 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivate Rate-Constrained Optimization with Applications to Fair Learning
May 28, 2025



Many problems in trustworthy ML can be formulated as minimization of the model error under constraints on the prediction rates of the model for suitably-chosen marginals, including most group fairness constraints (demographic parity, equality of odds, etc.). In this work, we study such constrained minimization problems under differential privacy (DP). Standard DP optimization techniques like DP-SGD rely on the loss function's decomposability into per-sample contributions. However, rate constraints introduce inter-sample dependencies, violating the decomposability requirement. To address this, we develop RaCO-DP, a DP variant of the Stochastic Gradient Descent-Ascent (SGDA) algorithm which solves the Lagrangian formulation of rate constraint problems. We demonstrate that the additional privacy cost of incorporating these constraints reduces to privately estimating a histogram over the mini-batch at each optimization step. We prove the convergence of our algorithm through a novel analysis of SGDA that leverages the linear structure of the dual parameter. Finally, empirical results on learning under group fairness constraints demonstrate that our method Pareto-dominates existing private learning approaches in fairness-utility trade-offs.
Suitability Filter: A Statistical Framework for Classifier Evaluation in Real-World Deployment Settings
May 28, 2025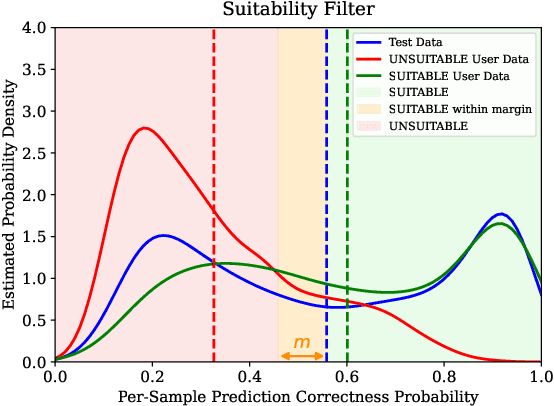
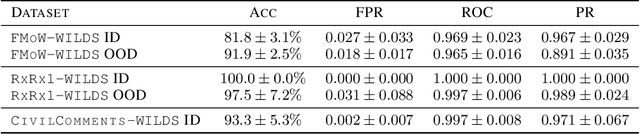
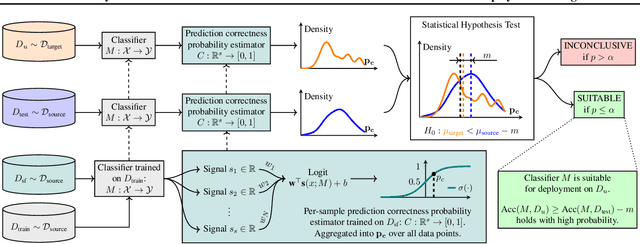
Deploying machine learning models in safety-critical domains poses a key challenge: ensuring reliable model performance on downstream user data without access to ground truth labels for direct validation. We propose the suitability filter, a novel framework designed to detect performance deterioration by utilizing suitability signals -- model output features that are sensitive to covariate shifts and indicative of potential prediction errors. The suitability filter evaluates whether classifier accuracy on unlabeled user data shows significant degradation compared to the accuracy measured on the labeled test dataset. Specifically, it ensures that this degradation does not exceed a pre-specified margin, which represents the maximum acceptable drop in accuracy. To achieve reliable performance evaluation, we aggregate suitability signals for both test and user data and compare these empirical distributions using statistical hypothesis testing, thus providing insights into decision uncertainty. Our modular method adapts to various models and domains. Empirical evaluations across different classification tasks demonstrate that the suitability filter reliably detects performance deviations due to covariate shift. This enables proactive mitigation of potential failures in high-stakes applications.
On the Privacy Risk of In-context Learning
Nov 15, 2024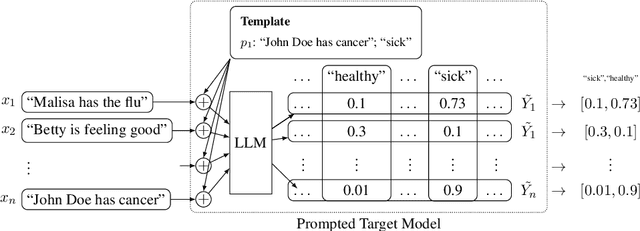
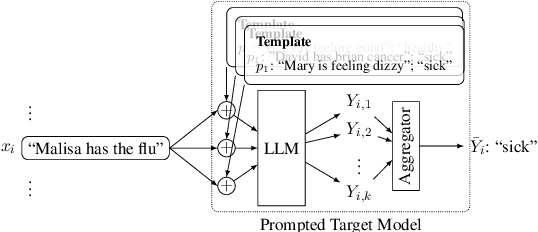

Large language models (LLMs) are excellent few-shot learners. They can perform a wide variety of tasks purely based on natural language prompts provided to them. These prompts contain data of a specific downstream task -- often the private dataset of a party, e.g., a company that wants to leverage the LLM for their purposes. We show that deploying prompted models presents a significant privacy risk for the data used within the prompt by instantiating a highly effective membership inference attack. We also observe that the privacy risk of prompted models exceeds fine-tuned models at the same utility levels. After identifying the model's sensitivity to their prompts -- in the form of a significantly higher prediction confidence on the prompted data -- as a cause for the increased risk, we propose ensembling as a mitigation strategy. By aggregating over multiple different versions of a prompted model, membership inference risk can be decreased.
