 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSet-Valued Policy Learning
May 19, 2026Conventional treatment policies map patient covariates to a single recommended intervention in order to maximize expected clinical outcomes. Although a rich body of causal inference methods has been developed to estimate such policies, point-valued recommendations can be highly sensitive to estimation uncertainty, model specification, and finite-sample variability, while typically providing little guidance about how confident one should be in the recommended action. In this work, we propose a set-valued policy learning paradigm for the multiple-treatment setting, in which policies output a set of plausible treatments rather than a single recommendation. This formulation enables intrinsic uncertainty quantification, with the size of the predicted set reflecting the degree of decision ambiguity. We extend the learning-to-defer framework to multiple treatments via a novel \textit{greatest Lower Bound} method, and introduce \textit{conformal policy learning}, which bridges the gap between unobserved ground-truth optimal treatments and estimated optimal treatment rules. Drawing on insights from the noisy-label literature, we develop a randomness-injection approach that guarantees marginal coverage without requiring assumptions on underlying black-box optimal treatment rules. Through experiments on synthetic data and a real-world application to In-Vitro Fertilization (IVF), we demonstrate that our methods produce robust and actionable policies that naturally incorporate clinical considerations while effectively balancing performance and reliability.
Preference-based Conditional Treatment Effects and Policy Learning
Feb 03, 2026We introduce a new preference-based framework for conditional treatment effect estimation and policy learning, built on the Conditional Preference-based Treatment Effect (CPTE). CPTE requires only that outcomes be ranked under a preference rule, unlocking flexible modeling of heterogeneous effects with multivariate, ordinal, or preference-driven outcomes. This unifies applications such as conditional probability of necessity and sufficiency, conditional Win Ratio, and Generalized Pairwise Comparisons. Despite the intrinsic non-identifiability of comparison-based estimands, CPTE provides interpretable targets and delivers new identifiability conditions for previous unidentifiable estimands. We present estimation strategies via matching, quantile, and distributional regression, and further design efficient influence-function estimators to correct plug-in bias and maximize policy value. Synthetic and semi-synthetic experiments demonstrate clear performance gains and practical impact.
Improved Analysis of the Accelerated Noisy Power Method with Applications to Decentralized PCA
Feb 03, 2026We analyze the Accelerated Noisy Power Method, an algorithm for Principal Component Analysis in the setting where only inexact matrix-vector products are available, which can arise for instance in decentralized PCA. While previous works have established that acceleration can improve convergence rates compared to the standard Noisy Power Method, these guarantees require overly restrictive upper bounds on the magnitude of the perturbations, limiting their practical applicability. We provide an improved analysis of this algorithm, which preserves the accelerated convergence rate under much milder conditions on the perturbations. We show that our new analysis is worst-case optimal, in the sense that the convergence rate cannot be improved, and that the noise conditions we derive cannot be relaxed without sacrificing convergence guarantees. We demonstrate the practical relevance of our results by deriving an accelerated algorithm for decentralized PCA, which has similar communication costs to non-accelerated methods. To our knowledge, this is the first decentralized algorithm for PCA with provably accelerated convergence.
Membership Inference Attacks from Causal Principles
Feb 02, 2026Membership Inference Attacks (MIAs) are widely used to quantify training data memorization and assess privacy risks. Standard evaluation requires repeated retraining, which is computationally costly for large models. One-run methods (single training with randomized data inclusion) and zero-run methods (post hoc evaluation) are often used instead, though their statistical validity remains unclear. To address this gap, we frame MIA evaluation as a causal inference problem, defining memorization as the causal effect of including a data point in the training set. This novel formulation reveals and formalizes key sources of bias in existing protocols: one-run methods suffer from interference between jointly included points, while zero-run evaluations popular for LLMs are confounded by non-random membership assignment. We derive causal analogues of standard MIA metrics and propose practical estimators for multi-run, one-run, and zero-run regimes with non-asymptotic consistency guarantees. Experiments on real-world data show that our approach enables reliable memorization measurement even when retraining is impractical and under distribution shift, providing a principled foundation for privacy evaluation in modern AI systems.
