 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhase Transition in Convex Relaxations for Graph Alignment
Jun 14, 2026We study the graph alignment problem for correlated Gaussian Orthogonal Ensemble (GOE) matrices, where the goal is to recover a hidden vertex permutation given two correlated symmetric Gaussian matrices $(A, B)$ with correlation $1/\sqrt{1+σ^2}$. While the maximum likelihood estimator is information-theoretically optimal, its computation, which reduces to a quadratic assignment problem, is intractable. Motivated by this, we analyze convex relaxations based on minimizing $\|AX - XB\|_F$ over the set of doubly stochastic matrices and the unit hypercube. We show that when the correlation parameter satisfies $σ= o(n^{-1/2}/\log^4 n)$, the solution of either relaxation $(X^\star)$ concentrates around the ground-truth permutation matrix $(Π^\star)$, i.e., $\|X^\star-Π^\star\|_F^2 = o(n)$, implying recovery of all but a vanishing fraction of vertices after simple post-processing. Combined with existing lower bounds, our results precisely characterize that $\|X^\star-Π^\star\|_F^2$ transitions from $o(n)$ for $σ= \tilde{o}(n^{-1/2})$ to $Ω(n)$ for $σ= \tildeΩ(n^{-1/2})$. In doing so, our analysis significantly tightens prior results and extends them beyond doubly stochastic relaxations.
Learning with Shallow Neural Networks on Cluster-Structured Features
May 14, 2026The success of deep learning in high-dimensional settings is often attributed to the presence of low-dimensional structure in real-world data. While standard theoretical models typically assume that this structure lies in the target function, projecting unstructured inputs onto a low-dimensional subspace, data such as images, text or genomic sequences exhibit strong spatial correlations within the input space itself. In this paper, we propose a tractable model to study how these correlations affect the sample complexity of learning with gradient descent on shallow neural networks. Specifically, we consider targets that depend on a small number of latent Boolean variables, and input features grouped into clusters and correlated with the latent variables. Under an identifiability assumption, we show that for a layerwise gradient-descent variant, the sample complexity scales with the number of hidden variables and, when the signal-to-noise ratio is sufficiently high, is independent of the input dimension, up to logarithmic terms. We empirically test our theoretical findings on both synthetic and real data.
Unbiased Approximate Vector-Jacobian Products for Efficient Backpropagation
Feb 16, 2026In this work we introduce methods to reduce the computational and memory costs of training deep neural networks. Our approach consists in replacing exact vector-jacobian products by randomized, unbiased approximations thereof during backpropagation. We provide a theoretical analysis of the trade-off between the number of epochs needed to achieve a target precision and the cost reduction for each epoch. We then identify specific unbiased estimates of vector-jacobian products for which we establish desirable optimality properties of minimal variance under sparsity constraints. Finally we provide in-depth experiments on multi-layer perceptrons, BagNets and Visual Transfomers architectures. These validate our theoretical results, and confirm the potential of our proposed unbiased randomized backpropagation approach for reducing the cost of deep learning.
Improved Analysis of the Accelerated Noisy Power Method with Applications to Decentralized PCA
Feb 03, 2026We analyze the Accelerated Noisy Power Method, an algorithm for Principal Component Analysis in the setting where only inexact matrix-vector products are available, which can arise for instance in decentralized PCA. While previous works have established that acceleration can improve convergence rates compared to the standard Noisy Power Method, these guarantees require overly restrictive upper bounds on the magnitude of the perturbations, limiting their practical applicability. We provide an improved analysis of this algorithm, which preserves the accelerated convergence rate under much milder conditions on the perturbations. We show that our new analysis is worst-case optimal, in the sense that the convergence rate cannot be improved, and that the noise conditions we derive cannot be relaxed without sacrificing convergence guarantees. We demonstrate the practical relevance of our results by deriving an accelerated algorithm for decentralized PCA, which has similar communication costs to non-accelerated methods. To our knowledge, this is the first decentralized algorithm for PCA with provably accelerated convergence.
