 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2: Open Agentic Intelligence
Jul 28, 2025



We introduce Kimi K2, a Mixture-of-Experts (MoE) large language model with 32 billion activated parameters and 1 trillion total parameters. We propose the MuonClip optimizer, which improves upon Muon with a novel QK-clip technique to address training instability while enjoying the advanced token efficiency of Muon. Based on MuonClip, K2 was pre-trained on 15.5 trillion tokens with zero loss spike. During post-training, K2 undergoes a multi-stage post-training process, highlighted by a large-scale agentic data synthesis pipeline and a joint reinforcement learning (RL) stage, where the model improves its capabilities through interactions with real and synthetic environments. Kimi K2 achieves state-of-the-art performance among open-source non-thinking models, with strengths in agentic capabilities. Notably, K2 obtains 66.1 on Tau2-Bench, 76.5 on ACEBench (En), 65.8 on SWE-Bench Verified, and 47.3 on SWE-Bench Multilingual -- surpassing most open and closed-sourced baselines in non-thinking settings. It also exhibits strong capabilities in coding, mathematics, and reasoning tasks, with a score of 53.7 on LiveCodeBench v6, 49.5 on AIME 2025, 75.1 on GPQA-Diamond, and 27.1 on OJBench, all without extended thinking. These results position Kimi K2 as one of the most capable open-source large language models to date, particularly in software engineering and agentic tasks. We release our base and post-trained model checkpoints to facilitate future research and applications of agentic intelligence.
Syno: Structured Synthesis for Neural Operators
Oct 31, 2024The desires for better prediction accuracy and higher execution performance in neural networks never end. Neural architecture search (NAS) and tensor compilers are two popular techniques to optimize these two goals, but they are both limited to composing or optimizing existing manually designed operators rather than coming up with completely new designs. In this work, we explore the less studied direction of neural operator synthesis, which aims to automatically and efficiently discover novel neural operators with better accuracy and/or speed. We develop an end-to-end framework Syno, to realize practical neural operator synthesis. Syno makes use of a novel set of fine-grained primitives defined on tensor dimensions, which ensure various desired properties to ease model training, and also enable expression canonicalization techniques to avoid redundant candidates during search. Syno further adopts a novel guided synthesis flow to obtain valid operators matched with the specified input/output dimension sizes, and leverages efficient stochastic tree search algorithms to quickly explore the design space. We demonstrate that Syno discovers better operators with an average of $2.06\times$ speedup and less than $1\%$ accuracy loss, even on NAS-optimized models.
Language-Assisted 3D Feature Learning for Semantic Scene Understanding
Dec 11, 2022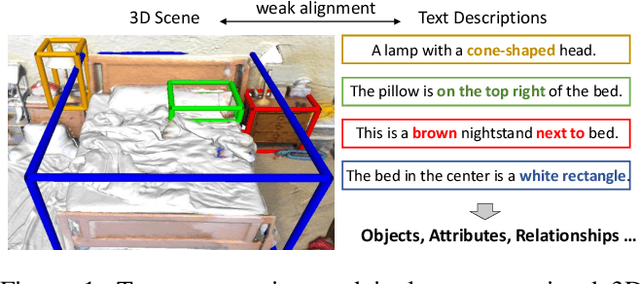

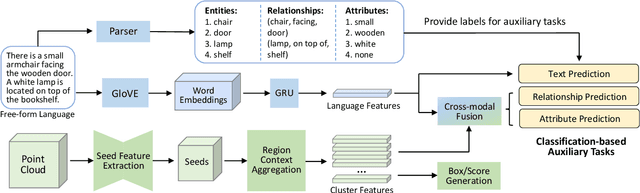

Learning descriptive 3D features is crucial for understanding 3D scenes with diverse objects and complex structures. However, it is usually unknown whether important geometric attributes and scene context obtain enough emphasis in an end-to-end trained 3D scene understanding network. To guide 3D feature learning toward important geometric attributes and scene context, we explore the help of textual scene descriptions. Given some free-form descriptions paired with 3D scenes, we extract the knowledge regarding the object relationships and object attributes. We then inject the knowledge to 3D feature learning through three classification-based auxiliary tasks. This language-assisted training can be combined with modern object detection and instance segmentation methods to promote 3D semantic scene understanding, especially in a label-deficient regime. Moreover, the 3D feature learned with language assistance is better aligned with the language features, which can benefit various 3D-language multimodal tasks. Experiments on several benchmarks of 3D-only and 3D-language tasks demonstrate the effectiveness of our language-assisted 3D feature learning. Code is available at https://github.com/Asterisci/Language-Assisted-3D.