 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-Time Instance-Specific Parameter Composition: A New Paradigm for Adaptive Generative Modeling
Mar 29, 2026Existing generative models, such as diffusion and auto-regressive networks, are inherently static, relying on a fixed set of pretrained parameters to handle all inputs. In contrast, humans flexibly adapt their internal generative representations to each perceptual or imaginative context. Inspired by this capability, we introduce Composer, a new paradigm for adaptive generative modeling based on test-time instance-specific parameter composition. Composer generates input-conditioned parameter adaptations at inference time, which are injected into the pretrained model's weights, enabling per-input specialization without fine-tuning or retraining. Adaptation occurs once prior to multi-step generation, yielding higher-quality, context-aware outputs with minimal computational and memory overhead. Experiments show that Composer substantially improves performance across diverse generative models and use cases, including lightweight/quantized models and test-time scaling. By leveraging input-aware parameter composition, Composer establishes a new paradigm for designing generative models that dynamically adapt to each input, moving beyond static parameterization.
SHIP: A Shapelet-based Approach for Interpretable Patient-Ventilator Asynchrony Detection
Mar 09, 2025Patient-ventilator asynchrony (PVA) is a common and critical issue during mechanical ventilation, affecting up to 85% of patients. PVA can result in clinical complications such as discomfort, sleep disruption, and potentially more severe conditions like ventilator-induced lung injury and diaphragm dysfunction. Traditional PVA management, which relies on manual adjustments by healthcare providers, is often inadequate due to delays and errors. While various computational methods, including rule-based, statistical, and deep learning approaches, have been developed to detect PVA events, they face challenges related to dataset imbalances and lack of interpretability. In this work, we propose a shapelet-based approach SHIP for PVA detection, utilizing shapelets - discriminative subsequences in time-series data - to enhance detection accuracy and interpretability. Our method addresses dataset imbalances through shapelet-based data augmentation and constructs a shapelet pool to transform the dataset for more effective classification. The combined shapelet and statistical features are then used in a classifier to identify PVA events. Experimental results on medical datasets show that SHIP significantly improves PVA detection while providing interpretable insights into model decisions.
Large-Scale Data-Free Knowledge Distillation for ImageNet via Multi-Resolution Data Generation
Nov 26, 2024



Data-Free Knowledge Distillation (DFKD) is an advanced technique that enables knowledge transfer from a teacher model to a student model without relying on original training data. While DFKD methods have achieved success on smaller datasets like CIFAR10 and CIFAR100, they encounter challenges on larger, high-resolution datasets such as ImageNet. A primary issue with previous approaches is their generation of synthetic images at high resolutions (e.g., $224 \times 224$) without leveraging information from real images, often resulting in noisy images that lack essential class-specific features in large datasets. Additionally, the computational cost of generating the extensive data needed for effective knowledge transfer can be prohibitive. In this paper, we introduce MUlti-reSolution data-freE (MUSE) to address these limitations. MUSE generates images at lower resolutions while using Class Activation Maps (CAMs) to ensure that the generated images retain critical, class-specific features. To further enhance model diversity, we propose multi-resolution generation and embedding diversity techniques that strengthen latent space representations, leading to significant performance improvements. Experimental results demonstrate that MUSE achieves state-of-the-art performance across both small- and large-scale datasets, with notable performance gains of up to two digits in nearly all ImageNet and subset experiments. Code is available at https://github.com/tmtuan1307/muse.
