 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Diffusion Duality
Jun 12, 2025Uniform-state discrete diffusion models hold the promise of fast text generation due to their inherent ability to self-correct. However, they are typically outperformed by autoregressive models and masked diffusion models. In this work, we narrow this performance gap by leveraging a key insight: Uniform-state diffusion processes naturally emerge from an underlying Gaussian diffusion. Our method, Duo, transfers powerful techniques from Gaussian diffusion to improve both training and sampling. First, we introduce a curriculum learning strategy guided by the Gaussian process, doubling training speed by reducing variance. Models trained with curriculum learning surpass autoregressive models in zero-shot perplexity on 3 of 7 benchmarks. Second, we present Discrete Consistency Distillation, which adapts consistency distillation from the continuous to the discrete setting. This algorithm unlocks few-step generation in diffusion language models by accelerating sampling by two orders of magnitude. We provide the code and model checkpoints on the project page: http://s-sahoo.github.io/duo
Simple Guidance Mechanisms for Discrete Diffusion Models
Dec 13, 2024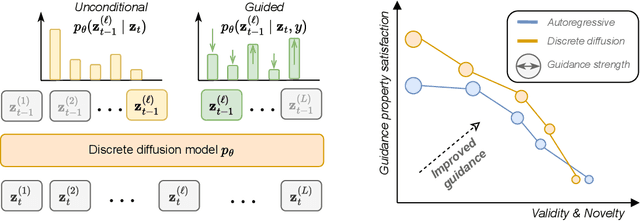
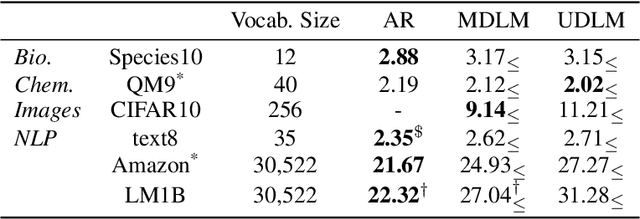
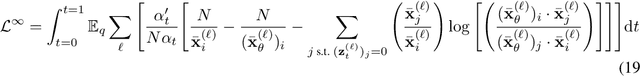
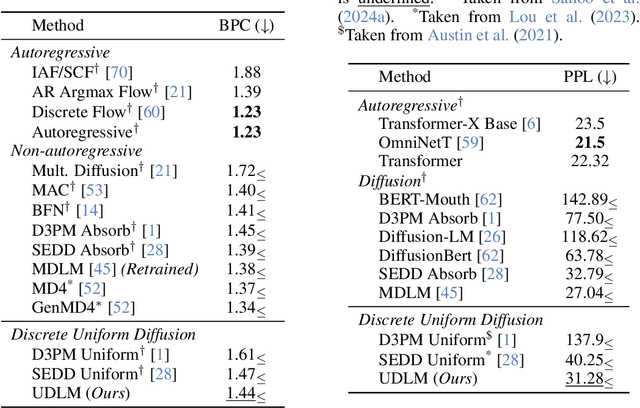
Diffusion models for continuous data gained widespread adoption owing to their high quality generation and control mechanisms. However, controllable diffusion on discrete data faces challenges given that continuous guidance methods do not directly apply to discrete diffusion. Here, we provide a straightforward derivation of classifier-free and classifier-based guidance for discrete diffusion, as well as a new class of diffusion models that leverage uniform noise and that are more guidable because they can continuously edit their outputs. We improve the quality of these models with a novel continuous-time variational lower bound that yields state-of-the-art performance, especially in settings involving guidance or fast generation. Empirically, we demonstrate that our guidance mechanisms combined with uniform noise diffusion improve controllable generation relative to autoregressive and diffusion baselines on several discrete data domains, including genomic sequences, small molecule design, and discretized image generation.
Language-Assisted 3D Feature Learning for Semantic Scene Understanding
Dec 11, 2022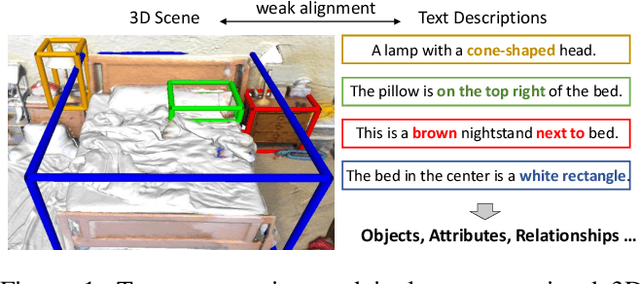

