 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-Time Instance-Specific Parameter Composition: A New Paradigm for Adaptive Generative Modeling
Mar 29, 2026Existing generative models, such as diffusion and auto-regressive networks, are inherently static, relying on a fixed set of pretrained parameters to handle all inputs. In contrast, humans flexibly adapt their internal generative representations to each perceptual or imaginative context. Inspired by this capability, we introduce Composer, a new paradigm for adaptive generative modeling based on test-time instance-specific parameter composition. Composer generates input-conditioned parameter adaptations at inference time, which are injected into the pretrained model's weights, enabling per-input specialization without fine-tuning or retraining. Adaptation occurs once prior to multi-step generation, yielding higher-quality, context-aware outputs with minimal computational and memory overhead. Experiments show that Composer substantially improves performance across diverse generative models and use cases, including lightweight/quantized models and test-time scaling. By leveraging input-aware parameter composition, Composer establishes a new paradigm for designing generative models that dynamically adapt to each input, moving beyond static parameterization.
Identifying Speakers in Dialogue Transcripts: A Text-based Approach Using Pretrained Language Models
Jul 16, 2024



We introduce an approach to identifying speaker names in dialogue transcripts, a crucial task for enhancing content accessibility and searchability in digital media archives. Despite the advancements in speech recognition, the task of text-based speaker identification (SpeakerID) has received limited attention, lacking large-scale, diverse datasets for effective model training. Addressing these gaps, we present a novel, large-scale dataset derived from the MediaSum corpus, encompassing transcripts from a wide range of media sources. We propose novel transformer-based models tailored for SpeakerID, leveraging contextual cues within dialogues to accurately attribute speaker names. Through extensive experiments, our best model achieves a great precision of 80.3\%, setting a new benchmark for SpeakerID. The data and code are publicly available here: \url{https://github.com/adobe-research/speaker-identification}
A Class-aware Optimal Transport Approach with Higher-Order Moment Matching for Unsupervised Domain Adaptation
Jan 29, 2024Unsupervised domain adaptation (UDA) aims to transfer knowledge from a labeled source domain to an unlabeled target domain. In this paper, we introduce a novel approach called class-aware optimal transport (OT), which measures the OT distance between a distribution over the source class-conditional distributions and a mixture of source and target data distribution. Our class-aware OT leverages a cost function that determines the matching extent between a given data example and a source class-conditional distribution. By optimizing this cost function, we find the optimal matching between target examples and source class-conditional distributions, effectively addressing the data and label shifts that occur between the two domains. To handle the class-aware OT efficiently, we propose an amortization solution that employs deep neural networks to formulate the transportation probabilities and the cost function. Additionally, we propose minimizing class-aware Higher-order Moment Matching (HMM) to align the corresponding class regions on the source and target domains. The class-aware HMM component offers an economical computational approach for accurately evaluating the HMM distance between the two distributions. Extensive experiments on benchmark datasets demonstrate that our proposed method significantly outperforms existing state-of-the-art baselines.
Aspect-based Meeting Transcript Summarization: A Two-Stage Approach with Weak Supervision on Sentence Classification
Nov 07, 2023