ShapeFormer: Shapelet Transformer for Multivariate Time Series Classification
May 23, 2024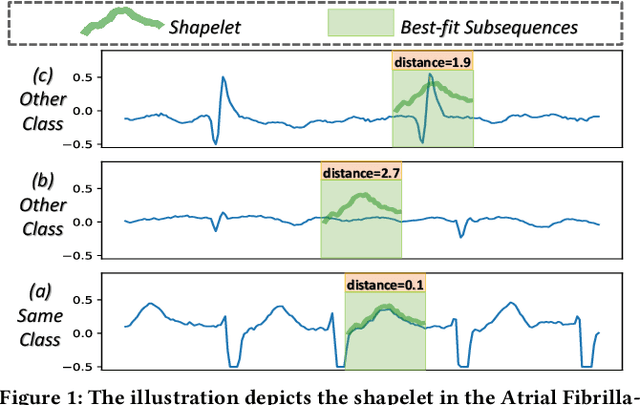
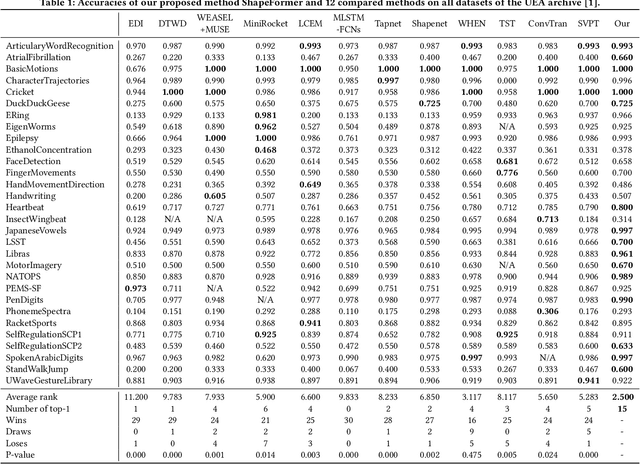
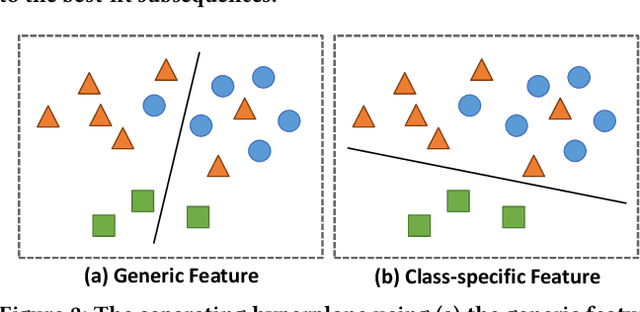
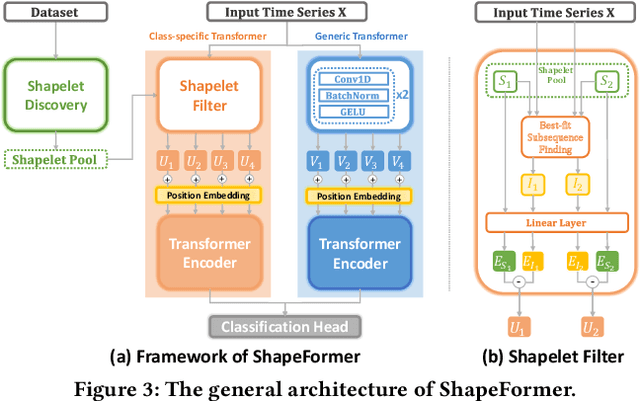
Multivariate time series classification (MTSC) has attracted significant research attention due to its diverse real-world applications. Recently, exploiting transformers for MTSC has achieved state-of-the-art performance. However, existing methods focus on generic features, providing a comprehensive understanding of data, but they ignore class-specific features crucial for learning the representative characteristics of each class. This leads to poor performance in the case of imbalanced datasets or datasets with similar overall patterns but differing in minor class-specific details. In this paper, we propose a novel Shapelet Transformer (ShapeFormer), which comprises class-specific and generic transformer modules to capture both of these features. In the class-specific module, we introduce the discovery method to extract the discriminative subsequences of each class (i.e. shapelets) from the training set. We then propose a Shapelet Filter to learn the difference features between these shapelets and the input time series. We found that the difference feature for each shapelet contains important class-specific features, as it shows a significant distinction between its class and others. In the generic module, convolution filters are used to extract generic features that contain information to distinguish among all classes. For each module, we employ the transformer encoder to capture the correlation between their features. As a result, the combination of two transformer modules allows our model to exploit the power of both types of features, thereby enhancing the classification performance. Our experiments on 30 UEA MTSC datasets demonstrate that ShapeFormer has achieved the highest accuracy ranking compared to state-of-the-art methods. The code is available at https://github.com/xuanmay2701/shapeformer.