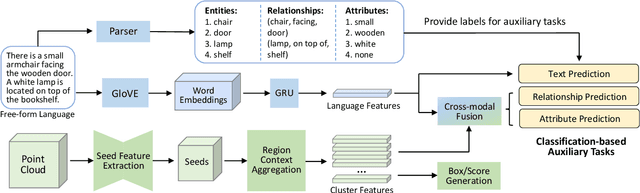

Learning descriptive 3D features is crucial for understanding 3D scenes with diverse objects and complex structures. However, it is usually unknown whether important geometric attributes and scene context obtain enough emphasis in an end-to-end trained 3D scene understanding network. To guide 3D feature learning toward important geometric attributes and scene context, we explore the help of textual scene descriptions. Given some free-form descriptions paired with 3D scenes, we extract the knowledge regarding the object relationships and object attributes. We then inject the knowledge to 3D feature learning through three classification-based auxiliary tasks. This language-assisted training can be combined with modern object detection and instance segmentation methods to promote 3D semantic scene understanding, especially in a label-deficient regime. Moreover, the 3D feature learned with language assistance is better aligned with the language features, which can benefit various 3D-language multimodal tasks. Experiments on several benchmarks of 3D-only and 3D-language tasks demonstrate the effectiveness of our language-assisted 3D feature learning. Code is available at https://github.com/Asterisci/Language-Assisted-3D.
On the Exploitability of Audio Machine Learning Pipelines to Surreptitious Adversarial Examples
Aug 03, 2021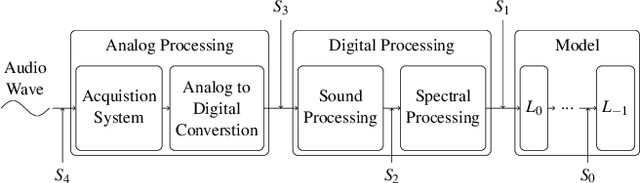
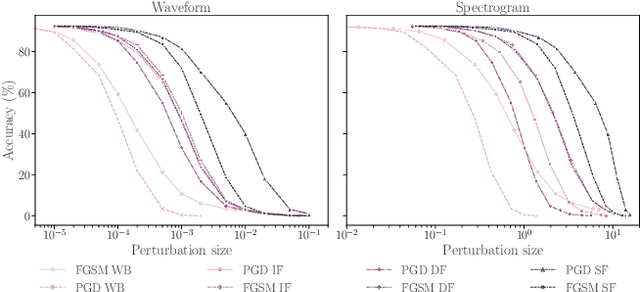

Machine learning (ML) models are known to be vulnerable to adversarial examples. Applications of ML to voice biometrics authentication are no exception. Yet, the implications of audio adversarial examples on these real-world systems remain poorly understood given that most research targets limited defenders who can only listen to the audio samples. Conflating detectability of an attack with human perceptibility, research has focused on methods that aim to produce imperceptible adversarial examples which humans cannot distinguish from the corresponding benign samples. We argue that this perspective is coarse for two reasons: 1. Imperceptibility is impossible to verify; it would require an experimental process that encompasses variations in listener training, equipment, volume, ear sensitivity, types of background noise etc, and 2. It disregards pipeline-based detection clues that realistic defenders leverage. This results in adversarial examples that are ineffective in the presence of knowledgeable defenders. Thus, an adversary only needs an audio sample to be plausible to a human. We thus introduce surreptitious adversarial examples, a new class of attacks that evades both human and pipeline controls. In the white-box setting, we instantiate this class with a joint, multi-stage optimization attack. Using an Amazon Mechanical Turk user study, we show that this attack produces audio samples that are more surreptitious than previous attacks that aim solely for imperceptibility. Lastly we show that surreptitious adversarial examples are challenging to develop in the black-box setting.