 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretability in Safety-Critical FinancialTrading Systems
Sep 24, 2021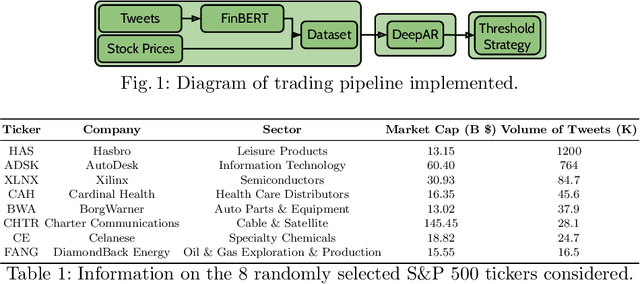
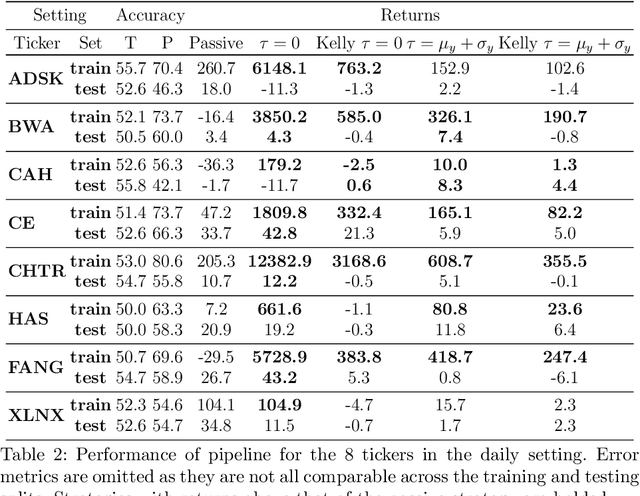
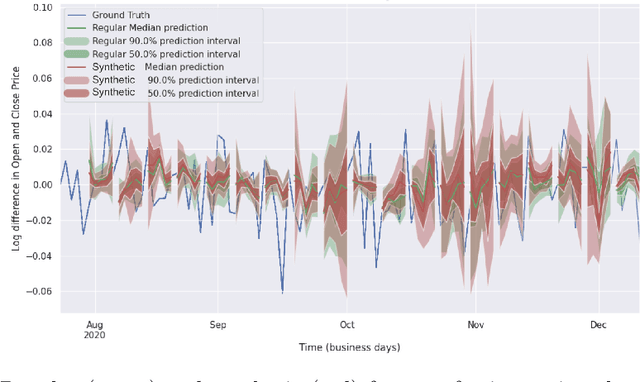
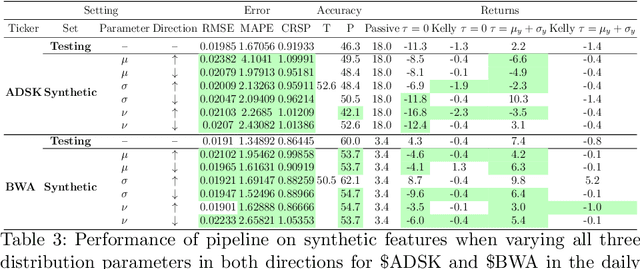
Sophisticated machine learning (ML) models to inform trading in the financial sector create problems of interpretability and risk management. Seemingly robust forecasting models may behave erroneously in out of distribution settings. In 2020, some of the world's most sophisticated quant hedge funds suffered losses as their ML models were first underhedged, and then overcompensated. We implement a gradient-based approach for precisely stress-testing how a trading model's forecasts can be manipulated, and their effects on downstream tasks at the trading execution level. We construct inputs -- whether in changes to sentiment or market variables -- that efficiently affect changes in the return distribution. In an industry-standard trading pipeline, we perturb model inputs for eight S&P 500 stocks. We find our approach discovers seemingly in-sample input settings that result in large negative shifts in return distributions. We provide the financial community with mechanisms to interpret ML forecasts in trading systems. For the security community, we provide a compelling application where studying ML robustness necessitates that one capture an end-to-end system's performance rather than study a ML model in isolation. Indeed, we show in our evaluation that errors in the forecasting model's predictions alone are not sufficient for trading decisions made based on these forecasts to yield a negative return.
