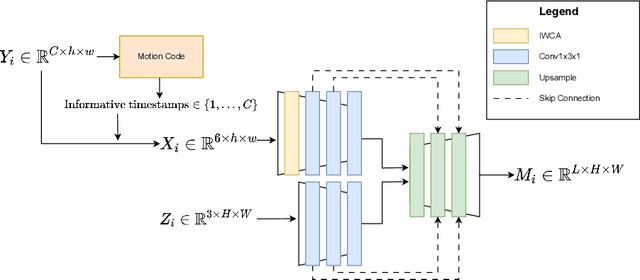



Material segmentation is a complex task, particularly when dealing with aerial data in poor lighting and atmospheric conditions. To address this, hyperspectral data from specialized cameras can be very useful in addition to RGB images. However, due to hardware constraints, high spectral data often come with lower spatial resolution. Additionally, incorporating such data into a learning-based segmentation framework is challenging due to the numerous data channels involved. To overcome these difficulties, we propose an innovative Siamese framework that uses time series-based compression to effectively and scalably integrate the additional spectral data into the segmentation task. We demonstrate our model's effectiveness through competitive benchmarks on aerial datasets in various environmental conditions.
Effective Segmentation of Post-Treatment Gliomas Using Simple Approaches: Artificial Sequence Generation and Ensemble Models
Sep 12, 2024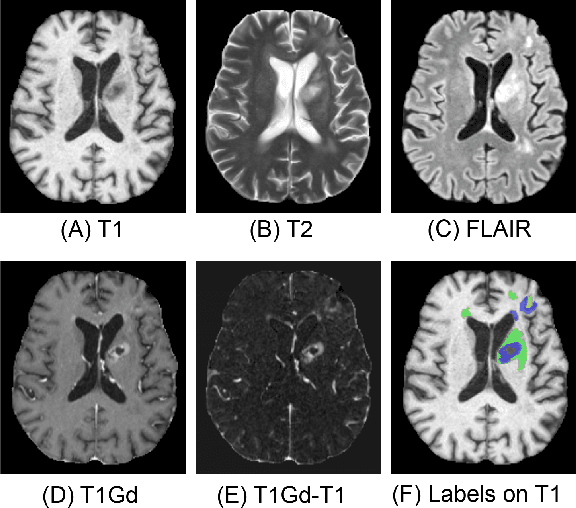
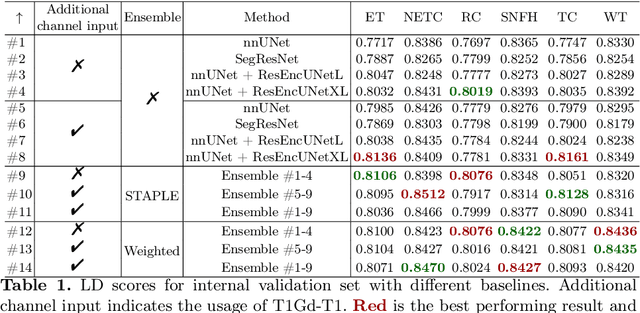
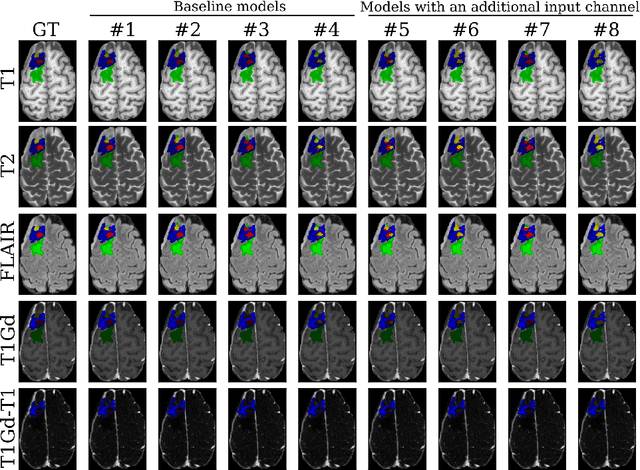
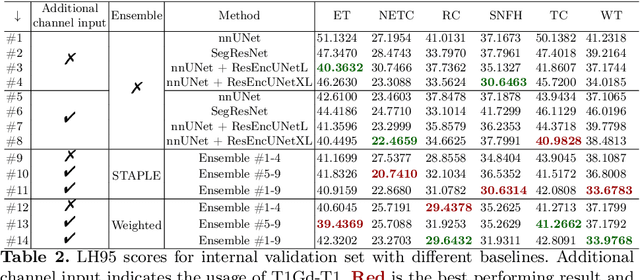
Segmentation is a crucial task in the medical imaging field and is often an important primary step or even a prerequisite to the analysis of medical volumes. Yet treatments such as surgery complicate the accurate delineation of regions of interest. The BraTS Post-Treatment 2024 Challenge published the first public dataset for post-surgery glioma segmentation and addresses the aforementioned issue by fostering the development of automated segmentation tools for glioma in MRI data. In this effort, we propose two straightforward approaches to enhance the segmentation performances of deep learning-based methodologies. First, we incorporate an additional input based on a simple linear combination of the available MRI sequences input, which highlights enhancing tumors. Second, we employ various ensembling methods to weigh the contribution of a battery of models. Our results demonstrate that these approaches significantly improve segmentation performance compared to baseline models, underscoring the effectiveness of these simple approaches in improving medical image segmentation tasks.