 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFastDiSS: Few-step Match Many-step Diffusion Language Model on Sequence-to-Sequence Generation--Full Version
Apr 07, 2026Self-conditioning has been central to the success of continuous diffusion language models, as it allows models to correct previous errors. Yet its ability degrades precisely in the regime where diffusion is most attractive for deployment: few-step sampling for fast inference. In this study, we show that when models only have a few denoising steps, inaccurate self-conditioning induces a substantial approximation gap; this mistake compounds across denoising steps and ultimately dominate the sample quality. To address this, we propose a novel training framework that handles these errors during learning by perturbing the self-conditioning signal to match inference noise, improving robustness to prior estimation errors. In addition, we introduce a token-level noise-awareness mechanism that prevents training from saturation, hence improving optimization. Extensive experiments across conditional generation benchmarks demonstrate that our framework surpasses standard continuous diffusion models while providing up to 400x faster inference speed, and remains competitive against other one-step diffusion frameworks.
Beyond Forgetting: Machine Unlearning Elicits Controllable Side Behaviors and Capabilities
Jan 29, 2026We consider representation misdirection (RM), a class of LLM unlearning methods that achieves forgetting by manipulating the forget-representations, that is, latent representations of forget samples. Despite being important, the roles of target vectors used in RM, however, remain underexplored. Here, we approach and revisit RM through the lens of the linear representation hypothesis. Specifically, if one can somehow identify a one-dimensional representation corresponding to a high-level concept, the linear representation hypothesis enables linear operations on this concept vector within the forget-representation space. Under this view, we hypothesize that, beyond forgetting, machine unlearning elicits controllable side behaviors and stronger side capabilities corresponding to the high-level concept. Our hypothesis is empirically validated across a wide range of tasks, including behavioral control (e.g., controlling unlearned models' truth, sentiment, and refusal) and capability enhancement (e.g., improving unlearned models' in-context learning capability). Our findings reveal that this fairly attractive phenomenon could be either a hidden risk if misused or a mechanism that can be harnessed for developing models that require stronger capabilities and controllable behaviors.
Guiding Noisy Label Conditional Diffusion Models with Score-based Discriminator Correction
Aug 27, 2025Diffusion models have gained prominence as state-of-the-art techniques for synthesizing images and videos, particularly due to their ability to scale effectively with large datasets. Recent studies have uncovered that these extensive datasets often contain mistakes from manual labeling processes. However, the extent to which such errors compromise the generative capabilities and controllability of diffusion models is not well studied. This paper introduces Score-based Discriminator Correction (SBDC), a guidance technique for aligning noisy pre-trained conditional diffusion models. The guidance is built on discriminator training using adversarial loss, drawing on prior noise detection techniques to assess the authenticity of each sample. We further show that limiting the usage of our guidance to the early phase of the generation process leads to better performance. Our method is computationally efficient, only marginally increases inference time, and does not require retraining diffusion models. Experiments on different noise settings demonstrate the superiority of our method over previous state-of-the-art methods.
Improving the Robustness of Representation Misdirection for Large Language Model Unlearning
Jan 31, 2025Representation Misdirection (RM) and variants are established large language model (LLM) unlearning methods with state-of-the-art performance. In this paper, we show that RM methods inherently reduce models' robustness, causing them to misbehave even when a single non-adversarial forget-token is in the retain-query. Toward understanding underlying causes, we reframe the unlearning process as backdoor attacks and defenses: forget-tokens act as backdoor triggers that, when activated in retain-queries, cause disruptions in RM models' behaviors, similar to successful backdoor attacks. To mitigate this vulnerability, we propose Random Noise Augmentation -- a model and method agnostic approach with theoretical guarantees for improving the robustness of RM methods. Extensive experiments demonstrate that RNA significantly improves the robustness of RM models while enhancing the unlearning performances.
On Effects of Steering Latent Representation for Large Language Model Unlearning
Aug 12, 2024



