 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-Context Linear System Identification
Paper and Code
Oct 08, 2024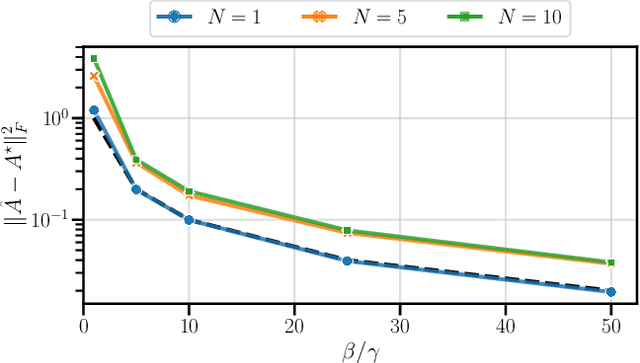
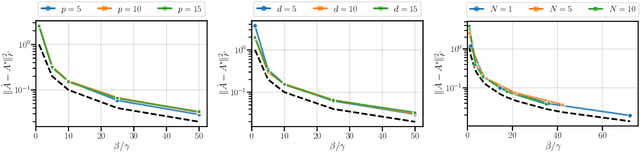
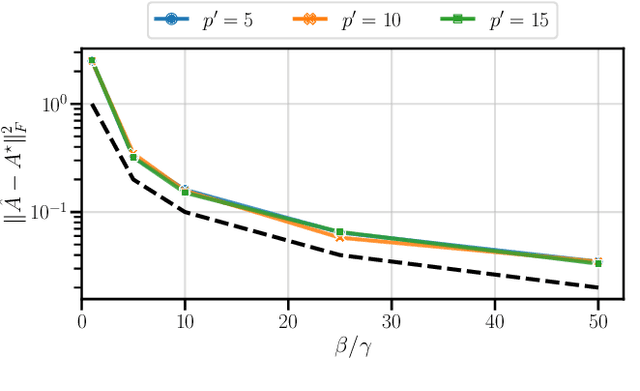

This paper addresses the problem of long-context linear system identification, where the state $x_t$ of a dynamical system at time $t$ depends linearly on previous states $x_s$ over a fixed context window of length $p$. We establish a sample complexity bound that matches the i.i.d. parametric rate up to logarithmic factors for a broad class of systems, extending previous works that considered only first-order dependencies. Our findings reveal a learning-without-mixing phenomenon, indicating that learning long-context linear autoregressive models is not hindered by slow mixing properties potentially associated with extended context windows. Additionally, we extend these results to (i) shared low-rank representations, where rank-regularized estimators improve rates with respect to dimensionality, and (ii) misspecified context lengths in strictly stable systems, where shorter contexts offer statistical advantages.