 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Continual Instruction Tuning with Dynamic Gradient Guidance
Nov 19, 2025



Multimodal continual instruction tuning enables multimodal large language models to sequentially adapt to new tasks while building upon previously acquired knowledge. However, this continual learning paradigm faces the significant challenge of catastrophic forgetting, where learning new tasks leads to performance degradation on previous ones. In this paper, we introduce a novel insight into catastrophic forgetting by conceptualizing it as a problem of missing gradients from old tasks during new task learning. Our approach approximates these missing gradients by leveraging the geometric properties of the parameter space, specifically using the directional vector between current parameters and previously optimal parameters as gradient guidance. This approximated gradient can be further integrated with real gradients from a limited replay buffer and regulated by a Bernoulli sampling strategy that dynamically balances model stability and plasticity. Extensive experiments on multimodal continual instruction tuning datasets demonstrate that our method achieves state-of-the-art performance without model expansion, effectively mitigating catastrophic forgetting while maintaining a compact architecture.
Twilight: Adaptive Attention Sparsity with Hierarchical Top-$p$ Pruning
Feb 06, 2025



Leveraging attention sparsity to accelerate long-context large language models (LLMs) has been a hot research topic. However, current algorithms such as sparse attention or key-value (KV) cache compression tend to use a fixed budget, which presents a significant challenge during deployment because it fails to account for the dynamic nature of real-world scenarios, where the optimal balance between accuracy and efficiency can vary greatly. In this paper, we find that borrowing top-$p$ sampling (nucleus sampling) to sparse attention can surprisingly achieve adaptive budgeting. Based on this, we propose Twilight, a framework to bring adaptive sparsity to any existing sparse attention algorithm without sacrificing their accuracy. Empirical results show that Twilight can adaptively prune at most 98% of redundant tokens, leading to $15.4\times$ acceleration in self-attention operations and $3.9\times$ acceleration in end-to-end per token latency in long context LLM decoding.
FastSwitch: Optimizing Context Switching Efficiency in Fairness-aware Large Language Model Serving
Nov 27, 2024



Serving numerous users and requests concurrently requires good fairness in Large Language Models (LLMs) serving system. This ensures that, at the same cost, the system can meet the Service Level Objectives (SLOs) of more users , such as time to first token (TTFT) and time between tokens (TBT), rather than allowing a few users to experience performance far exceeding the SLOs. To achieve better fairness, the preemption-based scheduling policy dynamically adjusts the priority of each request to maintain balance during runtime. However, existing systems tend to overly prioritize throughput, overlooking the overhead caused by preemption-induced context switching, which is crucial for maintaining fairness through priority adjustments. In this work, we identify three main challenges that result in this overhead. 1) Inadequate I/O utilization. 2) GPU idleness. 3) Unnecessary I/O transmission during multi-turn conversations. Our key insight is that the block-based KV cache memory policy in existing systems, while achieving near-zero memory waste, leads to discontinuity and insufficient granularity in the KV cache memory. To respond, we introduce FastSwitch, a fairness-aware serving system that not only aligns with existing KV cache memory allocation policy but also mitigates context switching overhead. Our evaluation shows that FastSwitch outperforms the state-of-the-art LLM serving system vLLM with speedups of 1.4-11.2x across different tail TTFT and TBT.
Syno: Structured Synthesis for Neural Operators
Oct 31, 2024The desires for better prediction accuracy and higher execution performance in neural networks never end. Neural architecture search (NAS) and tensor compilers are two popular techniques to optimize these two goals, but they are both limited to composing or optimizing existing manually designed operators rather than coming up with completely new designs. In this work, we explore the less studied direction of neural operator synthesis, which aims to automatically and efficiently discover novel neural operators with better accuracy and/or speed. We develop an end-to-end framework Syno, to realize practical neural operator synthesis. Syno makes use of a novel set of fine-grained primitives defined on tensor dimensions, which ensure various desired properties to ease model training, and also enable expression canonicalization techniques to avoid redundant candidates during search. Syno further adopts a novel guided synthesis flow to obtain valid operators matched with the specified input/output dimension sizes, and leverages efficient stochastic tree search algorithms to quickly explore the design space. We demonstrate that Syno discovers better operators with an average of $2.06\times$ speedup and less than $1\%$ accuracy loss, even on NAS-optimized models.
