 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePractical Homomorphic Aggregation for Byzantine ML
Sep 15, 2023



Due to the large-scale availability of data, machine learning (ML) algorithms are being deployed in distributed topologies, where different nodes collaborate to train ML models over their individual data by exchanging model-related information (e.g., gradients) with a central server. However, distributed learning schemes are notably vulnerable to two threats. First, Byzantine nodes can single-handedly corrupt the learning by sending incorrect information to the server, e.g., erroneous gradients. The standard approach to mitigate such behavior is to use a non-linear robust aggregation method at the server. Second, the server can violate the privacy of the nodes. Recent attacks have shown that exchanging (unencrypted) gradients enables a curious server to recover the totality of the nodes' data. The use of homomorphic encryption (HE), a gold standard security primitive, has extensively been studied as a privacy-preserving solution to distributed learning in non-Byzantine scenarios. However, due to HE's large computational demand especially for high-dimensional ML models, there has not yet been any attempt to design purely homomorphic operators for non-linear robust aggregators. In this work, we present SABLE, the first completely homomorphic and Byzantine robust distributed learning algorithm. SABLE essentially relies on a novel plaintext encoding method that enables us to implement the robust aggregator over batching-friendly BGV. Moreover, this encoding scheme also accelerates state-of-the-art homomorphic sorting with larger security margins and smaller ciphertext size. We perform extensive experiments on image classification tasks and show that our algorithm achieves practical execution times while matching the ML performance of its non-private counterpart.
When approximate design for fast homomorphic computation provides differential privacy guarantees
Apr 06, 2023While machine learning has become pervasive in as diversified fields as industry, healthcare, social networks, privacy concerns regarding the training data have gained a critical importance. In settings where several parties wish to collaboratively train a common model without jeopardizing their sensitive data, the need for a private training protocol is particularly stringent and implies to protect the data against both the model's end-users and the actors of the training phase. Differential privacy (DP) and cryptographic primitives are complementary popular countermeasures against privacy attacks. Among these cryptographic primitives, fully homomorphic encryption (FHE) offers ciphertext malleability at the cost of time-consuming operations in the homomorphic domain. In this paper, we design SHIELD, a probabilistic approximation algorithm for the argmax operator which is both fast when homomorphically executed and whose inaccuracy is used as a feature to ensure DP guarantees. Even if SHIELD could have other applications, we here focus on one setting and seamlessly integrate it in the SPEED collaborative training framework from "SPEED: Secure, PrivatE, and Efficient Deep learning" (Grivet S\'ebert et al., 2021) to improve its computational efficiency. After thoroughly describing the FHE implementation of our algorithm and its DP analysis, we present experimental results. To the best of our knowledge, it is the first work in which relaxing the accuracy of an homomorphic calculation is constructively usable as a degree of freedom to achieve better FHE performances.
SPEED: Secure, PrivatE, and Efficient Deep learning
Jun 16, 2020

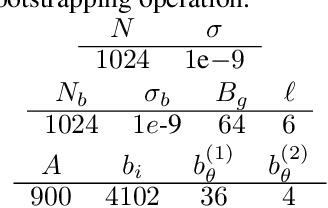
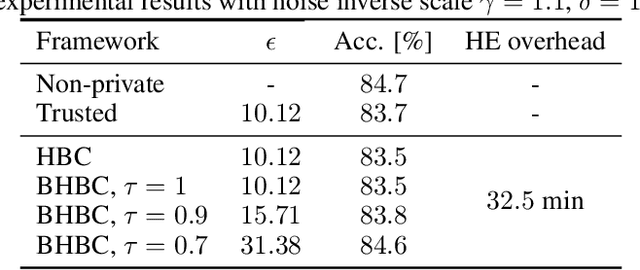
This paper addresses the issue of collaborative deep learning with privacy constraints. Building upon differentially private decentralized semi-supervised learning, we introduce homomorphically encrypted operations to extend the set of threats considered so far. While previous methods relied on the existence of an hypothetical 'trusted' third party, we designed specific aggregation operations in the encrypted domain that allow us to circumvent this assumption. This makes our method practical to real-life scenario where data holders do not trust any third party to process their datasets. Crucially the computational burden of the approach is maintained reasonable, making it suitable to deep learning applications. In order to illustrate the performances of our method, we carried out numerical experiments using image datasets in a classification context.