Adaptive collaboration for online personalized distributed learning with heterogeneous clients
Jul 09, 2025We study the problem of online personalized decentralized learning with $N$ statistically heterogeneous clients collaborating to accelerate local training. An important challenge in this setting is to select relevant collaborators to reduce gradient variance while mitigating the introduced bias. To tackle this, we introduce a gradient-based collaboration criterion, allowing each client to dynamically select peers with similar gradients during the optimization process. Our criterion is motivated by a refined and more general theoretical analysis of the All-for-one algorithm, proved to be optimal in Even et al. (2022) for an oracle collaboration scheme. We derive excess loss upper-bounds for smooth objective functions, being either strongly convex, non-convex, or satisfying the Polyak-Lojasiewicz condition; our analysis reveals that the algorithm acts as a variance reduction method where the speed-up depends on a sufficient variance. We put forward two collaboration methods instantiating the proposed general schema; and we show that one variant preserves the optimality of All-for-one. We validate our results with experiments on synthetic and real datasets.
Learnable Adaptive Time-Frequency Representation via Differentiable Short-Time Fourier Transform
Jun 26, 2025The short-time Fourier transform (STFT) is widely used for analyzing non-stationary signals. However, its performance is highly sensitive to its parameters, and manual or heuristic tuning often yields suboptimal results. To overcome this limitation, we propose a unified differentiable formulation of the STFT that enables gradient-based optimization of its parameters. This approach addresses the limitations of traditional STFT parameter tuning methods, which often rely on computationally intensive discrete searches. It enables fine-tuning of the time-frequency representation (TFR) based on any desired criterion. Moreover, our approach integrates seamlessly with neural networks, allowing joint optimization of the STFT parameters and network weights. The efficacy of the proposed differentiable STFT in enhancing TFRs and improving performance in downstream tasks is demonstrated through experiments on both simulated and real-world data.
Graph Alignment via Birkhoff Relaxation
Mar 07, 2025
We consider the graph alignment problem, wherein the objective is to find a vertex correspondence between two graphs that maximizes the edge overlap. The graph alignment problem is an instance of the quadratic assignment problem (QAP), known to be NP-hard in the worst case even to approximately solve. In this paper, we analyze Birkhoff relaxation, a tight convex relaxation of QAP, and present theoretical guarantees on its performance when the inputs follow the Gaussian Wigner Model. More specifically, the weighted adjacency matrices are correlated Gaussian Orthogonal Ensemble with correlation $1/\sqrt{1+\sigma^2}$. Denote the optimal solutions of the QAP and Birkhoff relaxation by $\Pi^\star$ and $X^\star$ respectively. We show that $\|X^\star-\Pi^\star\|_F^2 = o(n)$ when $\sigma = o(n^{-1.25})$ and $\|X^\star-\Pi^\star\|_F^2 = \Omega(n)$ when $\sigma = \Omega(n^{-0.5})$. Thus, the optimal solution $X^\star$ transitions from a small perturbation of $\Pi^\star$ for small $\sigma$ to being well separated from $\Pi^\star$ as $\sigma$ becomes larger than $n^{-0.5}$. This result allows us to guarantee that simple rounding procedures on $X^\star$ align $1-o(1)$ fraction of vertices correctly whenever $\sigma = o(n^{-1.25})$. This condition on $\sigma$ to ensure the success of the Birkhoff relaxation is state-of-the-art.
The feasibility of multi-graph alignment: a Bayesian approach
Feb 24, 2025We establish thresholds for the feasibility of random multi-graph alignment in two models. In the Gaussian model, we demonstrate an "all-or-nothing" phenomenon: above a critical threshold, exact alignment is achievable with high probability, while below it, even partial alignment is statistically impossible. In the sparse Erd\H{o}s-R\'enyi model, we rigorously identify a threshold below which no meaningful partial alignment is possible and conjecture that above this threshold, partial alignment can be achieved. To prove these results, we develop a general Bayesian estimation framework over metric spaces, which provides insight into a broader class of high-dimensional statistical problems.