Aspect-based meeting transcript summarization aims to produce multiple summaries, each focusing on one aspect of content in a meeting transcript. It is challenging as sentences related to different aspects can mingle together, and those relevant to a specific aspect can be scattered throughout the long transcript of a meeting. The traditional summarization methods produce one summary mixing information of all aspects, which cannot deal with the above challenges of aspect-based meeting transcript summarization. In this paper, we propose a two-stage method for aspect-based meeting transcript summarization. To select the input content related to specific aspects, we train a sentence classifier on a dataset constructed from the AMI corpus with pseudo-labeling. Then we merge the sentences selected for a specific aspect as the input for the summarizer to produce the aspect-based summary. Experimental results on the AMI corpus outperform many strong baselines, which verifies the effectiveness of our proposed method.
Unleash Data Generation for Efficient and Effective Data-free Knowledge Distillation
Sep 30, 2023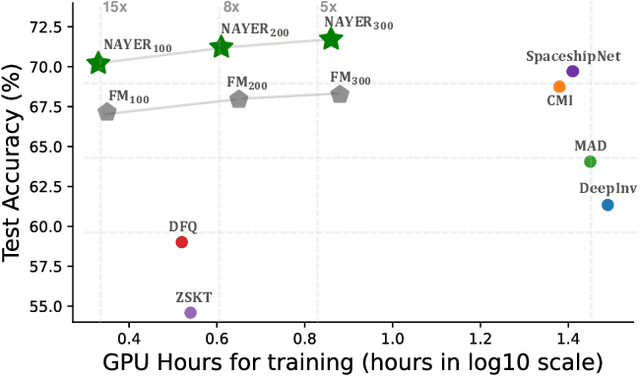
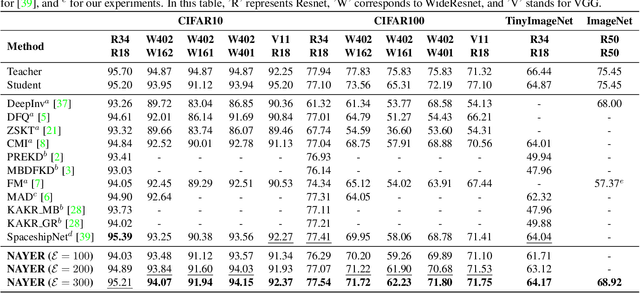


Data-Free Knowledge Distillation (DFKD) has recently made remarkable advancements with its core principle of transferring knowledge from a teacher neural network to a student neural network without requiring access to the original data. Nonetheless, existing approaches encounter a significant challenge when attempting to generate samples from random noise inputs, which inherently lack meaningful information. Consequently, these models struggle to effectively map this noise to the ground-truth sample distribution, resulting in the production of low-quality data and imposing substantial time requirements for training the generator. In this paper, we propose a novel Noisy Layer Generation method (NAYER) which relocates the randomness source from the input to a noisy layer and utilizes the meaningful label-text embedding (LTE) as the input. The significance of LTE lies in its ability to contain substantial meaningful inter-class information, enabling the generation of high-quality samples with only a few training steps. Simultaneously, the noisy layer plays a key role in addressing the issue of diversity in sample generation by preventing the model from overemphasizing the constrained label information. By reinitializing the noisy layer in each iteration, we aim to facilitate the generation of diverse samples while still retaining the method's efficiency, thanks to the ease of learning provided by LTE. Experiments carried out on multiple datasets demonstrate that our NAYER not only outperforms the state-of-the-art methods but also achieves speeds 5 to 15 times faster than previous approaches.
FACTUAL: A Benchmark for Faithful and Consistent Textual Scene Graph Parsing
Jun 01, 2023



Textual scene graph parsing has become increasingly important in various vision-language applications, including image caption evaluation and image retrieval. However, existing scene graph parsers that convert image captions into scene graphs often suffer from two types of errors. First, the generated scene graphs fail to capture the true semantics of the captions or the corresponding images, resulting in a lack of faithfulness. Second, the generated scene graphs have high inconsistency, with the same semantics represented by different annotations. To address these challenges, we propose a novel dataset, which involves re-annotating the captions in Visual Genome (VG) using a new intermediate representation called FACTUAL-MR. FACTUAL-MR can be directly converted into faithful and consistent scene graph annotations. Our experimental results clearly demonstrate that the parser trained on our dataset outperforms existing approaches in terms of faithfulness and consistency. This improvement leads to a significant performance boost in both image caption evaluation and zero-shot image retrieval tasks. Furthermore, we introduce a novel metric for measuring scene graph similarity, which, when combined with the improved scene graph parser, achieves state-of-the-art (SOTA) results on multiple benchmark datasets for the aforementioned tasks. The code and dataset are available at https://github.com/zhuang-li/FACTUAL .
Class based Influence Functions for Error Detection
May 02, 2023