KAPLA: Pragmatic Representation and Fast Solving of Scalable NN Accelerator Dataflow
Jun 09, 2023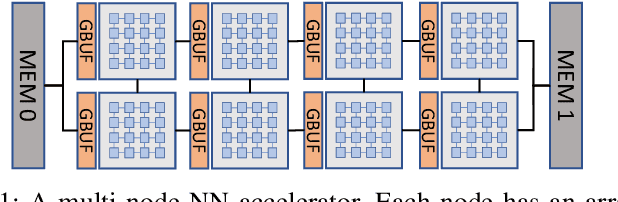
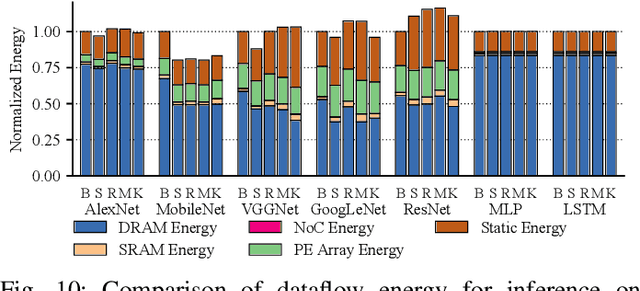
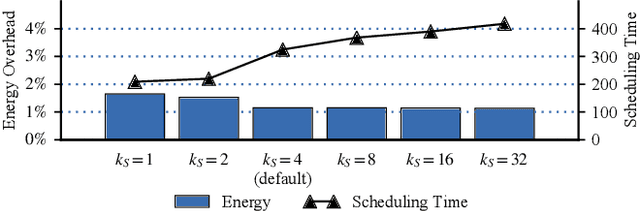
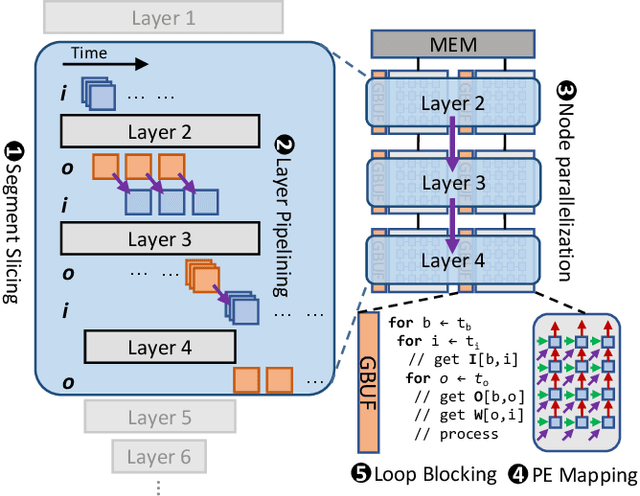
Dataflow scheduling decisions are of vital importance to neural network (NN) accelerators. Recent scalable NN accelerators support a rich set of advanced dataflow techniques. The problems of comprehensively representing and quickly finding optimized dataflow schemes thus become significantly more complicated and challenging. In this work, we first propose comprehensive and pragmatic dataflow representations for temporal and spatial scheduling on scalable multi-node NN architectures. An informal hierarchical taxonomy highlights the tight coupling across different levels of the dataflow space as the major difficulty for fast design exploration. A set of formal tensor-centric directives accurately express various inter-layer and intra-layer schemes, and allow for quickly determining their validity and efficiency. We then build a generic, optimized, and fast dataflow solver, KAPLA, which makes use of the pragmatic directives to explore the design space with effective validity check and efficiency estimation. KAPLA decouples the upper inter-layer level for fast pruning, and solves the lower intra-layer schemes with a novel bottom-up cost descending method. KAPLA achieves within only 2.2% and 7.7% energy overheads on the result dataflow for training and inference, respectively, compared to the exhaustively searched optimal schemes. It also outperforms random and machine-learning-based approaches, with more optimized results and orders of magnitude faster search speedup.