Meta-learning of shared linear representations beyond well-specified linear regression
Jan 31, 2025Motivated by multi-task and meta-learning approaches, we consider the problem of learning structure shared by tasks or users, such as shared low-rank representations or clustered structures. While all previous works focus on well-specified linear regression, we consider more general convex objectives, where the structural low-rank and cluster assumptions are expressed on the optima of each function. We show that under mild assumptions such as \textit{Hessian concentration} and \textit{noise concentration at the optimum}, rank and clustered regularized estimators recover such structure, provided the number of samples per task and the number of tasks are large enough. We then study the problem of recovering the subspace in which all the solutions lie, in the setting where there is only a single sample per task: we show that in that case, the rank-constrained estimator can recover the subspace, but that the number of tasks needs to scale exponentially large with the dimension of the subspace. Finally, we provide a polynomial-time algorithm via nuclear norm constraints for learning a shared linear representation in the context of convex learning objectives.
In-depth Analysis of Low-rank Matrix Factorisation in a Federated Setting
Sep 13, 2024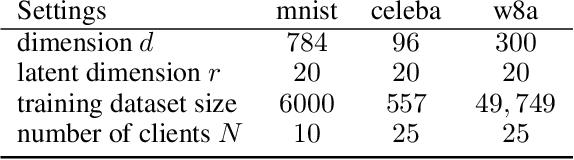
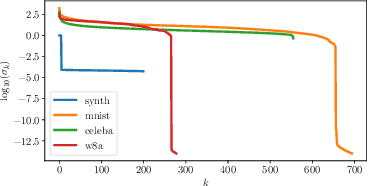
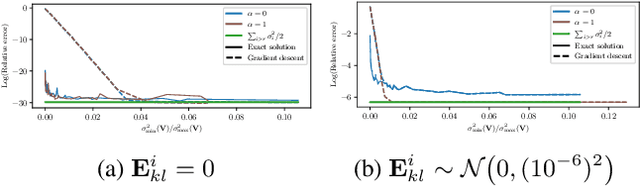
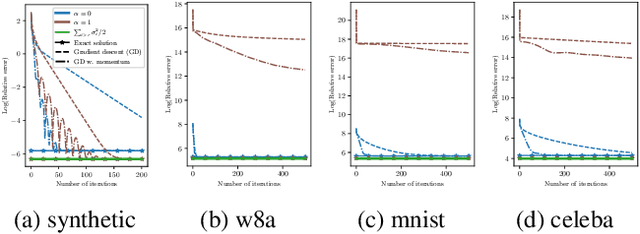
We analyze a distributed algorithm to compute a low-rank matrix factorization on $N$ clients, each holding a local dataset $\mathbf{S}^i \in \mathbb{R}^{n_i \times d}$, mathematically, we seek to solve $min_{\mathbf{U}^i \in \mathbb{R}^{n_i\times r}, \mathbf{V}\in \mathbb{R}^{d \times r} } \frac{1}{2} \sum_{i=1}^N \|\mathbf{S}^i - \mathbf{U}^i \mathbf{V}^\top\|^2_{\text{F}}$. Considering a power initialization of $\mathbf{V}$, we rewrite the previous smooth non-convex problem into a smooth strongly-convex problem that we solve using a parallel Nesterov gradient descent potentially requiring a single step of communication at the initialization step. For any client $i$ in $\{1, \dots, N\}$, we obtain a global $\mathbf{V}$ in $\mathbb{R}^{d \times r}$ common to all clients and a local variable $\mathbf{U}^i$ in $\mathbb{R}^{n_i \times r}$. We provide a linear rate of convergence of the excess loss which depends on $\sigma_{\max} / \sigma_{r}$, where $\sigma_{r}$ is the $r^{\mathrm{th}}$ singular value of the concatenation $\mathbf{S}$ of the matrices $(\mathbf{S}^i)_{i=1}^N$. This result improves the rates of convergence given in the literature, which depend on $\sigma_{\max}^2 / \sigma_{\min}^2$. We provide an upper bound on the Frobenius-norm error of reconstruction under the power initialization strategy. We complete our analysis with experiments on both synthetic and real data.