SoK: Machine Learning Governance
Sep 20, 2021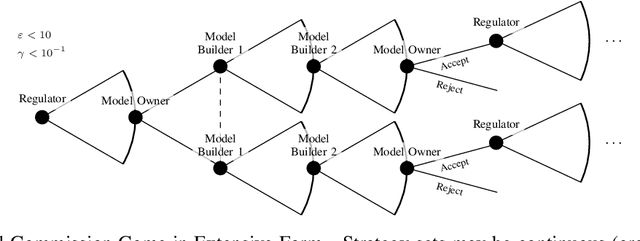
The application of machine learning (ML) in computer systems introduces not only many benefits but also risks to society. In this paper, we develop the concept of ML governance to balance such benefits and risks, with the aim of achieving responsible applications of ML. Our approach first systematizes research towards ascertaining ownership of data and models, thus fostering a notion of identity specific to ML systems. Building on this foundation, we use identities to hold principals accountable for failures of ML systems through both attribution and auditing. To increase trust in ML systems, we then survey techniques for developing assurance, i.e., confidence that the system meets its security requirements and does not exhibit certain known failures. This leads us to highlight the need for techniques that allow a model owner to manage the life cycle of their system, e.g., to patch or retire their ML system. Put altogether, our systematization of knowledge standardizes the interactions between principals involved in the deployment of ML throughout its life cycle. We highlight opportunities for future work, e.g., to formalize the resulting game between ML principals.
On the Exploitability of Audio Machine Learning Pipelines to Surreptitious Adversarial Examples
Aug 03, 2021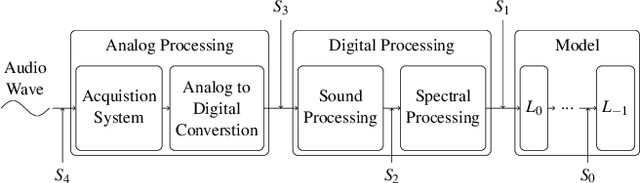
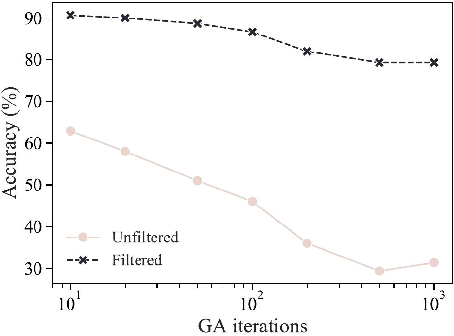
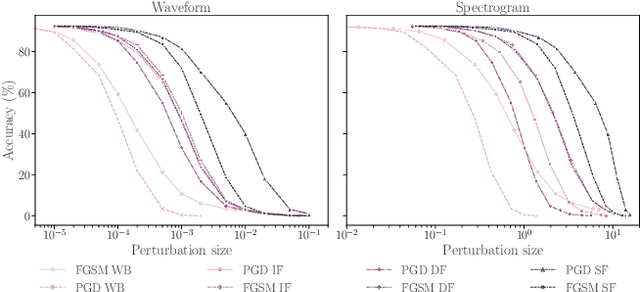

Machine learning (ML) models are known to be vulnerable to adversarial examples. Applications of ML to voice biometrics authentication are no exception. Yet, the implications of audio adversarial examples on these real-world systems remain poorly understood given that most research targets limited defenders who can only listen to the audio samples. Conflating detectability of an attack with human perceptibility, research has focused on methods that aim to produce imperceptible adversarial examples which humans cannot distinguish from the corresponding benign samples. We argue that this perspective is coarse for two reasons: 1. Imperceptibility is impossible to verify; it would require an experimental process that encompasses variations in listener training, equipment, volume, ear sensitivity, types of background noise etc, and 2. It disregards pipeline-based detection clues that realistic defenders leverage. This results in adversarial examples that are ineffective in the presence of knowledgeable defenders. Thus, an adversary only needs an audio sample to be plausible to a human. We thus introduce surreptitious adversarial examples, a new class of attacks that evades both human and pipeline controls. In the white-box setting, we instantiate this class with a joint, multi-stage optimization attack. Using an Amazon Mechanical Turk user study, we show that this attack produces audio samples that are more surreptitious than previous attacks that aim solely for imperceptibility. Lastly we show that surreptitious adversarial examples are challenging to develop in the black-box setting.
