 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeByzFL: Research Framework for Robust Federated Learning
May 30, 2025We present ByzFL, an open-source Python library for developing and benchmarking robust federated learning (FL) algorithms. ByzFL provides a unified and extensible framework that includes implementations of state-of-the-art robust aggregators, a suite of configurable attacks, and tools for simulating a variety of FL scenarios, including heterogeneous data distributions, multiple training algorithms, and adversarial threat models. The library enables systematic experimentation via a single JSON-based configuration file and includes built-in utilities for result visualization. Compatible with PyTorch tensors and NumPy arrays, ByzFL is designed to facilitate reproducible research and rapid prototyping of robust FL solutions. ByzFL is available at https://byzfl.epfl.ch/, with source code hosted on GitHub: https://github.com/LPD-EPFL/byzfl.
Unveiling the Role of Randomization in Multiclass Adversarial Classification: Insights from Graph Theory
Mar 18, 2025Randomization as a mean to improve the adversarial robustness of machine learning models has recently attracted significant attention. Unfortunately, much of the theoretical analysis so far has focused on binary classification, providing only limited insights into the more complex multiclass setting. In this paper, we take a step toward closing this gap by drawing inspiration from the field of graph theory. Our analysis focuses on discrete data distributions, allowing us to cast the adversarial risk minimization problems within the well-established framework of set packing problems. By doing so, we are able to identify three structural conditions on the support of the data distribution that are necessary for randomization to improve robustness. Furthermore, we are able to construct several data distributions where (contrarily to binary classification) switching from a deterministic to a randomized solution significantly reduces the optimal adversarial risk. These findings highlight the crucial role randomization can play in enhancing robustness to adversarial attacks in multiclass classification.
Revisiting Ensembling in One-Shot Federated Learning
Nov 11, 2024
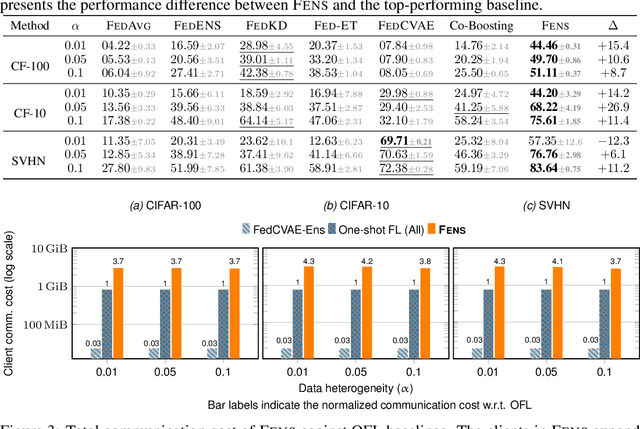
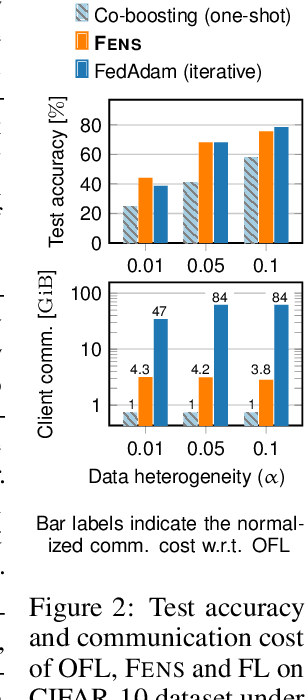

Federated learning (FL) is an appealing approach to training machine learning models without sharing raw data. However, standard FL algorithms are iterative and thus induce a significant communication cost. One-shot federated learning (OFL) trades the iterative exchange of models between clients and the server with a single round of communication, thereby saving substantially on communication costs. Not surprisingly, OFL exhibits a performance gap in terms of accuracy with respect to FL, especially under high data heterogeneity. We introduce FENS, a novel federated ensembling scheme that approaches the accuracy of FL with the communication efficiency of OFL. Learning in FENS proceeds in two phases: first, clients train models locally and send them to the server, similar to OFL; second, clients collaboratively train a lightweight prediction aggregator model using FL. We showcase the effectiveness of FENS through exhaustive experiments spanning several datasets and heterogeneity levels. In the particular case of heterogeneously distributed CIFAR-10 dataset, FENS achieves up to a 26.9% higher accuracy over state-of-the-art (SOTA) OFL, being only 3.1% lower than FL. At the same time, FENS incurs at most 4.3x more communication than OFL, whereas FL is at least 10.9x more communication-intensive than FENS.