Representation Misdirection for Unlearning (RMU), which steers model representation in the intermediate layer to a target random representation, is an effective method for large language model (LLM) unlearning. Despite its high performance, the underlying cause and explanation remain underexplored. In this paper, we first theoretically demonstrate that steering forget representations in the intermediate layer reduces token confidence, causing LLMs to generate wrong or nonsense responses. Second, we investigate how the coefficient influences the alignment of forget-sample representations with the random direction and hint at the optimal coefficient values for effective unlearning across different network layers. Third, we show that RMU unlearned models are robust against adversarial jailbreak attacks. Last, our empirical analysis shows that RMU is less effective when applied to the middle and later layers in LLMs. To resolve this drawback, we propose Adaptive RMU -- a simple yet effective alternative method that makes unlearning effective with most layers. Extensive experiments demonstrate that Adaptive RMU significantly improves the unlearning performance compared to prior art while incurring no additional computational cost.
Wicked Oddities: Selectively Poisoning for Effective Clean-Label Backdoor Attacks
Jul 16, 2024
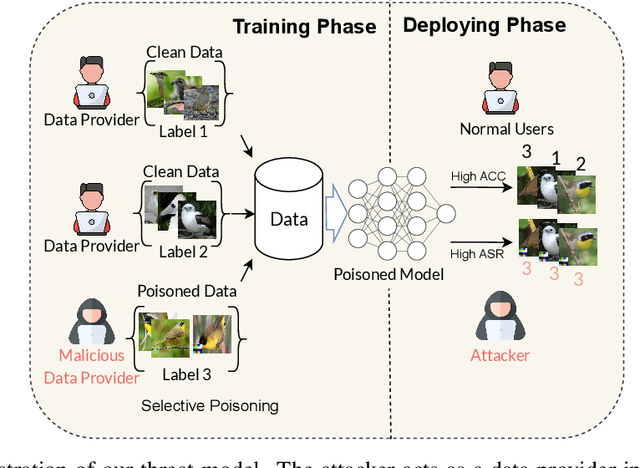
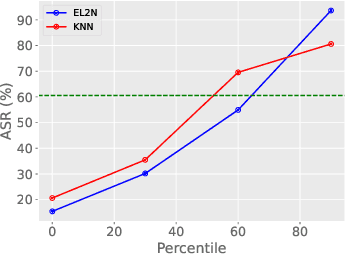
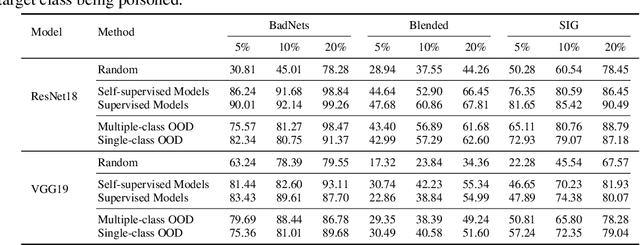
Deep neural networks are vulnerable to backdoor attacks, a type of adversarial attack that poisons the training data to manipulate the behavior of models trained on such data. Clean-label attacks are a more stealthy form of backdoor attacks that can perform the attack without changing the labels of poisoned data. Early works on clean-label attacks added triggers to a random subset of the training set, ignoring the fact that samples contribute unequally to the attack's success. This results in high poisoning rates and low attack success rates. To alleviate the problem, several supervised learning-based sample selection strategies have been proposed. However, these methods assume access to the entire labeled training set and require training, which is expensive and may not always be practical. This work studies a new and more practical (but also more challenging) threat model where the attacker only provides data for the target class (e.g., in face recognition systems) and has no knowledge of the victim model or any other classes in the training set. We study different strategies for selectively poisoning a small set of training samples in the target class to boost the attack success rate in this setting. Our threat model poses a serious threat in training machine learning models with third-party datasets, since the attack can be performed effectively with limited information. Experiments on benchmark datasets illustrate the effectiveness of our strategies in improving clean-label backdoor attacks.
A Cosine Similarity-based Method for Out-of-Distribution Detection
Jun 23, 2023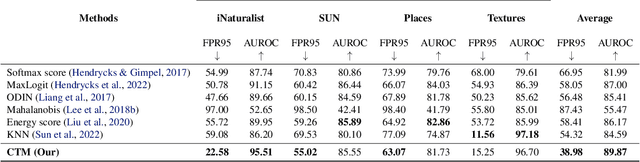
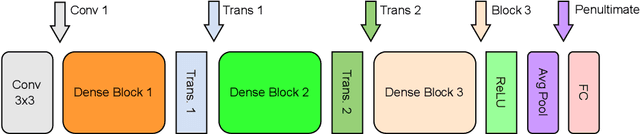

The ability to detect OOD data is a crucial aspect of practical machine learning applications. In this work, we show that cosine similarity between the test feature and the typical ID feature is a good indicator of OOD data. We propose Class Typical Matching (CTM), a post hoc OOD detection algorithm that uses a cosine similarity scoring function. Extensive experiments on multiple benchmarks show that CTM outperforms existing post hoc OOD detection methods.
Class based Influence Functions for Error Detection
May 02, 2023


