 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning with Impartiality to Walk on the Pareto Frontier of Fairness, Privacy, and Utility
Paper and Code
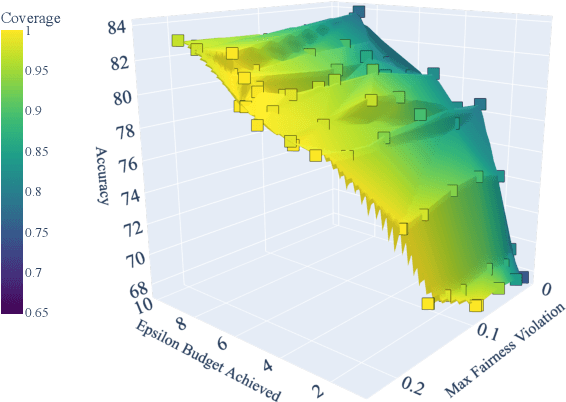
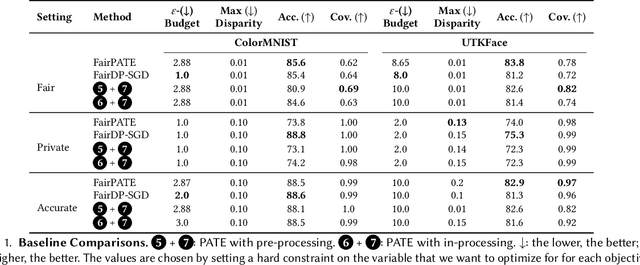

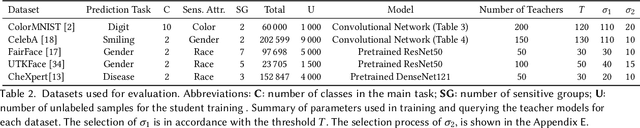
Deploying machine learning (ML) models often requires both fairness and privacy guarantees. Both of these objectives present unique trade-offs with the utility (e.g., accuracy) of the model. However, the mutual interactions between fairness, privacy, and utility are less well-understood. As a result, often only one objective is optimized, while the others are tuned as hyper-parameters. Because they implicitly prioritize certain objectives, such designs bias the model in pernicious, undetectable ways. To address this, we adopt impartiality as a principle: design of ML pipelines should not favor one objective over another. We propose impartially-specified models, which provide us with accurate Pareto frontiers that show the inherent trade-offs between the objectives. Extending two canonical ML frameworks for privacy-preserving learning, we provide two methods (FairDP-SGD and FairPATE) to train impartially-specified models and recover the Pareto frontier. Through theoretical privacy analysis and a comprehensive empirical study, we provide an answer to the question of where fairness mitigation should be integrated within a privacy-aware ML pipeline.