Fine-Tuning Personalization in Federated Learning to Mitigate Adversarial Clients
Sep 30, 2024


Federated learning (FL) is an appealing paradigm that allows a group of machines (a.k.a. clients) to learn collectively while keeping their data local. However, due to the heterogeneity between the clients' data distributions, the model obtained through the use of FL algorithms may perform poorly on some client's data. Personalization addresses this issue by enabling each client to have a different model tailored to their own data while simultaneously benefiting from the other clients' data. We consider an FL setting where some clients can be adversarial, and we derive conditions under which full collaboration fails. Specifically, we analyze the generalization performance of an interpolated personalized FL framework in the presence of adversarial clients, and we precisely characterize situations when full collaboration performs strictly worse than fine-tuned personalization. Our analysis determines how much we should scale down the level of collaboration, according to data heterogeneity and the tolerable fraction of adversarial clients. We support our findings with empirical results on mean estimation and binary classification problems, considering synthetic and benchmark image classification datasets.
Overcoming the Challenges of Batch Normalization in Federated Learning
May 23, 2024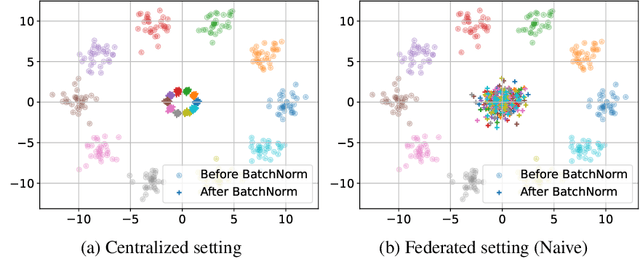
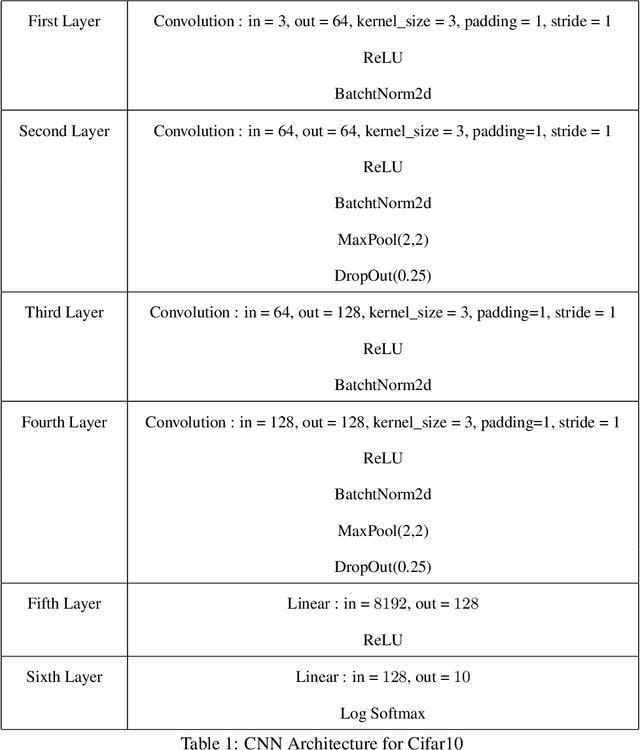
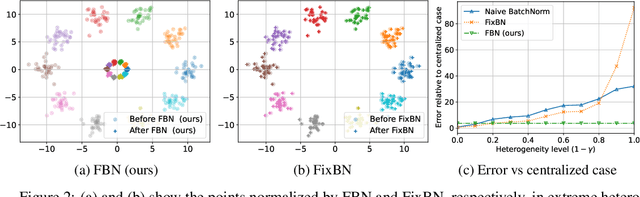
Batch normalization has proven to be a very beneficial mechanism to accelerate the training and improve the accuracy of deep neural networks in centralized environments. Yet, the scheme faces significant challenges in federated learning, especially under high data heterogeneity. Essentially, the main challenges arise from external covariate shifts and inconsistent statistics across clients. We introduce in this paper Federated BatchNorm (FBN), a novel scheme that restores the benefits of batch normalization in federated learning. Essentially, FBN ensures that the batch normalization during training is consistent with what would be achieved in a centralized execution, hence preserving the distribution of the data, and providing running statistics that accurately approximate the global statistics. FBN thereby reduces the external covariate shift and matches the evaluation performance of the centralized setting. We also show that, with a slight increase in complexity, we can robustify FBN to mitigate erroneous statistics and potentially adversarial attacks.
