 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-depth Analysis of Low-rank Matrix Factorisation in a Federated Setting
Paper and Code
Sep 13, 2024
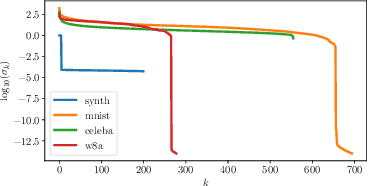
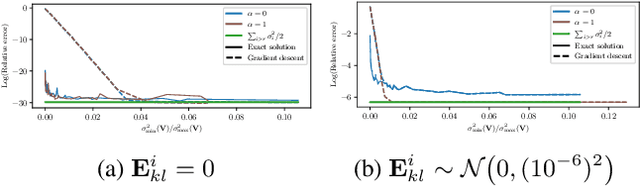
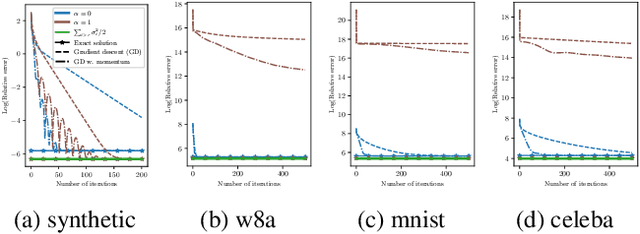
We analyze a distributed algorithm to compute a low-rank matrix factorization on $N$ clients, each holding a local dataset $\mathbf{S}^i \in \mathbb{R}^{n_i \times d}$, mathematically, we seek to solve $min_{\mathbf{U}^i \in \mathbb{R}^{n_i\times r}, \mathbf{V}\in \mathbb{R}^{d \times r} } \frac{1}{2} \sum_{i=1}^N \|\mathbf{S}^i - \mathbf{U}^i \mathbf{V}^\top\|^2_{\text{F}}$. Considering a power initialization of $\mathbf{V}$, we rewrite the previous smooth non-convex problem into a smooth strongly-convex problem that we solve using a parallel Nesterov gradient descent potentially requiring a single step of communication at the initialization step. For any client $i$ in $\{1, \dots, N\}$, we obtain a global $\mathbf{V}$ in $\mathbb{R}^{d \times r}$ common to all clients and a local variable $\mathbf{U}^i$ in $\mathbb{R}^{n_i \times r}$. We provide a linear rate of convergence of the excess loss which depends on $\sigma_{\max} / \sigma_{r}$, where $\sigma_{r}$ is the $r^{\mathrm{th}}$ singular value of the concatenation $\mathbf{S}$ of the matrices $(\mathbf{S}^i)_{i=1}^N$. This result improves the rates of convergence given in the literature, which depend on $\sigma_{\max}^2 / \sigma_{\min}^2$. We provide an upper bound on the Frobenius-norm error of reconstruction under the power initialization strategy. We complete our analysis with experiments on both synthetic and real data.