 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetectability in Diversity: Improved Canary Crafting for Privacy Auditing in One Run
May 26, 2026Privacy auditing aims to empirically assess privacy leakage in machine learning models using membership inference attacks (MIAs), and to derive lower bounds on differential privacy (DP) parameters. Recent one-run auditing methods address the high cost of standard approaches by relying on a single training run with multiple "canary" points whose inclusion or exclusion must be detected by the auditor. In this work, we study the problem of efficiently crafting canaries for one-run privacy auditing. Motivated by recent theoretical insights suggesting that interference between canaries contributes to weaker leakage estimates compared to multi-run methods, we propose to optimize canaries to be both highly detectable and minimally interfering. Our approach combines a greedy initialization based on influence functions with a bilevel optimization procedure that maximizes distinguishability while promoting diversity in embedding space, enabling the use of computationally efficient bilevel algorithms. Experiments show that our method achieves stronger privacy leakage estimates at a lower computational cost than existing canary crafting approaches.
Lumberjack: Better Differentially Private Random Forests through Heavy Hitter Detection in Trees
May 21, 2026Random forests are widely used in fields involving sensitive tabular data, but existing approaches to enforcing differential privacy (DP) typically degrade performance to the point of impracticality. In this paper, we introduce Lumberjack, a differentially private random forest algorithm that achieves substantially higher utility by constructing large random decision trees and then applying aggressive, privacy-preserving pruning to retain only sufficiently populated nodes. A key component of our approach is a novel $(\varepsilon,δ)$-DP heavy hitter detection algorithm for hierarchical data, whose error is $O_{\varepsilon,δ}(\sqrt{\log h})$ for trees of height $h$ and may be of independent interest. This favorable scaling enables the use of significantly deeper trees than in prior work, leading to improved expressiveness under privacy constraints. Our empirical evaluation on benchmark datasets shows that Lumberjack consistently outperforms prior DP random forest methods, establishing a new state of the art. In particular, our approach yields substantial improvements in the privacy-utility trade-off for practical privacy budgets. Our findings suggest that carefully designed DP random forests can close much of the utility gap, highlighting a promising and underexplored direction for future research.
Loss Gap Parity for Fairness in Heterogeneous Federated Learning
Mar 31, 2026While clients may join federated learning to improve performance on data they rarely observe locally, they often remain self-interested, expecting the global model to perform well on their own data. This motivates an objective that ensures all clients achieve a similar loss gap -the difference in performance between the global model and the best model they could train using only their local data-. To this end, we propose EAGLE, a novel federated learning algorithm that explicitly regularizes the global model to minimize disparities in loss gaps across clients. Our approach is particularly effective in heterogeneous settings, where the optimal local models of the clients may be misaligned. Unlike existing methods that encourage loss parity, potentially degrading performance for many clients, EAGLE targets fairness in relative improvements. We provide theoretical convergence guarantees for EAGLE under non-convex loss functions, and characterize how its iterates perform relative to the standard federated learning objective using a novel heterogeneity measure. Empirically, we demonstrate that EAGLE reduces the disparity in loss gaps among clients by prioritizing those furthest from their local optimal loss, while maintaining competitive utility in both convex and non-convex cases compared to strong baselines.
On Gossip Algorithms for Machine Learning with Pairwise Objectives
Mar 25, 2026In the IoT era, information is more and more frequently picked up by connected smart sensors with increasing, though limited, storage, communication and computation abilities. Whether due to privacy constraints or to the structure of the distributed system, the development of statistical learning methods dedicated to data that are shared over a network is now a major issue. Gossip-based algorithms have been developed for the purpose of solving a wide variety of statistical learning tasks, ranging from data aggregation over sensor networks to decentralized multi-agent optimization. Whereas the vast majority of contributions consider situations where the function to be estimated or optimized is a basic average of individual observations, it is the goal of this article to investigate the case where the latter is of pairwise nature, taking the form of a U -statistic of degree two. Motivated by various problems such as similarity learning, ranking or clustering for instance, we revisit gossip algorithms specifically designed for pairwise objective functions and provide a comprehensive theoretical framework for their convergence. This analysis fills a gap in the literature by establishing conditions under which these methods succeed, and by identifying the graph properties that critically affect their efficiency. In particular, a refined analysis of the convergence upper and lower bounds is performed.
Privacy Amplification Persists under Unlimited Synthetic Data Release
Feb 03, 2026We study privacy amplification by synthetic data release, a phenomenon in which differential privacy guarantees are improved by releasing only synthetic data rather than the private generative model itself. Recent work by Pierquin et al. (2025) established the first formal amplification guarantees for a linear generator, but they apply only in asymptotic regimes where the model dimension far exceeds the number of released synthetic records, limiting their practical relevance. In this work, we show a surprising result: under a bounded-parameter assumption, privacy amplification persists even when releasing an unbounded number of synthetic records, thereby improving upon the bounds of Pierquin et al. (2025). Our analysis provides structural insights that may guide the development of tighter privacy guarantees for more complex release mechanisms.
