 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLegal Retrieval for Public Defenders
Jan 20, 2026AI tools are increasingly suggested as solutions to assist public agencies with heavy workloads. In public defense, where a constitutional right to counsel meets the complexities of law, overwhelming caseloads and constrained resources, practitioners face especially taxing conditions. Yet, there is little evidence of how AI could meaningfully support defenders' day-to-day work. In partnership with the New Jersey Office of the Public Defender, we develop the NJ BriefBank, a retrieval tool which surfaces relevant appellate briefs to streamline legal research and writing. We show that existing legal retrieval benchmarks fail to transfer to public defense search, however adding domain knowledge improves retrieval quality. This includes query expansion with legal reasoning, domain-specific data and curated synthetic examples. To facilitate further research, we provide a taxonomy of realistic defender search queries and release a manually annotated public defense retrieval dataset. Together, our work offers starting points towards building practical, reliable retrieval AI tools for public defense, and towards more realistic legal retrieval benchmarks.
Regulation Games for Trustworthy Machine Learning
Feb 05, 2024Existing work on trustworthy machine learning (ML) often concentrates on individual aspects of trust, such as fairness or privacy. Additionally, many techniques overlook the distinction between those who train ML models and those responsible for assessing their trustworthiness. To address these issues, we propose a framework that views trustworthy ML as a multi-objective multi-agent optimization problem. This naturally lends itself to a game-theoretic formulation we call regulation games. We illustrate a particular game instance, the SpecGame in which we model the relationship between an ML model builder and fairness and privacy regulators. Regulators wish to design penalties that enforce compliance with their specification, but do not want to discourage builders from participation. Seeking such socially optimal (i.e., efficient for all agents) solutions to the game, we introduce ParetoPlay. This novel equilibrium search algorithm ensures that agents remain on the Pareto frontier of their objectives and avoids the inefficiencies of other equilibria. Simulating SpecGame through ParetoPlay can provide policy guidance for ML Regulation. For instance, we show that for a gender classification application, regulators can enforce a differential privacy budget that is on average 4.0 lower if they take the initiative to specify their desired guarantee first.
Learning with Impartiality to Walk on the Pareto Frontier of Fairness, Privacy, and Utility
Feb 17, 2023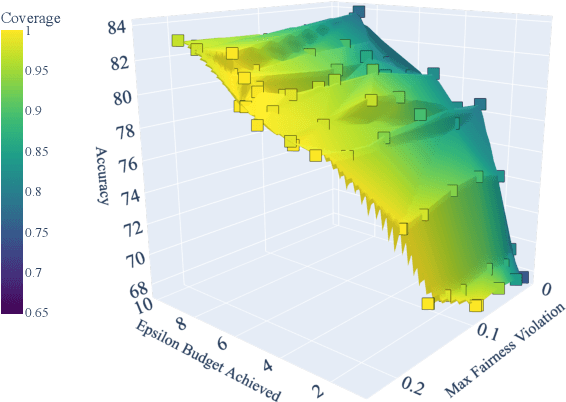
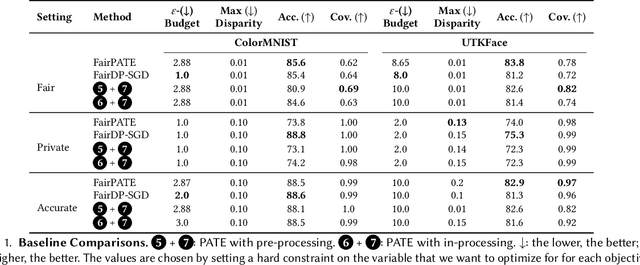

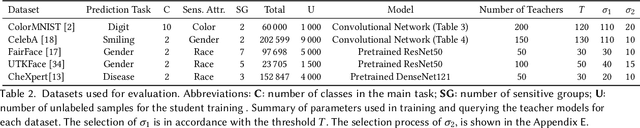
Deploying machine learning (ML) models often requires both fairness and privacy guarantees. Both of these objectives present unique trade-offs with the utility (e.g., accuracy) of the model. However, the mutual interactions between fairness, privacy, and utility are less well-understood. As a result, often only one objective is optimized, while the others are tuned as hyper-parameters. Because they implicitly prioritize certain objectives, such designs bias the model in pernicious, undetectable ways. To address this, we adopt impartiality as a principle: design of ML pipelines should not favor one objective over another. We propose impartially-specified models, which provide us with accurate Pareto frontiers that show the inherent trade-offs between the objectives. Extending two canonical ML frameworks for privacy-preserving learning, we provide two methods (FairDP-SGD and FairPATE) to train impartially-specified models and recover the Pareto frontier. Through theoretical privacy analysis and a comprehensive empirical study, we provide an answer to the question of where fairness mitigation should be integrated within a privacy-aware ML pipeline.