Model Agnostic Differentially Private Causal Inference
May 26, 2025



Estimating causal effects from observational data is essential in fields such as medicine, economics and social sciences, where privacy concerns are paramount. We propose a general, model-agnostic framework for differentially private estimation of average treatment effects (ATE) that avoids strong structural assumptions on the data-generating process or the models used to estimate propensity scores and conditional outcomes. In contrast to prior work, which enforces differential privacy by directly privatizing these nuisance components and results in a privacy cost that scales with model complexity, our approach decouples nuisance estimation from privacy protection. This separation allows the use of flexible, state-of-the-art black-box models, while differential privacy is achieved by perturbing only predictions and aggregation steps within a fold-splitting scheme with ensemble techniques. We instantiate the framework for three classical estimators -- the G-formula, inverse propensity weighting (IPW), and augmented IPW (AIPW) -- and provide formal utility and privacy guarantees. Empirical results show that our methods maintain competitive performance under realistic privacy budgets. We further extend our framework to support meta-analysis of multiple private ATE estimates. Our results bridge a critical gap between causal inference and privacy-preserving data analysis.
Meta-learning of shared linear representations beyond well-specified linear regression
Jan 31, 2025Motivated by multi-task and meta-learning approaches, we consider the problem of learning structure shared by tasks or users, such as shared low-rank representations or clustered structures. While all previous works focus on well-specified linear regression, we consider more general convex objectives, where the structural low-rank and cluster assumptions are expressed on the optima of each function. We show that under mild assumptions such as \textit{Hessian concentration} and \textit{noise concentration at the optimum}, rank and clustered regularized estimators recover such structure, provided the number of samples per task and the number of tasks are large enough. We then study the problem of recovering the subspace in which all the solutions lie, in the setting where there is only a single sample per task: we show that in that case, the rank-constrained estimator can recover the subspace, but that the number of tasks needs to scale exponentially large with the dimension of the subspace. Finally, we provide a polynomial-time algorithm via nuclear norm constraints for learning a shared linear representation in the context of convex learning objectives.
Long-Context Linear System Identification
Oct 08, 2024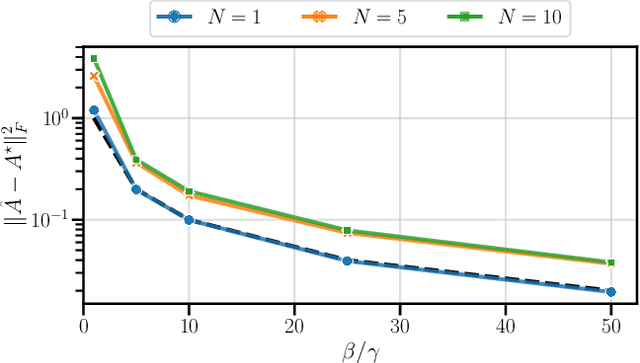
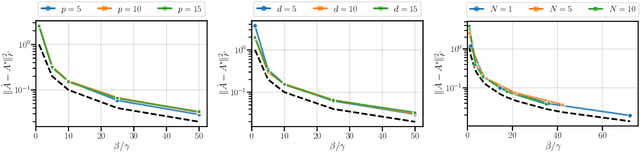
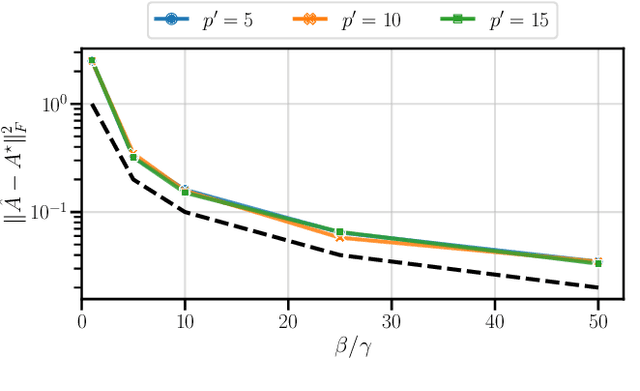

This paper addresses the problem of long-context linear system identification, where the state $x_t$ of a dynamical system at time $t$ depends linearly on previous states $x_s$ over a fixed context window of length $p$. We establish a sample complexity bound that matches the i.i.d. parametric rate up to logarithmic factors for a broad class of systems, extending previous works that considered only first-order dependencies. Our findings reveal a learning-without-mixing phenomenon, indicating that learning long-context linear autoregressive models is not hindered by slow mixing properties potentially associated with extended context windows. Additionally, we extend these results to (i) shared low-rank representations, where rank-regularized estimators improve rates with respect to dimensionality, and (ii) misspecified context lengths in strictly stable systems, where shorter contexts offer statistical advantages.