Principled Federated Random Forests for Heterogeneous Data
Feb 03, 2026Random Forests (RF) are among the most powerful and widely used predictive models for centralized tabular data, yet few methods exist to adapt them to the federated learning setting. Unlike most federated learning approaches, the piecewise-constant nature of RF prevents exact gradient-based optimization. As a result, existing federated RF implementations rely on unprincipled heuristics: for instance, aggregating decision trees trained independently on clients fails to optimize the global impurity criterion, even under simple distribution shifts. We propose FedForest, a new federated RF algorithm for horizontally partitioned data that naturally accommodates diverse forms of client data heterogeneity, from covariate shift to more complex outcome shift mechanisms. We prove that our splitting procedure, based on aggregating carefully chosen client statistics, closely approximates the split selected by a centralized algorithm. Moreover, FedForest allows splits on client indicators, enabling a non-parametric form of personalization that is absent from prior federated random forest methods. Empirically, we demonstrate that the resulting federated forests closely match centralized performance across heterogeneous benchmarks while remaining communication-efficient.
Membership Inference Attacks from Causal Principles
Feb 02, 2026Membership Inference Attacks (MIAs) are widely used to quantify training data memorization and assess privacy risks. Standard evaluation requires repeated retraining, which is computationally costly for large models. One-run methods (single training with randomized data inclusion) and zero-run methods (post hoc evaluation) are often used instead, though their statistical validity remains unclear. To address this gap, we frame MIA evaluation as a causal inference problem, defining memorization as the causal effect of including a data point in the training set. This novel formulation reveals and formalizes key sources of bias in existing protocols: one-run methods suffer from interference between jointly included points, while zero-run evaluations popular for LLMs are confounded by non-random membership assignment. We derive causal analogues of standard MIA metrics and propose practical estimators for multi-run, one-run, and zero-run regimes with non-asymptotic consistency guarantees. Experiments on real-world data show that our approach enables reliable memorization measurement even when retraining is impractical and under distribution shift, providing a principled foundation for privacy evaluation in modern AI systems.
Optimal Transport under Group Fairness Constraints
Jan 12, 2026Ensuring fairness in matching algorithms is a key challenge in allocating scarce resources and positions. Focusing on Optimal Transport (OT), we introduce a novel notion of group fairness requiring that the probability of matching two individuals from any two given groups in the OT plan satisfies a predefined target. We first propose \texttt{FairSinkhorn}, a modified Sinkhorn algorithm to compute perfectly fair transport plans efficiently. Since exact fairness can significantly degrade matching quality in practice, we then develop two relaxation strategies. The first one involves solving a penalised OT problem, for which we derive novel finite-sample complexity guarantees. This result is of independent interest as it can be generalized to arbitrary convex penalties. Our second strategy leverages bilevel optimization to learn a ground cost that induces a fair OT solution, and we establish a bound guaranteeing that the learned cost yields fair matchings on unseen data. Finally, we present empirical results that illustrate the trade-offs between fairness and performance.