Regulation Games for Trustworthy Machine Learning
Feb 05, 2024Existing work on trustworthy machine learning (ML) often concentrates on individual aspects of trust, such as fairness or privacy. Additionally, many techniques overlook the distinction between those who train ML models and those responsible for assessing their trustworthiness. To address these issues, we propose a framework that views trustworthy ML as a multi-objective multi-agent optimization problem. This naturally lends itself to a game-theoretic formulation we call regulation games. We illustrate a particular game instance, the SpecGame in which we model the relationship between an ML model builder and fairness and privacy regulators. Regulators wish to design penalties that enforce compliance with their specification, but do not want to discourage builders from participation. Seeking such socially optimal (i.e., efficient for all agents) solutions to the game, we introduce ParetoPlay. This novel equilibrium search algorithm ensures that agents remain on the Pareto frontier of their objectives and avoids the inefficiencies of other equilibria. Simulating SpecGame through ParetoPlay can provide policy guidance for ML Regulation. For instance, we show that for a gender classification application, regulators can enforce a differential privacy budget that is on average 4.0 lower if they take the initiative to specify their desired guarantee first.
Learning with Impartiality to Walk on the Pareto Frontier of Fairness, Privacy, and Utility
Feb 17, 2023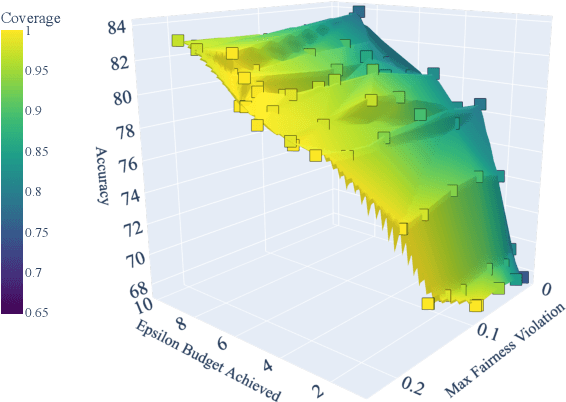
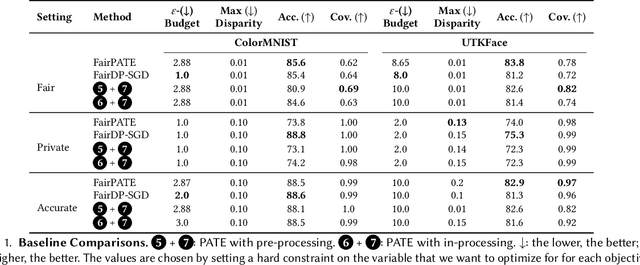

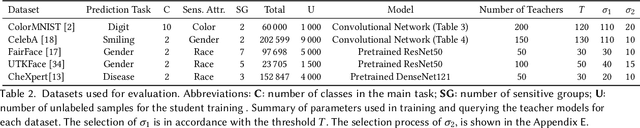
Deploying machine learning (ML) models often requires both fairness and privacy guarantees. Both of these objectives present unique trade-offs with the utility (e.g., accuracy) of the model. However, the mutual interactions between fairness, privacy, and utility are less well-understood. As a result, often only one objective is optimized, while the others are tuned as hyper-parameters. Because they implicitly prioritize certain objectives, such designs bias the model in pernicious, undetectable ways. To address this, we adopt impartiality as a principle: design of ML pipelines should not favor one objective over another. We propose impartially-specified models, which provide us with accurate Pareto frontiers that show the inherent trade-offs between the objectives. Extending two canonical ML frameworks for privacy-preserving learning, we provide two methods (FairDP-SGD and FairPATE) to train impartially-specified models and recover the Pareto frontier. Through theoretical privacy analysis and a comprehensive empirical study, we provide an answer to the question of where fairness mitigation should be integrated within a privacy-aware ML pipeline.