Machine Unlearning
Dec 09, 2019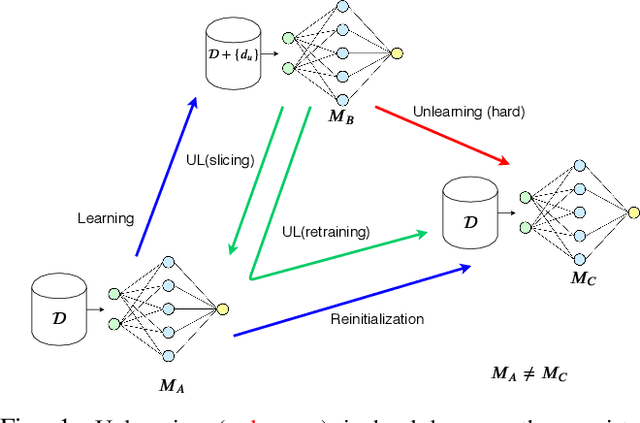
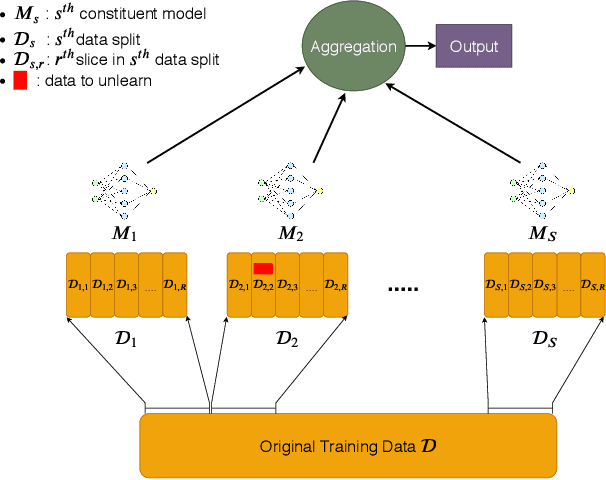
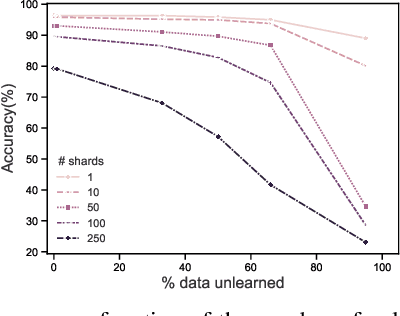
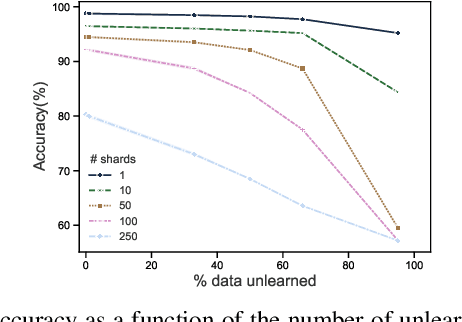
Once users have shared their data online, it is generally difficult for them to revoke access and ask for the data to be deleted. Machine learning (ML) exacerbates this problem because any model trained with said data may have memorized it, putting users at risk of a successful privacy attack exposing their information. Yet, having models unlearn is notoriously difficult. After a data point is removed from a training set, one often resorts to entirely retraining downstream models from scratch. We introduce SISA training, a framework that decreases the number of model parameters affected by an unlearning request and caches intermediate outputs of the training algorithm to limit the number of model updates that need to be computed to have these parameters unlearn. This framework reduces the computational overhead associated with unlearning, even in the worst-case setting where unlearning requests are made uniformly across the training set. In some cases, we may have a prior on the distribution of unlearning requests that will be issued by users. We may take this prior into account to partition and order data accordingly and further decrease overhead from unlearning. Our evaluation spans two datasets from different application domains, with corresponding motivations for unlearning. Under no distributional assumptions, we observe that SISA training improves unlearning for the Purchase dataset by 3.13x, and 1.658x for the SVHN dataset, over retraining from scratch. We also validate how knowledge of the unlearning distribution provides further improvements in retraining time by simulating a scenario where we model unlearning requests that come from users of a commercial product that is available in countries with varying sensitivity to privacy. Our work contributes to practical data governance in machine learning.