Text-Enhanced Data-free Approach for Federated Class-Incremental Learning
Mar 21, 2024



Federated Class-Incremental Learning (FCIL) is an underexplored yet pivotal issue, involving the dynamic addition of new classes in the context of federated learning. In this field, Data-Free Knowledge Transfer (DFKT) plays a crucial role in addressing catastrophic forgetting and data privacy problems. However, prior approaches lack the crucial synergy between DFKT and the model training phases, causing DFKT to encounter difficulties in generating high-quality data from a non-anchored latent space of the old task model. In this paper, we introduce LANDER (Label Text Centered Data-Free Knowledge Transfer) to address this issue by utilizing label text embeddings (LTE) produced by pretrained language models. Specifically, during the model training phase, our approach treats LTE as anchor points and constrains the feature embeddings of corresponding training samples around them, enriching the surrounding area with more meaningful information. In the DFKT phase, by using these LTE anchors, LANDER can synthesize more meaningful samples, thereby effectively addressing the forgetting problem. Additionally, instead of tightly constraining embeddings toward the anchor, the Bounding Loss is introduced to encourage sample embeddings to remain flexible within a defined radius. This approach preserves the natural differences in sample embeddings and mitigates the embedding overlap caused by heterogeneous federated settings. Extensive experiments conducted on CIFAR100, Tiny-ImageNet, and ImageNet demonstrate that LANDER significantly outperforms previous methods and achieves state-of-the-art performance in FCIL. The code is available at https://github.com/tmtuan1307/lander.
Unleash Data Generation for Efficient and Effective Data-free Knowledge Distillation
Sep 30, 2023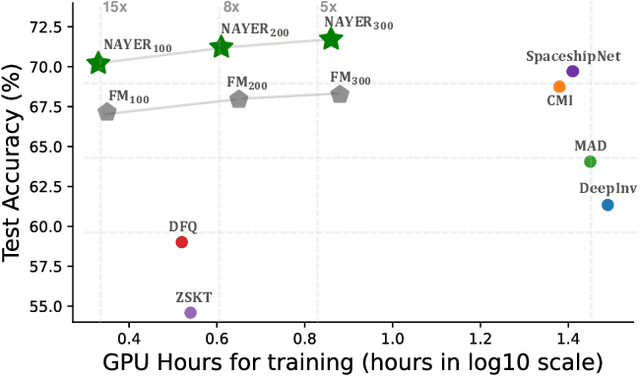
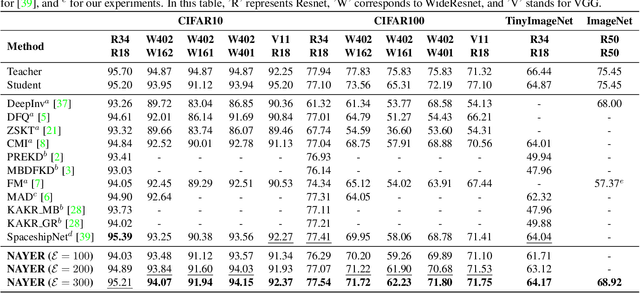


Data-Free Knowledge Distillation (DFKD) has recently made remarkable advancements with its core principle of transferring knowledge from a teacher neural network to a student neural network without requiring access to the original data. Nonetheless, existing approaches encounter a significant challenge when attempting to generate samples from random noise inputs, which inherently lack meaningful information. Consequently, these models struggle to effectively map this noise to the ground-truth sample distribution, resulting in the production of low-quality data and imposing substantial time requirements for training the generator. In this paper, we propose a novel Noisy Layer Generation method (NAYER) which relocates the randomness source from the input to a noisy layer and utilizes the meaningful label-text embedding (LTE) as the input. The significance of LTE lies in its ability to contain substantial meaningful inter-class information, enabling the generation of high-quality samples with only a few training steps. Simultaneously, the noisy layer plays a key role in addressing the issue of diversity in sample generation by preventing the model from overemphasizing the constrained label information. By reinitializing the noisy layer in each iteration, we aim to facilitate the generation of diverse samples while still retaining the method's efficiency, thanks to the ease of learning provided by LTE. Experiments carried out on multiple datasets demonstrate that our NAYER not only outperforms the state-of-the-art methods but also achieves speeds 5 to 15 times faster than previous approaches.