On the Fundamental Limits of Formally Proving Robustness in Proof-of-Learning
Aug 06, 2022



Proof-of-learning (PoL) proposes a model owner use machine learning training checkpoints to establish a proof of having expended the necessary compute for training. The authors of PoL forego cryptographic approaches and trade rigorous security guarantees for scalability to deep learning by being applicable to stochastic gradient descent and adaptive variants. This lack of formal analysis leaves the possibility that an attacker may be able to spoof a proof for a model they did not train. We contribute a formal analysis of why the PoL protocol cannot be formally (dis)proven to be robust against spoofing adversaries. To do so, we disentangle the two roles of proof verification in PoL: (a) efficiently determining if a proof is a valid gradient descent trajectory, and (b) establishing precedence by making it more expensive to craft a proof after training completes (i.e., spoofing). We show that efficient verification results in a tradeoff between accepting legitimate proofs and rejecting invalid proofs because deep learning necessarily involves noise. Without a precise analytical model for how this noise affects training, we cannot formally guarantee if a PoL verification algorithm is robust. Then, we demonstrate that establishing precedence robustly also reduces to an open problem in learning theory: spoofing a PoL post hoc training is akin to finding different trajectories with the same endpoint in non-convex learning. Yet, we do not rigorously know if priori knowledge of the final model weights helps discover such trajectories. We conclude that, until the aforementioned open problems are addressed, relying more heavily on cryptography is likely needed to formulate a new class of PoL protocols with formal robustness guarantees. In particular, this will help with establishing precedence. As a by-product of insights from our analysis, we also demonstrate two novel attacks against PoL.
$p$-DkNN: Out-of-Distribution Detection Through Statistical Testing of Deep Representations
Jul 25, 2022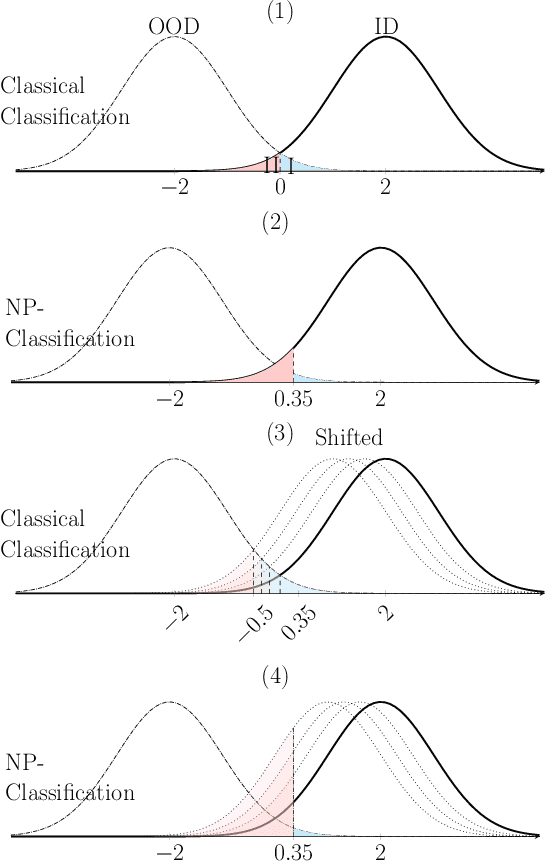
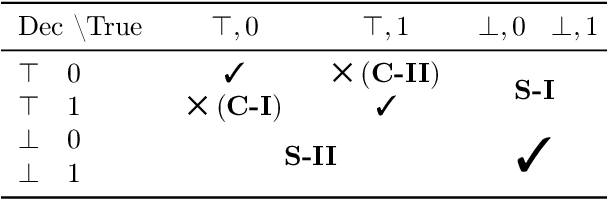
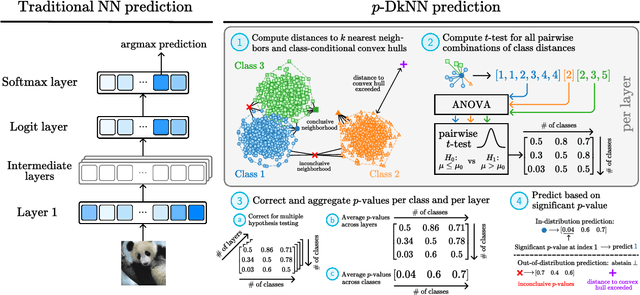
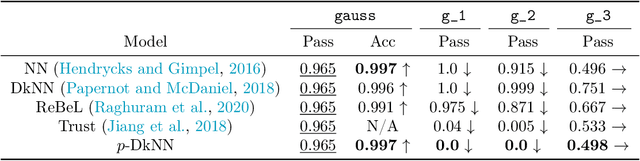
The lack of well-calibrated confidence estimates makes neural networks inadequate in safety-critical domains such as autonomous driving or healthcare. In these settings, having the ability to abstain from making a prediction on out-of-distribution (OOD) data can be as important as correctly classifying in-distribution data. We introduce $p$-DkNN, a novel inference procedure that takes a trained deep neural network and analyzes the similarity structures of its intermediate hidden representations to compute $p$-values associated with the end-to-end model prediction. The intuition is that statistical tests performed on latent representations can serve not only as a classifier, but also offer a statistically well-founded estimation of uncertainty. $p$-DkNN is scalable and leverages the composition of representations learned by hidden layers, which makes deep representation learning successful. Our theoretical analysis builds on Neyman-Pearson classification and connects it to recent advances in selective classification (reject option). We demonstrate advantageous trade-offs between abstaining from predicting on OOD inputs and maintaining high accuracy on in-distribution inputs. We find that $p$-DkNN forces adaptive attackers crafting adversarial examples, a form of worst-case OOD inputs, to introduce semantically meaningful changes to the inputs.
