 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Makes Large Language Models Reason in (Multi-Turn) Code Generation?
Oct 10, 2024



Prompting techniques such as chain-of-thought have established themselves as a popular vehicle for improving the outputs of large language models (LLMs). For code generation, however, their exact mechanics and efficacy are under-explored. We thus investigate the effects of a wide range of prompting strategies with a focus on automatic re-prompting over multiple turns and computational requirements. After systematically decomposing reasoning, instruction, and execution feedback prompts, we conduct an extensive grid search on the competitive programming benchmarks CodeContests and TACO for multiple LLM families and sizes (Llama 3.0 and 3.1, 8B, 70B, 405B, and GPT-4o). Our study reveals strategies that consistently improve performance across all models with small and large sampling budgets. We then show how finetuning with such an optimal configuration allows models to internalize the induced reasoning process and obtain improvements in performance and scalability for multi-turn code generation.
The Extrapolation Power of Implicit Models
Jul 19, 2024

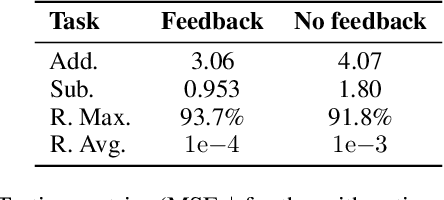
In this paper, we investigate the extrapolation capabilities of implicit deep learning models in handling unobserved data, where traditional deep neural networks may falter. Implicit models, distinguished by their adaptability in layer depth and incorporation of feedback within their computational graph, are put to the test across various extrapolation scenarios: out-of-distribution, geographical, and temporal shifts. Our experiments consistently demonstrate significant performance advantage with implicit models. Unlike their non-implicit counterparts, which often rely on meticulous architectural design for each task, implicit models demonstrate the ability to learn complex model structures without the need for task-specific design, highlighting their robustness in handling unseen data.
MetaLLM: A High-performant and Cost-efficient Dynamic Framework for Wrapping LLMs
Jul 15, 2024The rapid progress in machine learning (ML) has brought forth many large language models (LLMs) that excel in various tasks and areas. These LLMs come with different abilities and costs in terms of computation or pricing. Since the demand for each query can vary, e.g., because of the queried domain or its complexity, defaulting to one LLM in an application is not usually the best choice, whether it is the biggest, priciest, or even the one with the best average test performance. Consequently, picking the right LLM that is both accurate and cost-effective for an application remains a challenge. In this paper, we introduce MetaLLM, a framework that dynamically and intelligently routes each query to the optimal LLM (among several available LLMs) for classification tasks, achieving significantly improved accuracy and cost-effectiveness. By framing the selection problem as a multi-armed bandit, MetaLLM balances prediction accuracy and cost efficiency under uncertainty. Our experiments, conducted on popular LLM platforms such as OpenAI's GPT models, Amazon's Titan, Anthropic's Claude, and Meta's LLaMa, showcase MetaLLM's efficacy in real-world scenarios, laying the groundwork for future extensions beyond classification tasks.
State-driven Implicit Modeling for Sparsity and Robustness in Neural Networks
Sep 19, 2022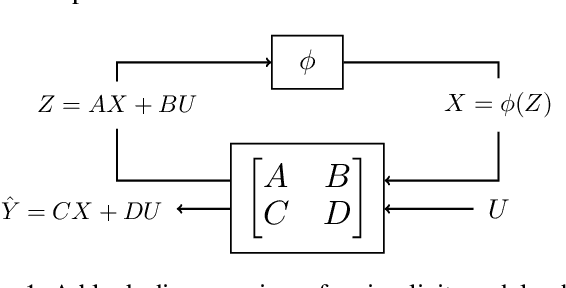
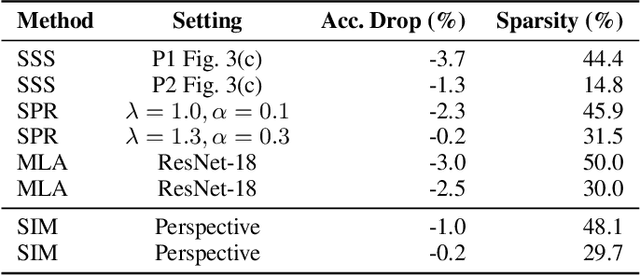
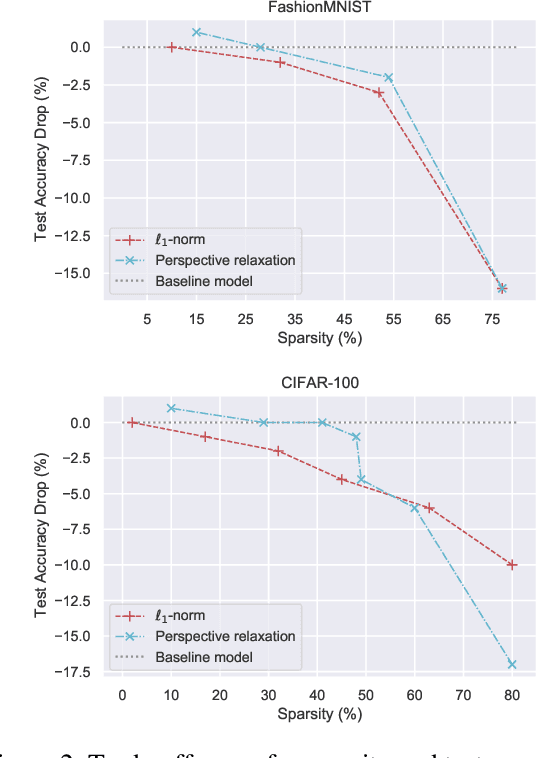
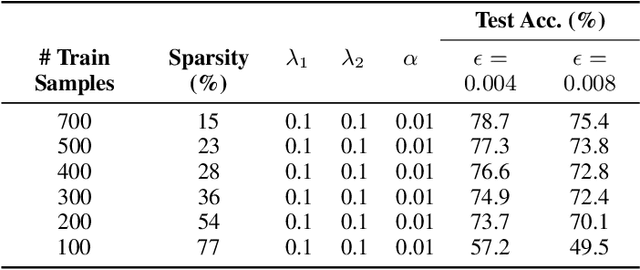
Implicit models are a general class of learning models that forgo the hierarchical layer structure typical in neural networks and instead define the internal states based on an ``equilibrium'' equation, offering competitive performance and reduced memory consumption. However, training such models usually relies on expensive implicit differentiation for backward propagation. In this work, we present a new approach to training implicit models, called State-driven Implicit Modeling (SIM), where we constrain the internal states and outputs to match that of a baseline model, circumventing costly backward computations. The training problem becomes convex by construction and can be solved in a parallel fashion, thanks to its decomposable structure. We demonstrate how the SIM approach can be applied to significantly improve sparsity (parameter reduction) and robustness of baseline models trained on FashionMNIST and CIFAR-100 datasets.