 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtrapolative Weight Averaging Reveals Correctness-Efficiency Frontiers in Code RL
May 27, 2026Linear interpolation between fine-tuned checkpoints has been shown to trace the Pareto front between competing objectives, but whether extrapolative weight averaging can extend such frontiers to new checkpoints useful at inference time, without additional RL training, remains unclear. We study this question in RL for competitive programming, where hidden unit tests under time and memory limits enforce both functional correctness and computational efficiency. Starting from a shared initialization, we train checkpoints under nested unit-test coverage: low-coverage rewards require passing smaller-input tests, while high-coverage rewards require passing progressively larger tests up to the full suite. This sweep reveals the emergence of a correctness-efficiency frontier: on hard problems, higher-coverage reward reduces optimization failures but increases correctness failures, leaving solve rate nearly unchanged. Interpolation between low- and high-coverage checkpoints recovers this frontier, while extrapolation extends it beyond the trained endpoints. Both the frontier and its extrapolative continuation appear across three inference settings, pure reasoning, tool use, and agentic coding, and across two model scales, 32B and 7B. At the problem level, moving along the frontier changes which problems are solved, making extrapolated checkpoints complementary policies in inference-time scaling. Ensembles with extrapolative weight averaging broaden coverage and improve pass@250 on LCB/hard by 3.3% over the best single checkpoint at matched sample budget. These results show that nested unit-test coverage in code RL induces a frontier that extrapolative weight averaging can navigate, extend, and exploit.
Beyond pass@k: Redundancy-Aware RLVR for Multi-Sample Code Generation
May 27, 2026LLMs for code generation are commonly evaluated in repeated-sampling settings using Pass@k, where multiple candidate programs are executed against unit tests under a finite sampling budget. While recent verifier-based reinforcement learning (RLVR) methods improve executable correctness, how these objectives affect redundancy among sampled programs remains poorly understood. In this work, we study implementation-level redundancy in code generation using JPlag, a plagiarism-detection system for code. Across models and benchmarks, we show that correctness-only RLVR often concentrates generations around repeated implementations, whereas Pass@k-aware objectives maintain lower redundancy and improve larger-budget performance. Motivated by these observations, we augment RLVR with direct anti-redundancy rewards based on JPlag similarity. Across 3 models and 3 benchmarks, discouraging near-duplicate generations reliably improves finite-budget executable performance, often matching or outperforming specialized Pass@k-aware objectives.
Lattice Climber Attack: Adversarial attacks for randomized mixtures of classifiers
Jun 12, 2025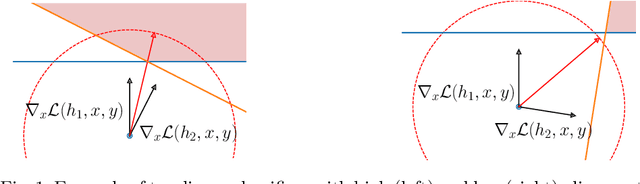
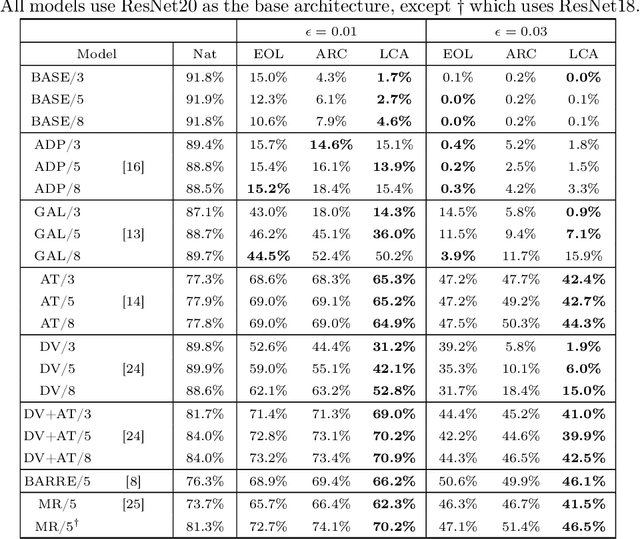
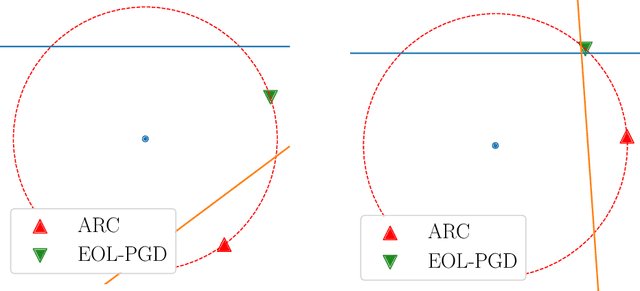
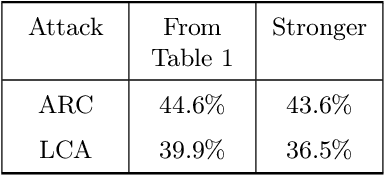
Finite mixtures of classifiers (a.k.a. randomized ensembles) have been proposed as a way to improve robustness against adversarial attacks. However, existing attacks have been shown to not suit this kind of classifier. In this paper, we discuss the problem of attacking a mixture in a principled way and introduce two desirable properties of attacks based on a geometrical analysis of the problem (effectiveness and maximality). We then show that existing attacks do not meet both of these properties. Finally, we introduce a new attack called {\em lattice climber attack} with theoretical guarantees in the binary linear setting, and demonstrate its performance by conducting experiments on synthetic and real datasets.
Monte Carlo Graph Coloring
Apr 04, 2025Graph Coloring is probably one of the most studied and famous problem in graph algorithms. Exact methods fail to solve instances with more than few hundred vertices, therefore, a large number of heuristics have been proposed. Nested Monte Carlo Search (NMCS) and Nested Rollout Policy Adaptation (NRPA) are Monte Carlo search algorithms for single player games. Surprisingly, few work has been dedicated to evaluating Monte Carlo search algorithms to combinatorial graph problems. In this paper we expose how to efficiently apply Monte Carlo search to Graph Coloring and compare this approach to existing ones.
Improving Discriminator Guidance in Diffusion Models
Mar 20, 2025Discriminator Guidance has become a popular method for efficiently refining pre-trained Score-Matching Diffusion models. However, in this paper, we demonstrate that the standard implementation of this technique does not necessarily lead to a distribution closer to the real data distribution. Specifically, we show that training the discriminator using Cross-Entropy loss, as commonly done, can in fact increase the Kullback-Leibler divergence between the model and target distributions, particularly when the discriminator overfits. To address this, we propose a theoretically sound training objective for discriminator guidance that properly minimizes the KL divergence. We analyze its properties and demonstrate empirically across multiple datasets that our proposed method consistently improves over the conventional method by producing samples of higher quality.
Unveiling the Role of Randomization in Multiclass Adversarial Classification: Insights from Graph Theory
Mar 18, 2025