OSP2B: One-Stage Point-to-Box Network for 3D Siamese Tracking
Apr 23, 2023Two-stage point-to-box network acts as a critical role in the recent popular 3D Siamese tracking paradigm, which first generates proposals and then predicts corresponding proposal-wise scores. However, such a network suffers from tedious hyper-parameter tuning and task misalignment, limiting the tracking performance. Towards these concerns, we propose a simple yet effective one-stage point-to-box network for point cloud-based 3D single object tracking. It synchronizes 3D proposal generation and center-ness score prediction by a parallel predictor without tedious hyper-parameters. To guide a task-aligned score ranking of proposals, a center-aware focal loss is proposed to supervise the training of the center-ness branch, which enhances the network's discriminative ability to distinguish proposals of different quality. Besides, we design a binary target classifier to identify target-relevant points. By integrating the derived classification scores with the center-ness scores, the resulting network can effectively suppress interference proposals and further mitigate task misalignment. Finally, we present a novel one-stage Siamese tracker OSP2B equipped with the designed network. Extensive experiments on challenging benchmarks including KITTI and Waymo SOT Dataset show that our OSP2B achieves leading performance with a considerable real-time speed.
Canvas: End-to-End Kernel Architecture Search in Neural Networks
Apr 18, 2023The demands for higher performance and accuracy in neural networks (NNs) never end. Existing tensor compilation and Neural Architecture Search (NAS) techniques orthogonally optimize the two goals but actually share many similarities in their concrete strategies. We exploit such opportunities by combining the two into one and make a case for Kernel Architecture Search (KAS). KAS reviews NAS from a system perspective and zooms into a more fine-grained level to generate neural kernels with both high performance and good accuracy. To demonstrate the potential of KAS, we build an end-to-end framework, Canvas, to find high-quality kernels as convolution replacements. Canvas samples from a rich set of fine-grained primitives to stochastically and iteratively construct new kernels and evaluate them according to user-specified constraints. Canvas supports freely adjustable tensor dimension sizes inside the kernel and uses two levels of solvers to satisfy structural legality and fully utilize model budgets. The evaluation shows that by replacing standard convolutions with generated new kernels in common NNs, Canvas achieves average 1.5x speedups compared to the previous state-of-the-art with acceptable accuracy loss and search efficiency. Canvas verifies the practicability of KAS by rediscovering many manually designed kernels in the past and producing new structures that may inspire future machine learning innovations. For source code and implementation, we open-sourced Canvas at https://github.com/tsinghua-ideal/Canvas.
GLT-T++: Global-Local Transformer for 3D Siamese Tracking with Ranking Loss
Apr 01, 2023Siamese trackers based on 3D region proposal network (RPN) have shown remarkable success with deep Hough voting. However, using a single seed point feature as the cue for voting fails to produce high-quality 3D proposals. Additionally, the equal treatment of seed points in the voting process, regardless of their significance, exacerbates this limitation. To address these challenges, we propose a novel transformer-based voting scheme to generate better proposals. Specifically, a global-local transformer (GLT) module is devised to integrate object- and patch-aware geometric priors into seed point features, resulting in robust and accurate cues for offset learning of seed points. To train the GLT module, we introduce an importance prediction branch that learns the potential importance weights of seed points as a training constraint. Incorporating this transformer-based voting scheme into 3D RPN, a novel Siamese method dubbed GLT-T is developed for 3D single object tracking on point clouds. Moreover, we identify that the highest-scored proposal in the Siamese paradigm may not be the most accurate proposal, which limits tracking performance. Towards this concern, we approach the binary score prediction task as a ranking problem, and design a target-aware ranking loss and a localization-aware ranking loss to produce accurate ranking of proposals. With the ranking losses, we further present GLT-T++, an enhanced version of GLT-T. Extensive experiments on multiple benchmarks demonstrate that our GLT-T and GLT-T++ outperform state-of-the-art methods in terms of tracking accuracy while maintaining a real-time inference speed. The source code will be made available at https://github.com/haooozi/GLT-T.
