 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Challenges of LLMs in Real-world Medical Follow-up: A Comparative Study and An Optimized Framework
Dec 22, 2025When applied directly in an end-to-end manner to medical follow-up tasks, Large Language Models (LLMs) often suffer from uncontrolled dialog flow and inaccurate information extraction due to the complexity of follow-up forms. To address this limitation, we designed and compared two follow-up chatbot systems: an end-to-end LLM-based system (control group) and a modular pipeline with structured process control (experimental group). Experimental results show that while the end-to-end approach frequently fails on lengthy and complex forms, our modular method-built on task decomposition, semantic clustering, and flow management-substantially improves dialog stability and extraction accuracy. Moreover, it reduces the number of dialogue turns by 46.73% and lowers token consumption by 80% to 87.5%. These findings highlight the necessity of integrating external control mechanisms when deploying LLMs in high-stakes medical follow-up scenarios.
VoxelTrack: Exploring Voxel Representation for 3D Point Cloud Object Tracking
Aug 05, 2024Current LiDAR point cloud-based 3D single object tracking (SOT) methods typically rely on point-based representation network. Despite demonstrated success, such networks suffer from some fundamental problems: 1) It contains pooling operation to cope with inherently disordered point clouds, hindering the capture of 3D spatial information that is useful for tracking, a regression task. 2) The adopted set abstraction operation hardly handles density-inconsistent point clouds, also preventing 3D spatial information from being modeled. To solve these problems, we introduce a novel tracking framework, termed VoxelTrack. By voxelizing inherently disordered point clouds into 3D voxels and extracting their features via sparse convolution blocks, VoxelTrack effectively models precise and robust 3D spatial information, thereby guiding accurate position prediction for tracked objects. Moreover, VoxelTrack incorporates a dual-stream encoder with cross-iterative feature fusion module to further explore fine-grained 3D spatial information for tracking. Benefiting from accurate 3D spatial information being modeled, our VoxelTrack simplifies tracking pipeline with a single regression loss. Extensive experiments are conducted on three widely-adopted datasets including KITTI, NuScenes and Waymo Open Dataset. The experimental results confirm that VoxelTrack achieves state-of-the-art performance (88.3%, 71.4% and 63.6% mean precision on the three datasets, respectively), and outperforms the existing trackers with a real-time speed of 36 Fps on a single TITAN RTX GPU. The source code and model will be released.
Towards Category Unification of 3D Single Object Tracking on Point Clouds
Jan 20, 2024Category-specific models are provenly valuable methods in 3D single object tracking (SOT) regardless of Siamese or motion-centric paradigms. However, such over-specialized model designs incur redundant parameters, thus limiting the broader applicability of 3D SOT task. This paper first introduces unified models that can simultaneously track objects across all categories using a single network with shared model parameters. Specifically, we propose to explicitly encode distinct attributes associated to different object categories, enabling the model to adapt to cross-category data. We find that the attribute variances of point cloud objects primarily occur from the varying size and shape (e.g., large and square vehicles v.s. small and slender humans). Based on this observation, we design a novel point set representation learning network inheriting transformer architecture, termed AdaFormer, which adaptively encodes the dynamically varying shape and size information from cross-category data in a unified manner. We further incorporate the size and shape prior derived from the known template targets into the model's inputs and learning objective, facilitating the learning of unified representation. Equipped with such designs, we construct two category-unified models SiamCUT and MoCUT.Extensive experiments demonstrate that SiamCUT and MoCUT exhibit strong generalization and training stability. Furthermore, our category-unified models outperform the category-specific counterparts by a significant margin (e.g., on KITTI dataset, 12% and 3% performance gains on the Siamese and motion paradigms). Our code will be available.
