 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoding the Critique Mechanism in Large Reasoning Models
Mar 17, 2026Large Reasoning Models (LRMs) exhibit backtracking and self-verification mechanisms that enable them to revise intermediate steps and reach correct solutions, yielding strong performance on complex logical benchmarks. We hypothesize that such behaviors are beneficial only when the model has sufficiently strong "critique" ability to detect its own mistakes. This work systematically investigates how current LRMs recover from errors by inserting arithmetic mistakes in their intermediate reasoning steps. Notably, we discover a peculiar yet important phenomenon: despite the error propagating through the chain-of-thought (CoT), resulting in an incorrect intermediate conclusion, the model still reaches the correct final answer. This recovery implies that the model must possess an internal mechanism to detect errors and trigger self-correction, which we refer to as the hidden critique ability. Building on feature space analysis, we identify a highly interpretable critique vector representing this behavior. Extensive experiments across multiple model scales and families demonstrate that steering latent representations with this vector improves the model's error detection capability and enhances the performance of test-time scaling at no extra training cost. Our findings provide a valuable understanding of LRMs' critique behavior, suggesting a promising direction to control and improve their self-verification mechanism. Our code is available at https://github.com/mail-research/lrm-critique-vectors.
Unveiling Concept Attribution in Diffusion Models
Dec 03, 2024



Diffusion models have shown remarkable abilities in generating realistic and high-quality images from text prompts. However, a trained model remains black-box; little do we know about the role of its components in exhibiting a concept such as objects or styles. Recent works employ causal tracing to localize layers storing knowledge in generative models without showing how those layers contribute to the target concept. In this work, we approach the model interpretability problem from a more general perspective and pose a question: \textit{``How do model components work jointly to demonstrate knowledge?''}. We adapt component attribution to decompose diffusion models, unveiling how a component contributes to a concept. Our framework allows effective model editing, in particular, we can erase a concept from diffusion models by removing positive components while remaining knowledge of other concepts. Surprisingly, we also show there exist components that contribute negatively to a concept, which has not been discovered in the knowledge localization approach. Experimental results confirm the role of positive and negative components pinpointed by our framework, depicting a complete view of interpreting generative models. Our code is available at \url{https://github.com/mail-research/CAD-attribution4diffusion}
Wicked Oddities: Selectively Poisoning for Effective Clean-Label Backdoor Attacks
Jul 16, 2024
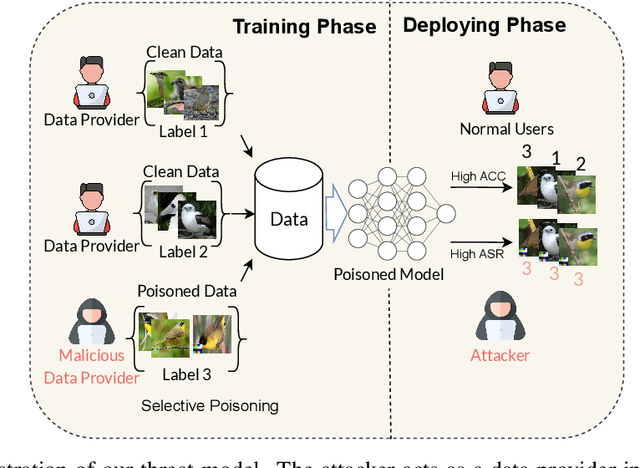
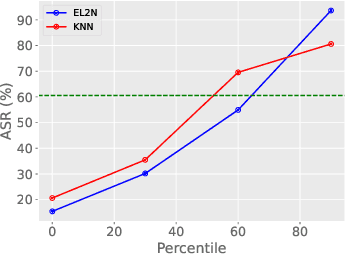
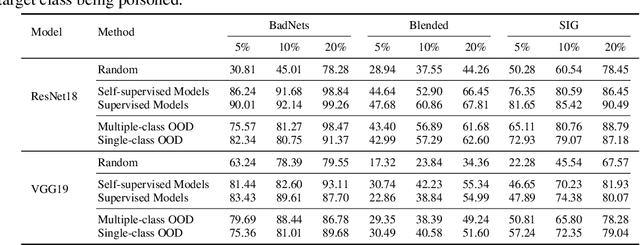
Deep neural networks are vulnerable to backdoor attacks, a type of adversarial attack that poisons the training data to manipulate the behavior of models trained on such data. Clean-label attacks are a more stealthy form of backdoor attacks that can perform the attack without changing the labels of poisoned data. Early works on clean-label attacks added triggers to a random subset of the training set, ignoring the fact that samples contribute unequally to the attack's success. This results in high poisoning rates and low attack success rates. To alleviate the problem, several supervised learning-based sample selection strategies have been proposed. However, these methods assume access to the entire labeled training set and require training, which is expensive and may not always be practical. This work studies a new and more practical (but also more challenging) threat model where the attacker only provides data for the target class (e.g., in face recognition systems) and has no knowledge of the victim model or any other classes in the training set. We study different strategies for selectively poisoning a small set of training samples in the target class to boost the attack success rate in this setting. Our threat model poses a serious threat in training machine learning models with third-party datasets, since the attack can be performed effectively with limited information. Experiments on benchmark datasets illustrate the effectiveness of our strategies in improving clean-label backdoor attacks.