On the Relevance of Byzantine Robust Optimization Against Data Poisoning
May 01, 2024The success of machine learning (ML) has been intimately linked with the availability of large amounts of data, typically collected from heterogeneous sources and processed on vast networks of computing devices (also called {\em workers}). Beyond accuracy, the use of ML in critical domains such as healthcare and autonomous driving calls for robustness against {\em data poisoning}and some {\em faulty workers}. The problem of {\em Byzantine ML} formalizes these robustness issues by considering a distributed ML environment in which workers (storing a portion of the global dataset) can deviate arbitrarily from the prescribed algorithm. Although the problem has attracted a lot of attention from a theoretical point of view, its practical importance for addressing realistic faults (where the behavior of any worker is locally constrained) remains unclear. It has been argued that the seemingly weaker threat model where only workers' local datasets get poisoned is more reasonable. We prove that, while tolerating a wider range of faulty behaviors, Byzantine ML yields solutions that are, in a precise sense, optimal even under the weaker data poisoning threat model. Then, we study a generic data poisoning model wherein some workers have {\em fully-poisonous local data}, i.e., their datasets are entirely corruptible, and the remainders have {\em partially-poisonous local data}, i.e., only a fraction of their local datasets is corruptible. We prove that Byzantine-robust schemes yield optimal solutions against both these forms of data poisoning, and that the former is more harmful when workers have {\em heterogeneous} local data.
Tackling Byzantine Clients in Federated Learning
Feb 20, 2024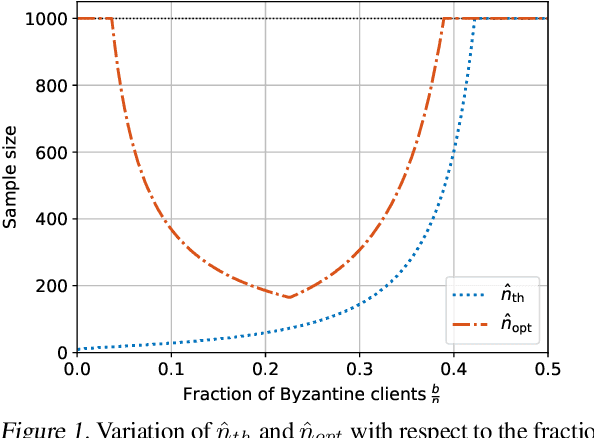
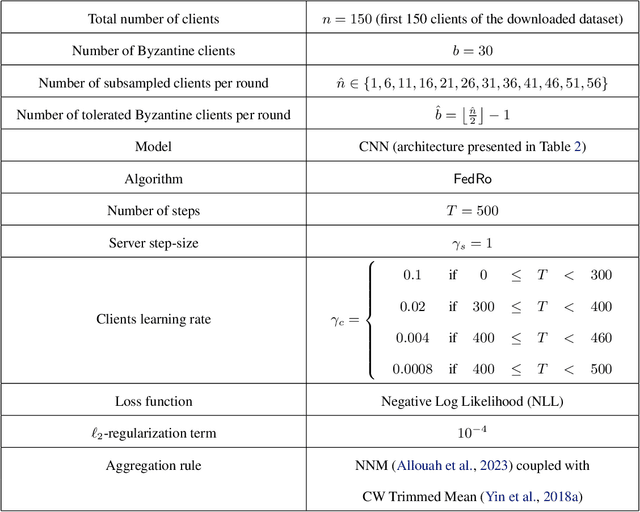
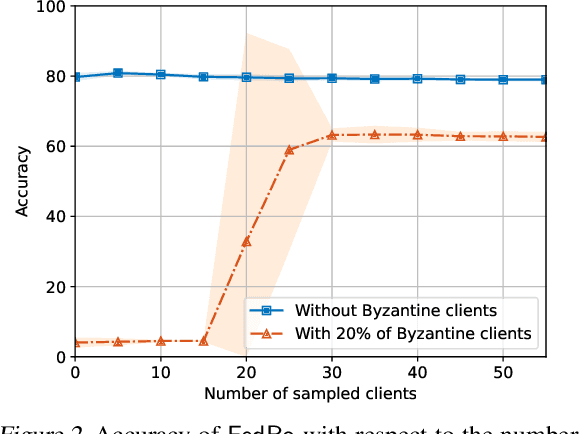
The possibility of adversarial (a.k.a., {\em Byzantine}) clients makes federated learning (FL) prone to arbitrary manipulation. The natural approach to robustify FL against adversarial clients is to replace the simple averaging operation at the server in the standard $\mathsf{FedAvg}$ algorithm by a \emph{robust averaging rule}. While a significant amount of work has been devoted to studying the convergence of federated {\em robust averaging} (which we denote by $\mathsf{FedRo}$), prior work has largely ignored the impact of {\em client subsampling} and {\em local steps}, two fundamental FL characteristics. While client subsampling increases the effective fraction of Byzantine clients, local steps increase the drift between the local updates computed by honest (i.e., non-Byzantine) clients. Consequently, a careless deployment of $\mathsf{FedRo}$ could yield poor performance. We validate this observation by presenting an in-depth analysis of $\mathsf{FedRo}$ tightly analyzing the impact of client subsampling and local steps. Specifically, we present a sufficient condition on client subsampling for nearly-optimal convergence of $\mathsf{FedRo}$ (for smooth non-convex loss). Also, we show that the rate of improvement in learning accuracy {\em diminishes} with respect to the number of clients subsampled, as soon as the sample size exceeds a threshold value. Interestingly, we also observe that under a careful choice of step-sizes, the learning error due to Byzantine clients decreases with the number of local steps. We validate our theory by experiments on the FEMNIST and CIFAR-$10$ image classification tasks.
Practical Homomorphic Aggregation for Byzantine ML
Sep 15, 2023



Due to the large-scale availability of data, machine learning (ML) algorithms are being deployed in distributed topologies, where different nodes collaborate to train ML models over their individual data by exchanging model-related information (e.g., gradients) with a central server. However, distributed learning schemes are notably vulnerable to two threats. First, Byzantine nodes can single-handedly corrupt the learning by sending incorrect information to the server, e.g., erroneous gradients. The standard approach to mitigate such behavior is to use a non-linear robust aggregation method at the server. Second, the server can violate the privacy of the nodes. Recent attacks have shown that exchanging (unencrypted) gradients enables a curious server to recover the totality of the nodes' data. The use of homomorphic encryption (HE), a gold standard security primitive, has extensively been studied as a privacy-preserving solution to distributed learning in non-Byzantine scenarios. However, due to HE's large computational demand especially for high-dimensional ML models, there has not yet been any attempt to design purely homomorphic operators for non-linear robust aggregators. In this work, we present SABLE, the first completely homomorphic and Byzantine robust distributed learning algorithm. SABLE essentially relies on a novel plaintext encoding method that enables us to implement the robust aggregator over batching-friendly BGV. Moreover, this encoding scheme also accelerates state-of-the-art homomorphic sorting with larger security margins and smaller ciphertext size. We perform extensive experiments on image classification tasks and show that our algorithm achieves practical execution times while matching the ML performance of its non-private counterpart.