GLT-T++: Global-Local Transformer for 3D Siamese Tracking with Ranking Loss
Apr 01, 2023Siamese trackers based on 3D region proposal network (RPN) have shown remarkable success with deep Hough voting. However, using a single seed point feature as the cue for voting fails to produce high-quality 3D proposals. Additionally, the equal treatment of seed points in the voting process, regardless of their significance, exacerbates this limitation. To address these challenges, we propose a novel transformer-based voting scheme to generate better proposals. Specifically, a global-local transformer (GLT) module is devised to integrate object- and patch-aware geometric priors into seed point features, resulting in robust and accurate cues for offset learning of seed points. To train the GLT module, we introduce an importance prediction branch that learns the potential importance weights of seed points as a training constraint. Incorporating this transformer-based voting scheme into 3D RPN, a novel Siamese method dubbed GLT-T is developed for 3D single object tracking on point clouds. Moreover, we identify that the highest-scored proposal in the Siamese paradigm may not be the most accurate proposal, which limits tracking performance. Towards this concern, we approach the binary score prediction task as a ranking problem, and design a target-aware ranking loss and a localization-aware ranking loss to produce accurate ranking of proposals. With the ranking losses, we further present GLT-T++, an enhanced version of GLT-T. Extensive experiments on multiple benchmarks demonstrate that our GLT-T and GLT-T++ outperform state-of-the-art methods in terms of tracking accuracy while maintaining a real-time inference speed. The source code will be made available at https://github.com/haooozi/GLT-T.
Dual-space Compressed Sensing
Jul 15, 2022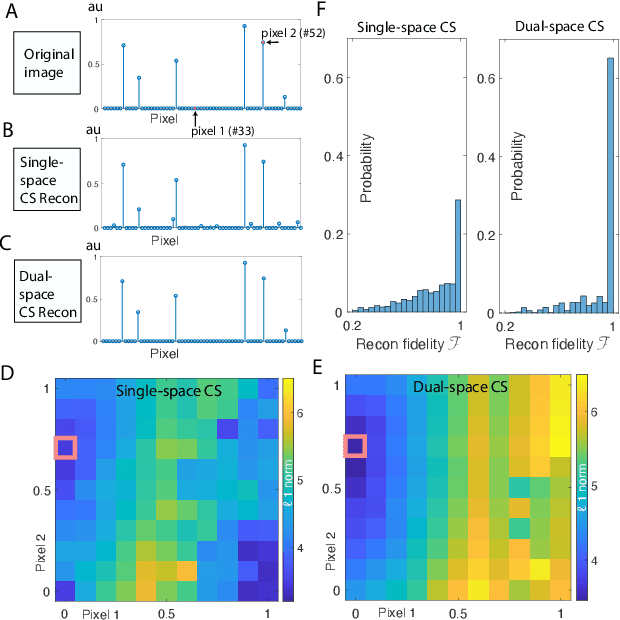
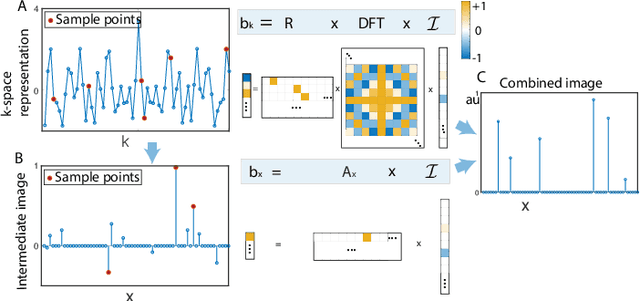
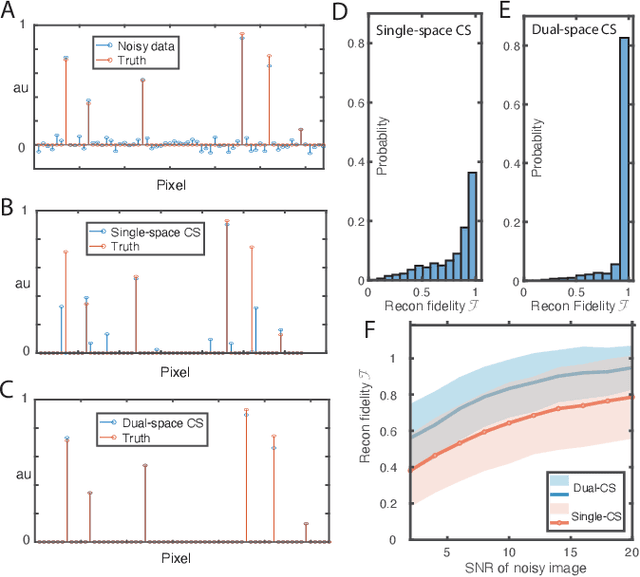
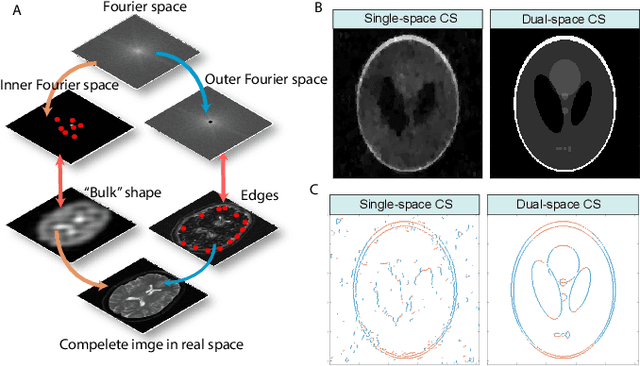
Compressed sensing (CS) is a powerful method routinely employed to accelerate image acquisition. It is particularly suited to situations when the image under consideration is sparse but can be sampled in a basis where it is non-sparse. Here we propose an alternate CS regime in situations where the image can be sampled in two incoherent spaces simultaneously, with a special focus on