Federated Learning for MRI-based BrainAGE: a multicenter study on post-stroke functional outcome prediction
Jun 18, 2025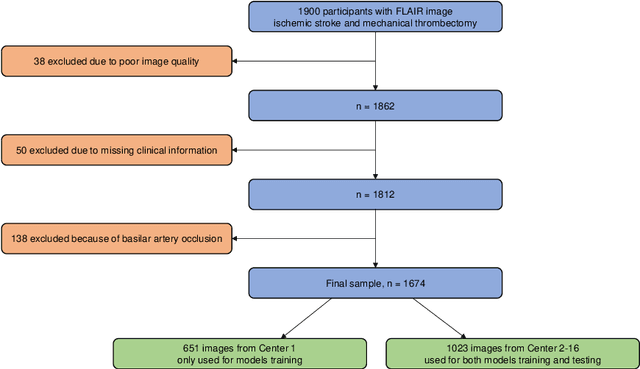
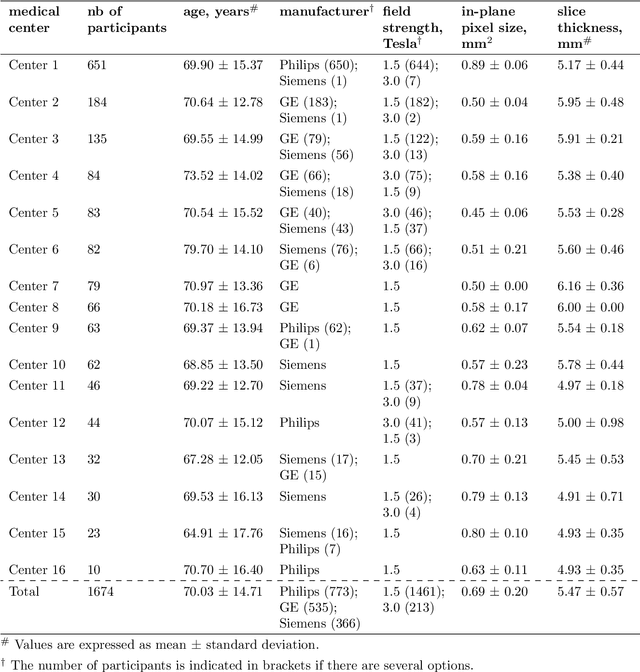
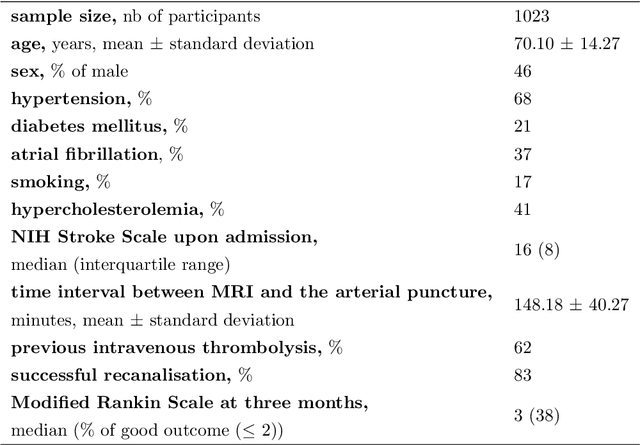
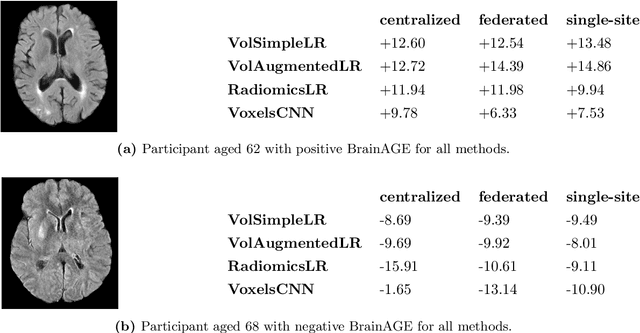
$\textbf{Objective:}$ Brain-predicted age difference (BrainAGE) is a neuroimaging biomarker reflecting brain health. However, training robust BrainAGE models requires large datasets, often restricted by privacy concerns. This study evaluates the performance of federated learning (FL) for BrainAGE estimation in ischemic stroke patients treated with mechanical thrombectomy, and investigates its association with clinical phenotypes and functional outcomes. $\textbf{Methods:}$ We used FLAIR brain images from 1674 stroke patients across 16 hospital centers. We implemented standard machine learning and deep learning models for BrainAGE estimates under three data management strategies: centralized learning (pooled data), FL (local training at each site), and single-site learning. We reported prediction errors and examined associations between BrainAGE and vascular risk factors (e.g., diabetes mellitus, hypertension, smoking), as well as functional outcomes at three months post-stroke. Logistic regression evaluated BrainAGE's predictive value for these outcomes, adjusting for age, sex, vascular risk factors, stroke severity, time between MRI and arterial puncture, prior intravenous thrombolysis, and recanalisation outcome. $\textbf{Results:}$ While centralized learning yielded the most accurate predictions, FL consistently outperformed single-site models. BrainAGE was significantly higher in patients with diabetes mellitus across all models. Comparisons between patients with good and poor functional outcomes, and multivariate predictions of these outcomes showed the significance of the association between BrainAGE and post-stroke recovery. $\textbf{Conclusion:}$ FL enables accurate age predictions without data centralization. The strong association between BrainAGE, vascular risk factors, and post-stroke recovery highlights its potential for prognostic modeling in stroke care.
Privacy Amplification Through Synthetic Data: Insights from Linear Regression
Jun 05, 2025


Synthetic data inherits the differential privacy guarantees of the model used to generate it. Additionally, synthetic data may benefit from privacy amplification when the generative model is kept hidden. While empirical studies suggest this phenomenon, a rigorous theoretical understanding is still lacking. In this paper, we investigate this question through the well-understood framework of linear regression. First, we establish negative results showing that if an adversary controls the seed of the generative model, a single synthetic data point can leak as much information as releasing the model itself. Conversely, we show that when synthetic data is generated from random inputs, releasing a limited number of synthetic data points amplifies privacy beyond the model's inherent guarantees. We believe our findings in linear regression can serve as a foundation for deriving more general bounds in the future.