Randomization as a mean to improve the adversarial robustness of machine learning models has recently attracted significant attention. Unfortunately, much of the theoretical analysis so far has focused on binary classification, providing only limited insights into the more complex multiclass setting. In this paper, we take a step toward closing this gap by drawing inspiration from the field of graph theory. Our analysis focuses on discrete data distributions, allowing us to cast the adversarial risk minimization problems within the well-established framework of set packing problems. By doing so, we are able to identify three structural conditions on the support of the data distribution that are necessary for randomization to improve robustness. Furthermore, we are able to construct several data distributions where (contrarily to binary classification) switching from a deterministic to a randomized solution significantly reduces the optimal adversarial risk. These findings highlight the crucial role randomization can play in enhancing robustness to adversarial attacks in multiclass classification.
What Makes Large Language Models Reason in (Multi-Turn) Code Generation?
Oct 10, 2024



Prompting techniques such as chain-of-thought have established themselves as a popular vehicle for improving the outputs of large language models (LLMs). For code generation, however, their exact mechanics and efficacy are under-explored. We thus investigate the effects of a wide range of prompting strategies with a focus on automatic re-prompting over multiple turns and computational requirements. After systematically decomposing reasoning, instruction, and execution feedback prompts, we conduct an extensive grid search on the competitive programming benchmarks CodeContests and TACO for multiple LLM families and sizes (Llama 3.0 and 3.1, 8B, 70B, 405B, and GPT-4o). Our study reveals strategies that consistently improve performance across all models with small and large sampling budgets. We then show how finetuning with such an optimal configuration allows models to internalize the induced reasoning process and obtain improvements in performance and scalability for multi-turn code generation.
Exploring Precision and Recall to assess the quality and diversity of LLMs
Feb 28, 2024



This paper introduces a novel evaluation framework for Large Language Models (LLMs) such as Llama-2 and Mistral, focusing on the adaptation of Precision and Recall metrics from image generation to text generation. This approach allows for a nuanced assessment of the quality and diversity of generated text without the need for aligned corpora. By conducting a comprehensive evaluation of state-of-the-art language models, the study reveals significant insights into their performance on open-ended generation tasks, which are not adequately captured by traditional benchmarks. The findings highlight a trade-off between the quality and diversity of generated samples, particularly when models are fine-tuned with human feedback. This work extends the toolkit for distribution-based NLP evaluation, offering insights into the practical capabilities and challenges faced by current LLMs in generating diverse and high-quality text.
Optimal Budgeted Rejection Sampling for Generative Models
Nov 01, 2023



Rejection sampling methods have recently been proposed to improve the performance of discriminator-based generative models. However, these methods are only optimal under an unlimited sampling budget, and are usually applied to a generator trained independently of the rejection procedure. We first propose an Optimal Budgeted Rejection Sampling (OBRS) scheme that is provably optimal with respect to \textit{any} $f$-divergence between the true distribution and the post-rejection distribution, for a given sampling budget. Second, we propose an end-to-end method that incorporates the sampling scheme into the training procedure to further enhance the model's overall performance. Through experiments and supporting theory, we show that the proposed methods are effective in significantly improving the quality and diversity of the samples.
Adversarial attacks for mixtures of classifiers
Jul 20, 2023



Mixtures of classifiers (a.k.a. randomized ensembles) have been proposed as a way to improve robustness against adversarial attacks. However, it has been shown that existing attacks are not well suited for this kind of classifiers. In this paper, we discuss the problem of attacking a mixture in a principled way and introduce two desirable properties of attacks based on a geometrical analysis of the problem (effectiveness and maximality). We then show that existing attacks do not meet both of these properties. Finally, we introduce a new attack called lattice climber attack with theoretical guarantees on the binary linear setting, and we demonstrate its performance by conducting experiments on synthetic and real datasets.