 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncremental Learning of Sparse Attention Patterns in Transformers
Feb 22, 2026This paper introduces a high-order Markov chain task to investigate how transformers learn to integrate information from multiple past positions with varying statistical significance. We demonstrate that transformers learn this task incrementally: each stage is defined by the acquisition of specific information through sparse attention patterns. Notably, we identify a shift in learning dynamics from competitive, where heads converge on the most statistically dominant pattern, to cooperative, where heads specialize in distinct patterns. We model these dynamics using simplified differential equations that characterize the trajectory and prove stage-wise convergence results. Our analysis reveals that transformers ascend a complexity ladder by passing through simpler, misspecified hypothesis classes before reaching the full model class. We further show that early stopping acts as an implicit regularizer, biasing the model toward these simpler classes. These results provide a theoretical foundation for the emergence of staged learning and complex behaviors in transformers, offering insights into generalization for natural language processing and algorithmic reasoning.
Long-Context Linear System Identification
Oct 08, 2024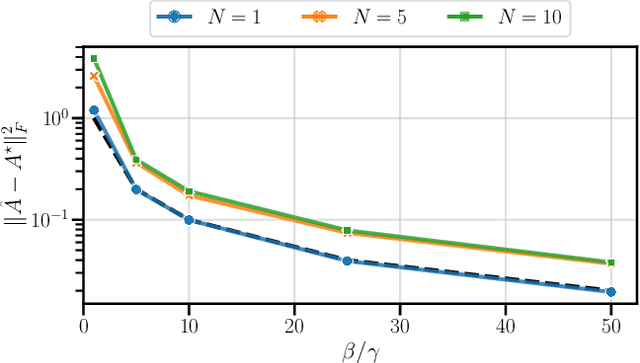
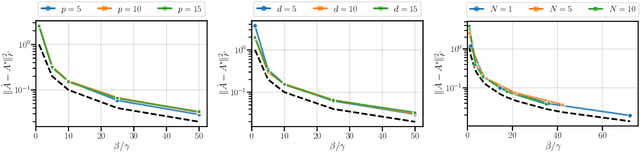
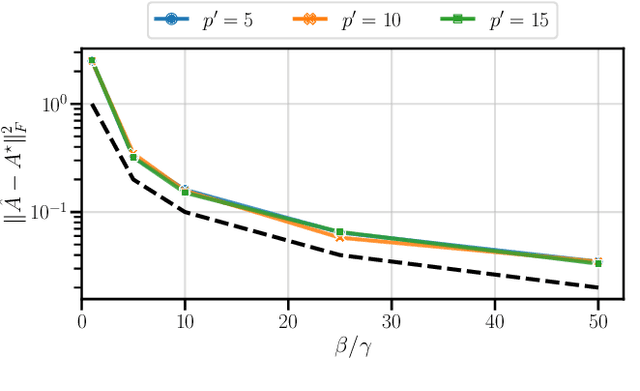

This paper addresses the problem of long-context linear system identification, where the state $x_t$ of a dynamical system at time $t$ depends linearly on previous states $x_s$ over a fixed context window of length $p$. We establish a sample complexity bound that matches the i.i.d. parametric rate up to logarithmic factors for a broad class of systems, extending previous works that considered only first-order dependencies. Our findings reveal a learning-without-mixing phenomenon, indicating that learning long-context linear autoregressive models is not hindered by slow mixing properties potentially associated with extended context windows. Additionally, we extend these results to (i) shared low-rank representations, where rank-regularized estimators improve rates with respect to dimensionality, and (ii) misspecified context lengths in strictly stable systems, where shorter contexts offer statistical advantages.
LatentCLR: A Contrastive Learning Approach for Unsupervised Discovery of Interpretable Directions
Apr 02, 2021



Recent research has shown great potential for finding interpretable directions in the latent spaces of pre-trained Generative Adversarial Networks (GANs). These directions provide controllable generation and support a wide range of semantic editing operations such as zoom or rotation. The discovery of such directions is often performed in a supervised or semi-supervised fashion and requires manual annotations, limiting their applications in practice. In comparison, unsupervised discovery enables finding subtle directions a priori hard to recognize. In this work, we propose a contrastive-learning-based approach for discovering semantic directions in the latent space of pretrained GANs in a self-supervised manner. Our approach finds semantically meaningful dimensions compatible with state-of-the-art methods.