GLT-T: Global-Local Transformer Voting for 3D Single Object Tracking in Point Clouds
Nov 20, 2022Current 3D single object tracking methods are typically based on VoteNet, a 3D region proposal network. Despite the success, using a single seed point feature as the cue for offset learning in VoteNet prevents high-quality 3D proposals from being generated. Moreover, seed points with different importance are treated equally in the voting process, aggravating this defect. To address these issues, we propose a novel global-local transformer voting scheme to provide more informative cues and guide the model pay more attention on potential seed points, promoting the generation of high-quality 3D proposals. Technically, a global-local transformer (GLT) module is employed to integrate object- and patch-aware prior into seed point features to effectively form strong feature representation for geometric positions of the seed points, thus providing more robust and accurate cues for offset learning. Subsequently, a simple yet effective training strategy is designed to train the GLT module. We develop an importance prediction branch to learn the potential importance of the seed points and treat the output weights vector as a training constraint term. By incorporating the above components together, we exhibit a superior tracking method GLT-T. Extensive experiments on challenging KITTI and NuScenes benchmarks demonstrate that GLT-T achieves state-of-the-art performance in the 3D single object tracking task. Besides, further ablation studies show the advantages of the proposed global-local transformer voting scheme over the original VoteNet. Code and models will be available at https://github.com/haooozi/GLT-T.
Learning Localization-aware Target Confidence for Siamese Visual Tracking
Apr 29, 2022
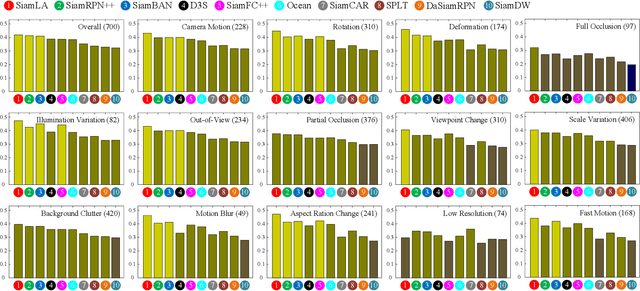


Siamese tracking paradigm has achieved great success, providing effective appearance discrimination and size estimation by the classification and regression. While such a paradigm typically optimizes the classification and regression independently, leading to task misalignment (accurate prediction boxes have no high target confidence scores). In this paper, to alleviate this misalignment, we propose a novel tracking paradigm, called SiamLA. Within this paradigm, a series of simple, yet effective localization-aware components are introduced, to generate localization-aware target confidence scores. Specifically, with the proposed localization-aware dynamic label (LADL) loss and localization-aware label smoothing (LALS) strategy, collaborative optimization between the classification and regression is achieved, enabling classification scores to be aware of location state, not just appearance similarity. Besides, we propose a separate localization branch, centered on a localization-aware feature aggregation (LAFA) module, to produce location quality scores to further modify the classification scores. Consequently, the resulting target confidence scores, are more discriminative for the location state, allowing accurate prediction boxes tend to be predicted as high scores. Extensive experiments are conducted on six challenging benchmarks, including GOT-10k, TrackingNet, LaSOT, TNL2K, OTB100 and VOT2018. Our SiamLA achieves state-of-the-art performance in terms of both accuracy and efficiency. Furthermore, a stability analysis reveals that our tracking paradigm is relatively stable, implying the paradigm is potential to real-world applications.