 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Tuning Personalization in Federated Learning to Mitigate Adversarial Clients
Sep 30, 2024

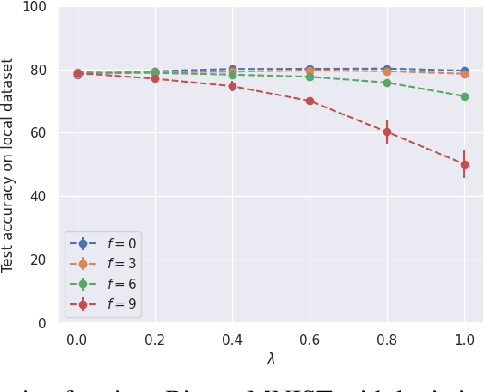

Federated learning (FL) is an appealing paradigm that allows a group of machines (a.k.a. clients) to learn collectively while keeping their data local. However, due to the heterogeneity between the clients' data distributions, the model obtained through the use of FL algorithms may perform poorly on some client's data. Personalization addresses this issue by enabling each client to have a different model tailored to their own data while simultaneously benefiting from the other clients' data. We consider an FL setting where some clients can be adversarial, and we derive conditions under which full collaboration fails. Specifically, we analyze the generalization performance of an interpolated personalized FL framework in the presence of adversarial clients, and we precisely characterize situations when full collaboration performs strictly worse than fine-tuned personalization. Our analysis determines how much we should scale down the level of collaboration, according to data heterogeneity and the tolerable fraction of adversarial clients. We support our findings with empirical results on mean estimation and binary classification problems, considering synthetic and benchmark image classification datasets.
Privacy Attacks in Decentralized Learning
Feb 15, 2024

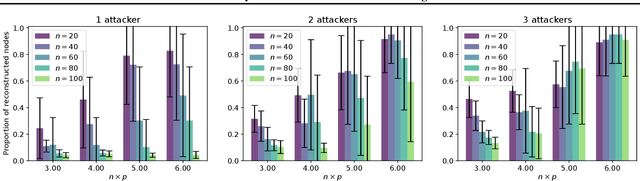
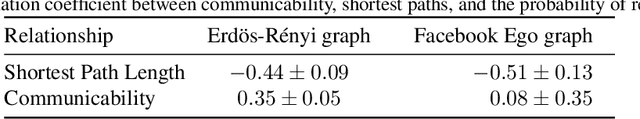
Decentralized Gradient Descent (D-GD) allows a set of users to perform collaborative learning without sharing their data by iteratively averaging local model updates with their neighbors in a network graph. The absence of direct communication between non-neighbor nodes might lead to the belief that users cannot infer precise information about the data of others. In this work, we demonstrate the opposite, by proposing the first attack against D-GD that enables a user (or set of users) to reconstruct the private data of other users outside their immediate neighborhood. Our approach is based on a reconstruction attack against the gossip averaging protocol, which we then extend to handle the additional challenges raised by D-GD. We validate the effectiveness of our attack on real graphs and datasets, showing that the number of users compromised by a single or a handful of attackers is often surprisingly large. We empirically investigate some of the factors that affect the performance of the attack, namely the graph topology, the number of attackers, and their position in the graph.