image sampling in Fourier reciprocal spaces (e.g. real-space and k-space). Information is fed-forward from one space to the other, allowing new opportunities to efficiently solve the optimization problem at the heart of CS image reconstruction. We show that considerable gains in imaging acceleration are then possible over conventional CS. The technique provides enhanced robustness to noise, and is well suited to edge-detection problems. We envision applications for imaging collections of nanodiamond (ND) particles targeting specific regions in a volume of interest, exploiting the ability of lattice defects (NV centers) to allow ND particles to be imaged in reciprocal spaces simultaneously via optical fluorescence and 13C magnetic resonance imaging (MRI) respectively. Broadly this work suggests the potential to interface CS principles with hybrid sampling strategies to yield speedup in signal acquisition in many practical settings.
CFNet: LiDAR-Camera Registration Using Calibration Flow Network
Apr 24, 2021
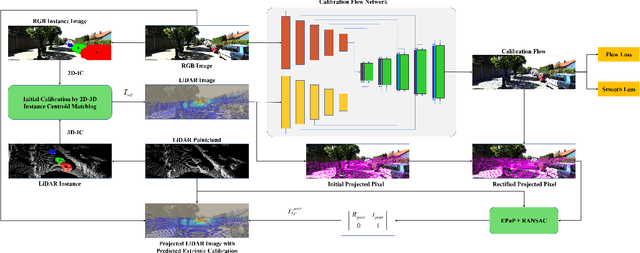
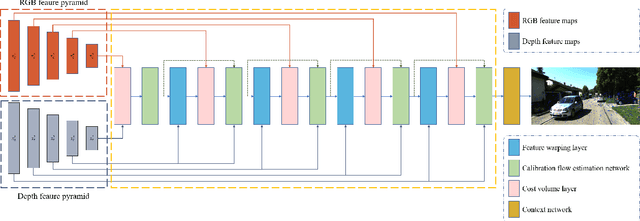

As an essential procedure of data fusion, LiDAR-camera calibration is critical for autonomous vehicles and robot navigation. Most calibration methods rely on hand-crafted features and require significant amounts of extracted features or specific calibration targets. With the development of deep learning (DL) techniques, some attempts take advantage of convolutional neural networks (CNNs) to regress the 6 degrees of freedom (DOF) extrinsic parameters. Nevertheless, the performance of these DL-based methods is reported to be worse than the non-DL methods. This paper proposed an online LiDAR-camera extrinsic calibration algorithm that combines the DL and the geometry methods. We define a two-channel image named calibration flow to illustrate the deviation from the initial projection to the ground truth. EPnP algorithm within the RANdom SAmple Consensus (RANSAC) scheme is applied to estimate the extrinsic parameters with 2D-3D correspondences constructed by the calibration flow. Experiments on KITTI datasets demonstrate that our proposed method is superior to the state-of-the-art methods. Furthermore, we propose a semantic initialization algorithm with the introduction of instance centroids (ICs). The code will be publicly available at https://github.com/LvXudong-HIT/CFNet.