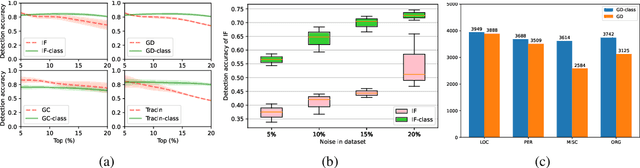
Influence functions (IFs) are a powerful tool for detecting anomalous examples in large scale datasets. However, they are unstable when applied to deep networks. In this paper, we provide an explanation for the instability of IFs and develop a solution to this problem. We show that IFs are unreliable when the two data points belong to two different classes. Our solution leverages class information to improve the stability of IFs. Extensive experiments show that our modification significantly improves the performance and stability of IFs while incurring no additional computational cost.
Vision Transformer Visualization: What Neurons Tell and How Neurons Behave?
Oct 18, 2022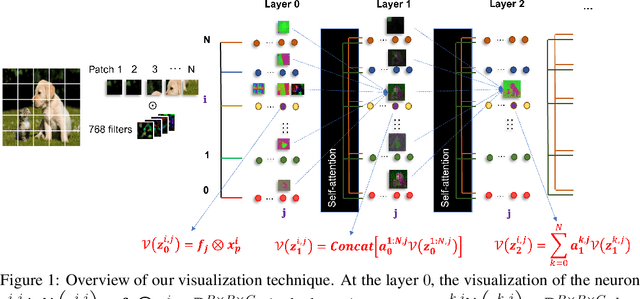
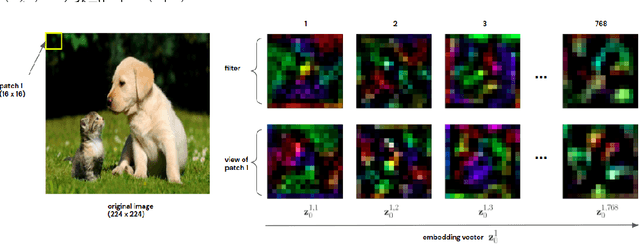


Recently vision transformers (ViT) have been applied successfully for various tasks in computer vision. However, important questions such as why they work or how they behave still remain largely unknown. In this paper, we propose an effective visualization technique, to assist us in exposing the information carried in neurons and feature embeddings across the ViT's layers. Our approach departs from the computational process of ViTs with a focus on visualizing the local and global information in input images and the latent feature embeddings at multiple levels. Visualizations at the input and embeddings at level 0 reveal interesting findings such as providing support as to why ViTs are rather generally robust to image occlusions and patch shuffling; or unlike CNNs, level 0 embeddings already carry rich semantic details. Next, we develop a rigorous framework to perform effective visualizations across layers, exposing the effects of ViTs filters and grouping/clustering behaviors to object patches. Finally, we provide comprehensive experiments on real datasets to qualitatively and quantitatively demonstrate the merit of our proposed methods as well as our findings. https://github.com/byM1902/ViT_visualization
An Additive Instance-Wise Approach to Multi-class Model Interpretation
Jul 07, 2022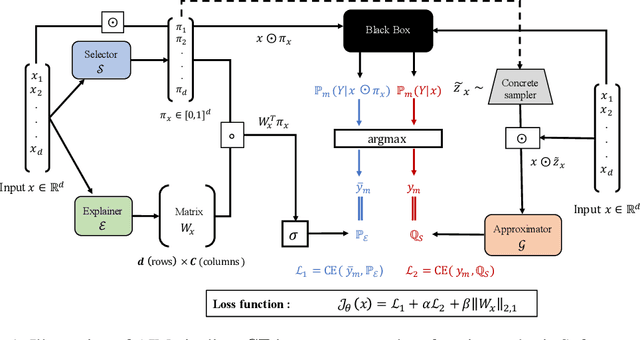
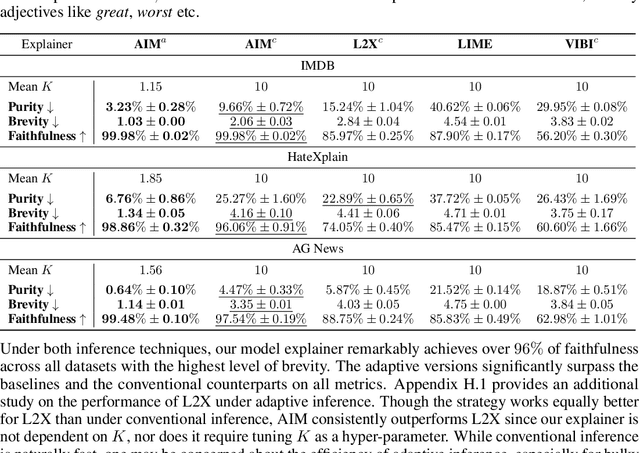
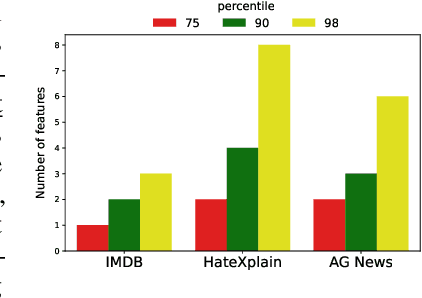