Aligning Embeddings and Geometric Random Graphs: Informational Results and Computational Approaches for the Procrustes-Wasserstein Problem
May 23, 2024The Procrustes-Wasserstein problem consists in matching two high-dimensional point clouds in an unsupervised setting, and has many applications in natural language processing and computer vision. We consider a planted model with two datasets $X,Y$ that consist of $n$ datapoints in $\mathbb{R}^d$, where $Y$ is a noisy version of $X$, up to an orthogonal transformation and a relabeling of the data points. This setting is related to the graph alignment problem in geometric models. In this work, we focus on the euclidean transport cost between the point clouds as a measure of performance for the alignment. We first establish information-theoretic results, in the high ($d \gg \log n$) and low ($d \ll \log n$) dimensional regimes. We then study computational aspects and propose the Ping-Pong algorithm, alternatively estimating the orthogonal transformation and the relabeling, initialized via a Franke-Wolfe convex relaxation. We give sufficient conditions for the method to retrieve the planted signal after one single step. We provide experimental results to compare the proposed approach with the state-of-the-art method of Grave et al. (2019).
Beyond Noise: Privacy-Preserving Decentralized Learning with Virtual Nodes
Apr 15, 2024Decentralized learning (DL) enables collaborative learning without a server and without training data leaving the users' devices. However, the models shared in DL can still be used to infer training data. Conventional privacy defenses such as differential privacy and secure aggregation fall short in effectively safeguarding user privacy in DL. We introduce Shatter, a novel DL approach in which nodes create virtual nodes (VNs) to disseminate chunks of their full model on their behalf. This enhances privacy by (i) preventing attackers from collecting full models from other nodes, and (ii) hiding the identity of the original node that produced a given model chunk. We theoretically prove the convergence of Shatter and provide a formal analysis demonstrating how Shatter reduces the efficacy of attacks compared to when exchanging full models between participating nodes. We evaluate the convergence and attack resilience of Shatter with existing DL algorithms, with heterogeneous datasets, and against three standard privacy attacks, including gradient inversion. Our evaluation shows that Shatter not only renders these privacy attacks infeasible when each node operates 16 VNs but also exhibits a positive impact on model convergence compared to standard DL. This enhanced privacy comes with a manageable increase in communication volume.
Asynchronous SGD on Graphs: a Unified Framework for Asynchronous Decentralized and Federated Optimization
Nov 01, 2023
Decentralized and asynchronous communications are two popular techniques to speedup communication complexity of distributed machine learning, by respectively removing the dependency over a central orchestrator and the need for synchronization. Yet, combining these two techniques together still remains a challenge. In this paper, we take a step in this direction and introduce Asynchronous SGD on Graphs (AGRAF SGD) -- a general algorithmic framework that covers asynchronous versions of many popular algorithms including SGD, Decentralized SGD, Local SGD, FedBuff, thanks to its relaxed communication and computation assumptions. We provide rates of convergence under much milder assumptions than previous decentralized asynchronous works, while still recovering or even improving over the best know results for all the algorithms covered.