MetaLLM: A High-performant and Cost-efficient Dynamic Framework for Wrapping LLMs
Jul 15, 2024The rapid progress in machine learning (ML) has brought forth many large language models (LLMs) that excel in various tasks and areas. These LLMs come with different abilities and costs in terms of computation or pricing. Since the demand for each query can vary, e.g., because of the queried domain or its complexity, defaulting to one LLM in an application is not usually the best choice, whether it is the biggest, priciest, or even the one with the best average test performance. Consequently, picking the right LLM that is both accurate and cost-effective for an application remains a challenge. In this paper, we introduce MetaLLM, a framework that dynamically and intelligently routes each query to the optimal LLM (among several available LLMs) for classification tasks, achieving significantly improved accuracy and cost-effectiveness. By framing the selection problem as a multi-armed bandit, MetaLLM balances prediction accuracy and cost efficiency under uncertainty. Our experiments, conducted on popular LLM platforms such as OpenAI's GPT models, Amazon's Titan, Anthropic's Claude, and Meta's LLaMa, showcase MetaLLM's efficacy in real-world scenarios, laying the groundwork for future extensions beyond classification tasks.
Fooling the Textual Fooler via Randomizing Latent Representations
Oct 02, 2023
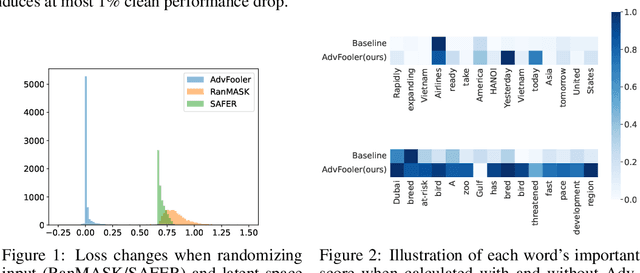
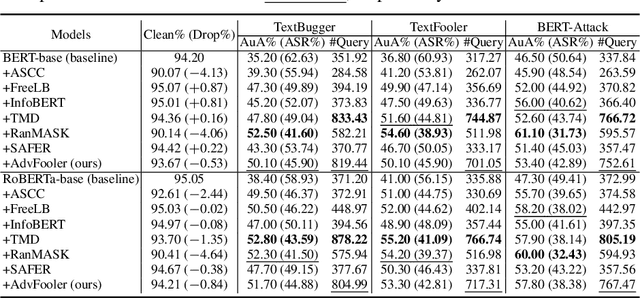
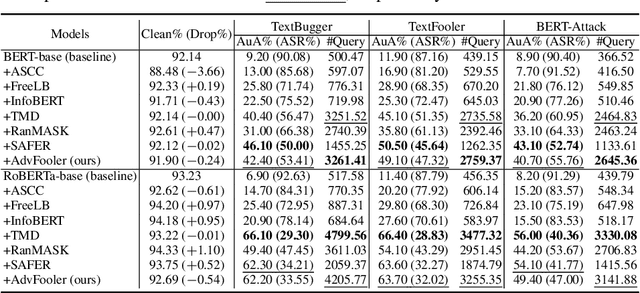
Despite outstanding performance in a variety of NLP tasks, recent studies have revealed that NLP models are vulnerable to adversarial attacks that slightly perturb the input to cause the models to misbehave. Among these attacks, adversarial word-level perturbations are well-studied and effective attack strategies. Since these attacks work in black-box settings, they do not require access to the model architecture or model parameters and thus can be detrimental to existing NLP applications. To perform an attack, the adversary queries the victim model many times to determine the most important words in an input text and to replace these words with their corresponding synonyms. In this work, we propose a lightweight and attack-agnostic defense whose main goal is to perplex the process of generating an adversarial example in these query-based black-box attacks; that is to fool the textual fooler. This defense, named AdvFooler, works by randomizing the latent representation of the input at inference time. Different from existing defenses, AdvFooler does not necessitate additional computational overhead during training nor relies on assumptions about the potential adversarial perturbation set while having a negligible impact on the model's accuracy. Our theoretical and empirical analyses highlight the significance of robustness resulting from confusing the adversary via randomizing the latent space, as well as the impact of randomization on clean accuracy. Finally, we empirically demonstrate near state-of-the-art robustness of AdvFooler against representative adversarial word-level attacks on two benchmark datasets.
Understanding the Robustness of Randomized Feature Defense Against Query-Based Adversarial Attacks
Oct 01, 2023Recent works have shown that deep neural networks are vulnerable to adversarial examples that find samples close to the original image but can make the model misclassify. Even with access only to the model's output, an attacker can employ black-box attacks to generate such adversarial examples. In this work, we propose a simple and lightweight defense against black-box attacks by adding random noise to hidden features at intermediate layers of the model at inference time. Our theoretical analysis confirms that this method effectively enhances the model's resilience against both score-based and decision-based black-box attacks. Importantly, our defense does not necessitate adversarial training and has minimal impact on accuracy, rendering it applicable to any pre-trained model. Our analysis also reveals the significance of selectively adding noise to different parts of the model based on the gradient of the adversarial objective function, which can be varied during the attack. We demonstrate the robustness of our defense against multiple black-box attacks through extensive empirical experiments involving diverse models with various architectures.