Interpretable machine learning offers insights into what factors drive a certain prediction of a black-box system and whether to trust it for high-stakes decisions or large-scale deployment. Existing methods mainly focus on selecting explanatory input features, which follow either locally additive or instance-wise approaches. Additive models use heuristically sampled perturbations to learn instance-specific explainers sequentially. The process is thus inefficient and susceptible to poorly-conditioned samples. Meanwhile, instance-wise techniques directly learn local sampling distributions and can leverage global information from other inputs. However, they can only interpret single-class predictions and suffer from inconsistency across different settings, due to a strict reliance on a pre-defined number of features selected. This work exploits the strengths of both methods and proposes a global framework for learning local explanations simultaneously for multiple target classes. We also propose an adaptive inference strategy to determine the optimal number of features for a specific instance. Our model explainer significantly outperforms additive and instance-wise counterparts on faithfulness while achieves high level of brevity on various data sets and black-box model architectures.
ReGVD: Revisiting Graph Neural Networks for Vulnerability Detection
Oct 14, 2021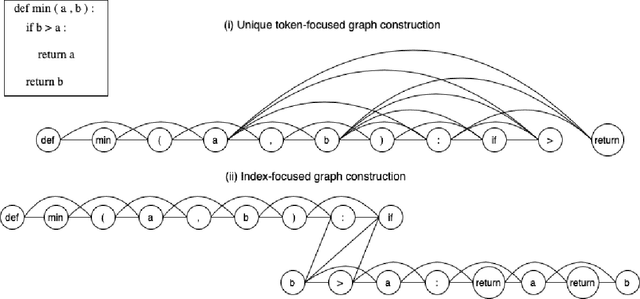
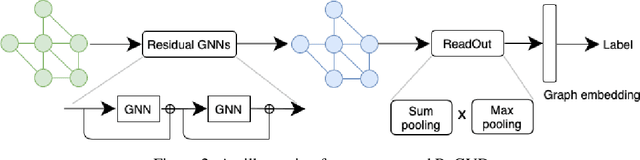
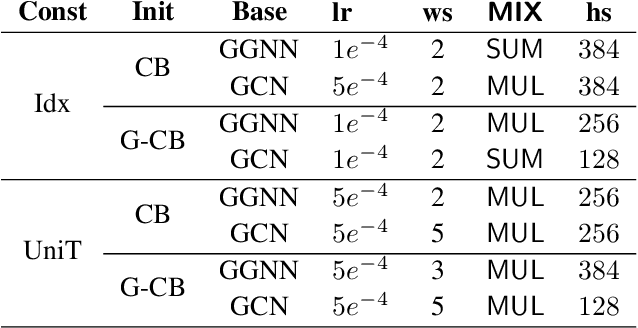
Identifying vulnerabilities in the source code is essential to protect the software systems from cyber security attacks. It, however, is also a challenging step that requires specialized expertise in security and code representation. Inspired by the successful applications of pre-trained programming language (PL) models such as CodeBERT and graph neural networks (GNNs), we propose ReGVD, a general and novel graph neural network-based model for vulnerability detection. In particular, ReGVD views a given source code as a flat sequence of tokens and then examines two effective methods of utilizing unique tokens and indexes respectively to construct a single graph as an input, wherein node features are initialized only by the embedding layer of a pre-trained PL model. Next, ReGVD leverages a practical advantage of residual connection among GNN layers and explores a beneficial mixture of graph-level sum and max poolings to return a graph embedding for the given source code. Experimental results demonstrate that ReGVD outperforms the existing state-of-the-art models and obtain the highest accuracy on the real-world benchmark dataset from CodeXGLUE for vulnerability detection.