 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward a Generalization Metric for Deep Generative Models
Paper and Code
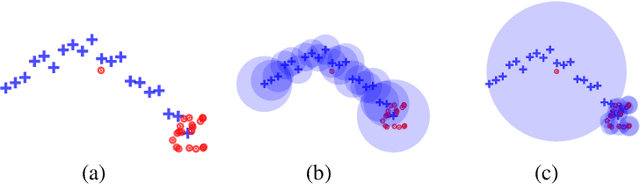

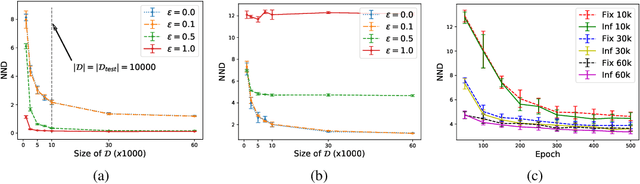

Measuring the generalization capacity of Deep Generative Models (DGMs) is difficult because of the curse of dimensionality. Evaluation metrics for DGMs like Inception Score, Frechet Inception Distance, Precision-Recall, and Neural Net Divergence try to estimate the distance between the generated distribution and the target distribution using a polynomial number of samples. These metrics are the target of researchers when designing new models. Despite the claims, it is still unclear how well they can measure the generalization capacity of a model. In this paper, we investigate the capacity of these metrics in measuring the generalization capacity. We introduce a framework for comparing the robustness of evaluation metrics. We show that better scores in these metrics do not imply better generalization. They can be fooled easily by a generator that memorizes a small subset of the training set. We propose a fix to the NND metric to make it more robust to noise in the generated data.