 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnleash Data Generation for Efficient and Effective Data-free Knowledge Distillation
Paper and Code
Sep 30, 2023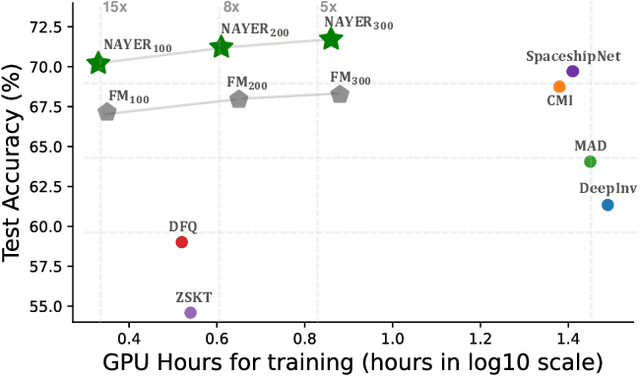
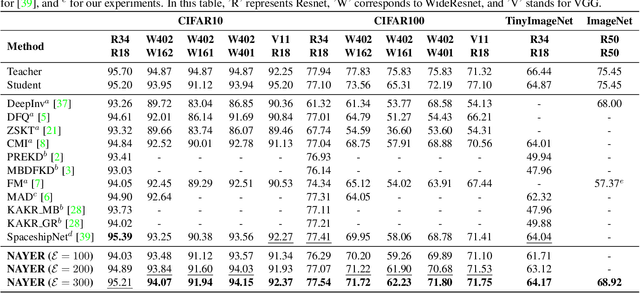


Data-Free Knowledge Distillation (DFKD) has recently made remarkable advancements with its core principle of transferring knowledge from a teacher neural network to a student neural network without requiring access to the original data. Nonetheless, existing approaches encounter a significant challenge when attempting to generate samples from random noise inputs, which inherently lack meaningful information. Consequently, these models struggle to effectively map this noise to the ground-truth sample distribution, resulting in the production of low-quality data and imposing substantial time requirements for training the generator. In this paper, we propose a novel Noisy Layer Generation method (NAYER) which relocates the randomness source from the input to a noisy layer and utilizes the meaningful label-text embedding (LTE) as the input. The significance of LTE lies in its ability to contain substantial meaningful inter-class information, enabling the generation of high-quality samples with only a few training steps. Simultaneously, the noisy layer plays a key role in addressing the issue of diversity in sample generation by preventing the model from overemphasizing the constrained label information. By reinitializing the noisy layer in each iteration, we aim to facilitate the generation of diverse samples while still retaining the method's efficiency, thanks to the ease of learning provided by LTE. Experiments carried out on multiple datasets demonstrate that our NAYER not only outperforms the state-of-the-art methods but also achieves speeds 5 to 15 times faster than previous approaches.