Pipe Overflow: Smashing Voice Authentication for Fun and Profit
Feb 06, 2022



Recent years have seen a surge of popularity of acoustics-enabled personal devices powered by machine learning. Yet, machine learning has proven to be vulnerable to adversarial examples. Large number of modern systems protect themselves against such attacks by targeting the artificiality, i.e., they deploy mechanisms to detect the lack of human involvement in generating the adversarial examples. However, these defenses implicitly assume that humans are incapable of producing meaningful and targeted adversarial examples. In this paper, we show that this base assumption is wrong. In particular, we demonstrate that for tasks like speaker identification, a human is capable of producing analog adversarial examples directly with little cost and supervision: by simply speaking through a tube, an adversary reliably impersonates other speakers in eyes of ML models for speaker identification. Our findings extend to a range of other acoustic-biometric tasks such as liveness, bringing into question their use in security-critical settings in real life, such as phone banking.
SoK: Machine Learning Governance
Sep 20, 2021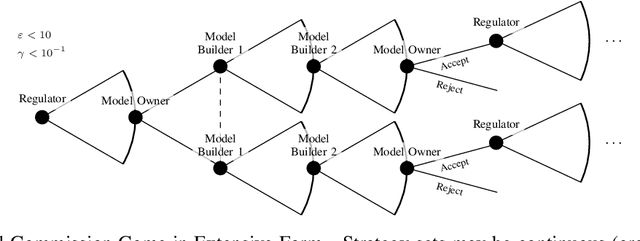
The application of machine learning (ML) in computer systems introduces not only many benefits but also risks to society. In this paper, we develop the concept of ML governance to balance such benefits and risks, with the aim of achieving responsible applications of ML. Our approach first systematizes research towards ascertaining ownership of data and models, thus fostering a notion of identity specific to ML systems. Building on this foundation, we use identities to hold principals accountable for failures of ML systems through both attribution and auditing. To increase trust in ML systems, we then survey techniques for developing assurance, i.e., confidence that the system meets its security requirements and does not exhibit certain known failures. This leads us to highlight the need for techniques that allow a model owner to manage the life cycle of their system, e.g., to patch or retire their ML system. Put altogether, our systematization of knowledge standardizes the interactions between principals involved in the deployment of ML throughout its life cycle. We highlight opportunities for future work, e.g., to formalize the resulting game between ML principals.
Dataset Inference: Ownership Resolution in Machine Learning
Apr 21, 2021



With increasingly more data and computation involved in their training, machine learning models constitute valuable intellectual property. This has spurred interest in model stealing, which is made more practical by advances in learning with partial, little, or no supervision. Existing defenses focus on inserting unique watermarks in a model's decision surface, but this is insufficient: the watermarks are not sampled from the training distribution and thus are not always preserved during model stealing. In this paper, we make the key observation that knowledge contained in the stolen model's training set is what is common to all stolen copies. The adversary's goal, irrespective of the attack employed, is always to extract this knowledge or its by-products. This gives the original model's owner a strong advantage over the adversary: model owners have access to the original training data. We thus introduce $dataset$ $inference$, the process of identifying whether a suspected model copy has private knowledge from the original model's dataset, as a defense against model stealing. We develop an approach for dataset inference that combines statistical testing with the ability to estimate the distance of multiple data points to the decision boundary. Our experiments on CIFAR10, SVHN, CIFAR100 and ImageNet show that model owners can claim with confidence greater than 99% that their model (or dataset as a matter of fact) was stolen, despite only exposing 50 of the stolen model's training points. Dataset inference defends against state-of-the-art attacks even when the adversary is adaptive. Unlike prior work, it does not require retraining or overfitting the defended model.