Distributed Learning with Curious and Adversarial Machines
Feb 09, 2023



The ubiquity of distributed machine learning (ML) in sensitive public domain applications calls for algorithms that protect data privacy, while being robust to faults and adversarial behaviors. Although privacy and robustness have been extensively studied independently in distributed ML, their synthesis remains poorly understood. We present the first tight analysis of the error incurred by any algorithm ensuring robustness against a fraction of adversarial machines, as well as differential privacy (DP) for honest machines' data against any other curious entity. Our analysis exhibits a fundamental trade-off between privacy, robustness, and utility. Surprisingly, we show that the cost of this trade-off is marginal compared to that of the classical privacy-utility trade-off. To prove our lower bound, we consider the case of mean estimation, subject to distributed DP and robustness constraints, and devise reductions to centralized estimation of one-way marginals. We prove our matching upper bound by presenting a new distributed ML algorithm using a high-dimensional robust aggregation rule. The latter amortizes the dependence on the dimension in the error (caused by adversarial workers and DP), while being agnostic to the statistical properties of the data.
Fixing by Mixing: A Recipe for Optimal Byzantine ML under Heterogeneity
Feb 03, 2023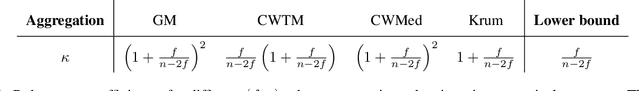
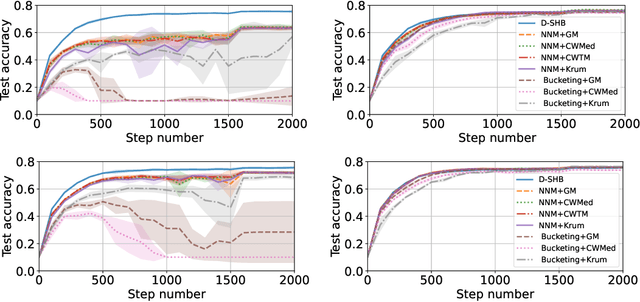
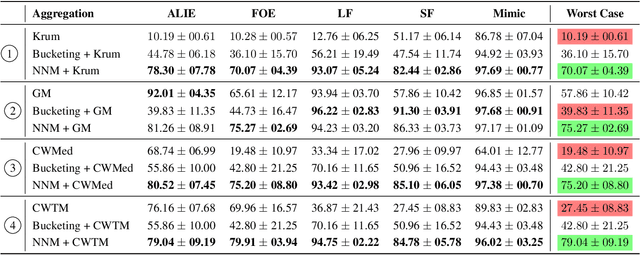
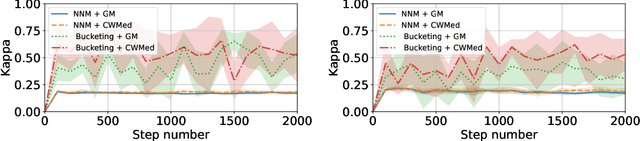
Byzantine machine learning (ML) aims to ensure the resilience of distributed learning algorithms to misbehaving (or Byzantine) machines. Although this problem received significant attention, prior works often assume the data held by the machines to be homogeneous, which is seldom true in practical settings. Data heterogeneity makes Byzantine ML considerably more challenging, since a Byzantine machine can hardly be distinguished from a non-Byzantine outlier. A few solutions have been proposed to tackle this issue, but these provide suboptimal probabilistic guarantees and fare poorly in practice. This paper closes the theoretical gap, achieving optimality and inducing good empirical results. In fact, we show how to automatically adapt existing solutions for (homogeneous) Byzantine ML to the heterogeneous setting through a powerful mechanism, we call nearest neighbor mixing (NNM), which boosts any standard robust distributed gradient descent variant to yield optimal Byzantine resilience under heterogeneity. We obtain similar guarantees (in expectation) by plugging NNM in the distributed stochastic heavy ball method, a practical substitute to distributed gradient descent. We obtain empirical results that significantly outperform state-of-the-art Byzantine ML solutions.