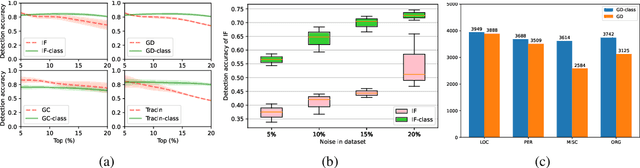
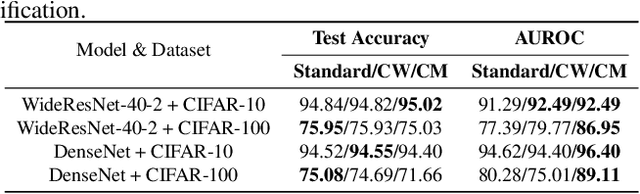
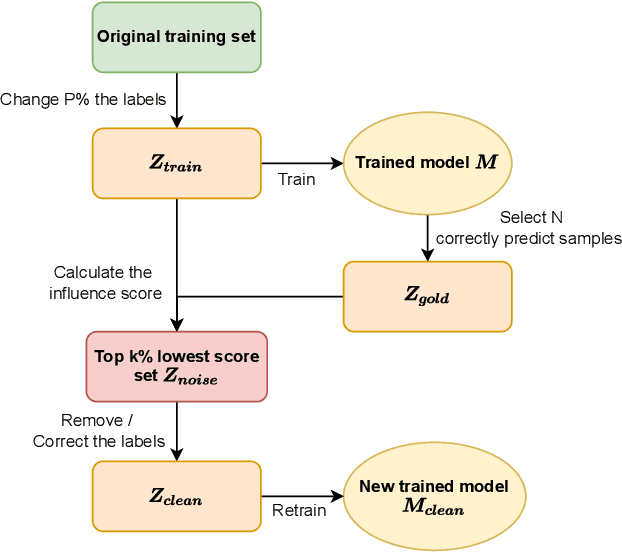
Influence functions (IFs) are a powerful tool for detecting anomalous examples in large scale datasets. However, they are unstable when applied to deep networks. In this paper, we provide an explanation for the instability of IFs and develop a solution to this problem. We show that IFs are unreliable when the two data points belong to two different classes. Our solution leverages class information to improve the stability of IFs. Extensive experiments show that our modification significantly improves the performance and stability of IFs while incurring no additional computational cost.
Towards Using Data-Centric Approach for Better Code Representation Learning
May 25, 2022
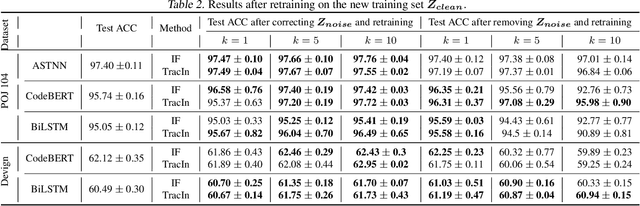
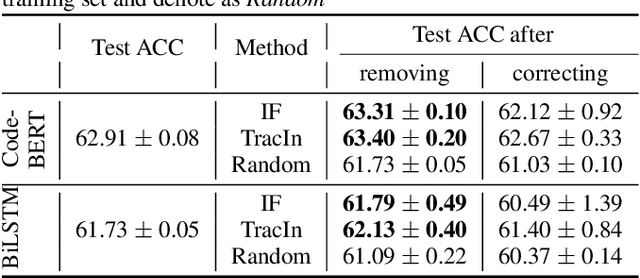
Despite the recent trend of creating source code models and applying them to software engineering tasks, the quality of such models is insufficient for real-world application. In this work, we focus on improving existing code learning models from the data-centric perspective instead of designing new source code models. We shed some light on this direction by using a so-called data-influence method to identify noisy samples of pre-trained code learning models. The data-influence method is to assess the similarity of a target sample to the correct samples to determine whether or not such the target sample is noisy. The results of our evaluation show that data-influence methods can identify noisy samples for the code classification and defection prediction tasks. We envision that the data-centric approach will be a key driver for developing source code models that are useful in practice.
Toward a Generalization Metric for Deep Generative Models
Nov 02, 2020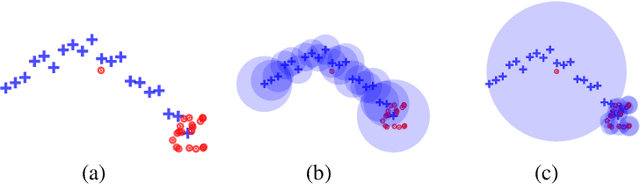

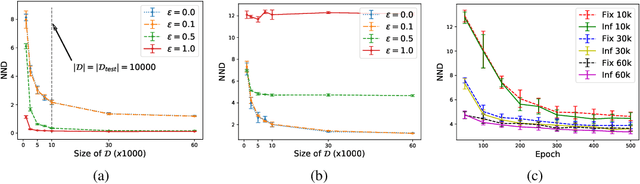

Measuring the generalization capacity of Deep Generative Models (DGMs) is difficult because of the curse of dimensionality. Evaluation metrics for DGMs like Inception Score, Frechet Inception Distance, Precision-Recall, and Neural Net Divergence try to estimate the distance between the generated distribution and the target distribution using a polynomial number of samples. These metrics are the target of researchers when designing new models. Despite the claims, it is still unclear how well they can measure the generalization capacity of a model. In this paper, we investigate the capacity of these metrics in measuring the generalization capacity. We introduce a framework for comparing the robustness of evaluation metrics. We show that better scores in these metrics do not imply better generalization. They can be fooled easily by a generator that memorizes a small subset of the training set. We propose a fix to the NND metric to make it more robust to noise in the generated data.