Lidar and Camera Self-Calibration using CostVolume Network
Dec 27, 2020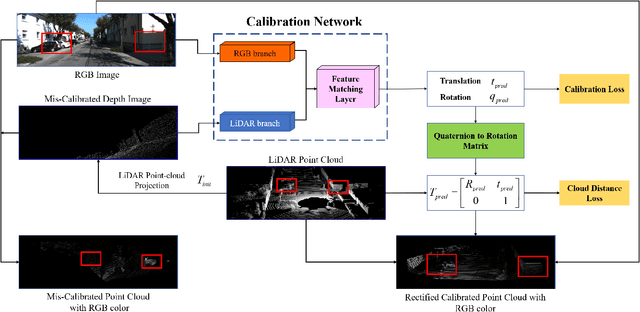
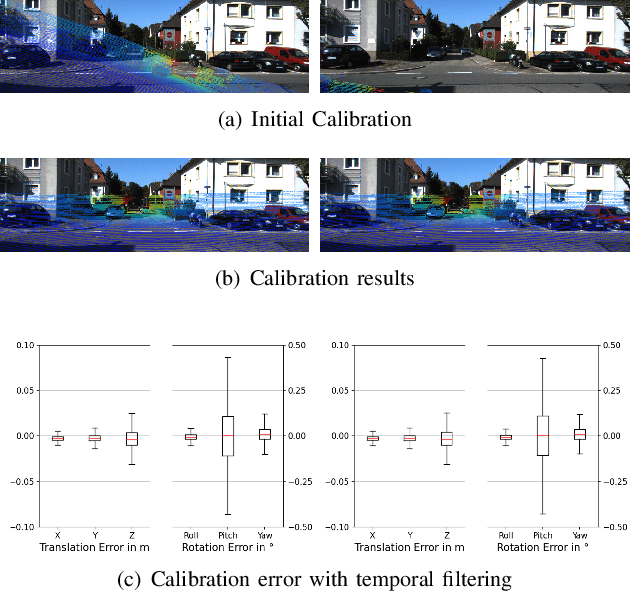


In this paper, we propose a novel online self-calibration approach for Light Detection and Ranging (LiDAR) and camera sensors. Compared to the previous CNN-based methods that concatenate the feature maps of the RGB image and decalibrated depth image, we exploit the cost volume inspired by the PWC-Net for feature matching. Besides the smooth L1-Loss of the predicted extrinsic calibration parameters, an additional point cloud loss is applied. Instead of regress the extrinsic parameters between LiDAR and camera directly, we predict the decalibrated deviation from initial calibration to the ground truth. During inference, the calibration error decreases further with the usage of iterative refinement and the temporal filtering approach. The evaluation results on the KITTI dataset illustrate that our approach outperforms CNN-based state-of-the-art methods in terms of a mean absolute calibration error of 0.297cm in translation and 0.017{\deg} in rotation with miscalibration magnitudes of up to 1.5m and 20{\deg}.
Semantic Flow-guided Motion Removal Method for Robust Mapping
Oct 14, 2020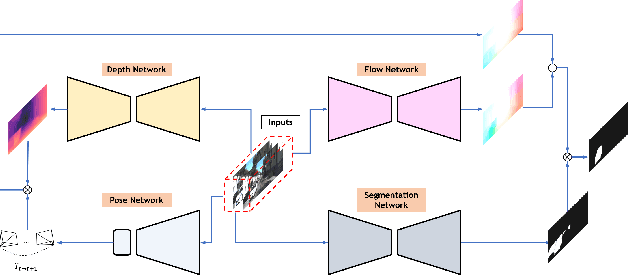
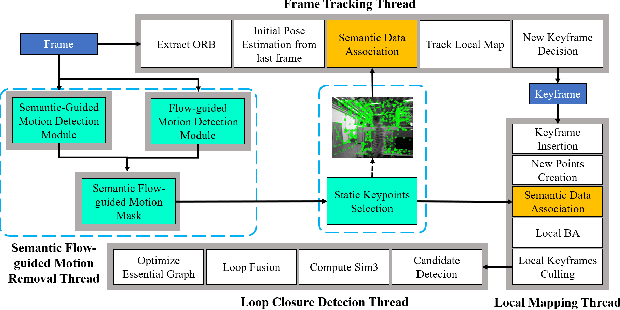


Moving objects in scenes are still a severe challenge for the SLAM system. Many efforts have tried to remove the motion regions in the images by detecting moving objects. In this way, the keypoints belonging to motion regions will be ignored in the later calculations. In this paper, we proposed a novel motion removal method, leveraging semantic information and optical flow to extract motion regions. Different from previous works, we don't predict moving objects or motion regions directly from image sequences. We computed rigid optical flow, synthesized by the depth and pose, and compared it against the estimated optical flow to obtain initial motion regions. Then, we utilized K-means to finetune the motion region masks with instance segmentation masks. The ORB-SLAM2 integrated with the proposed motion removal method achieved the best performance in both indoor and outdoor dynamic environments.