 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALPBench: A Benchmark for Attribution-level Long-term Personal Behavior Understanding
Feb 03, 2026Recent advances in large language models have highlighted their potential for personalized recommendation, where accurately capturing user preferences remains a key challenge. Leveraging their strong reasoning and generalization capabilities, LLMs offer new opportunities for modeling long-term user behavior. To systematically evaluate this, we introduce ALPBench, a Benchmark for Attribution-level Long-term Personal Behavior Understanding. Unlike item-focused benchmarks, ALPBench predicts user-interested attribute combinations, enabling ground-truth evaluation even for newly introduced items. It models preferences from long-term historical behaviors rather than users' explicitly expressed requests, better reflecting enduring interests. User histories are represented as natural language sequences, allowing interpretable, reasoning-based personalization. ALPBench enables fine-grained evaluation of personalization by focusing on the prediction of attribute combinations task that remains highly challenging for current LLMs due to the need to capture complex interactions among multiple attributes and reason over long-term user behavior sequences.
Efficient Generative AI Boosts Probabilistic Forecasting of Sudden Stratospheric Warmings
Oct 30, 2025Sudden Stratospheric Warmings (SSWs) are key sources of subseasonal predictability and major drivers of extreme winter weather. Yet, their accurate and efficient forecast remains a persistent challenge for numerical weather prediction (NWP) systems due to limitations in physical representation, initialization, and the immense computational demands of ensemble forecasts. While data-driven forecasting is rapidly evolving, its application to the complex, three-dimensional dynamics of SSWs, particularly for probabilistic forecast, remains underexplored. Here, we bridge this gap by developing a Flow Matching-based generative AI model (FM-Cast) for efficient and skillful probabilistic forecasting of the spatiotemporal evolution of stratospheric circulation. Evaluated across 18 major SSW events (1998-2024), FM-Cast skillfully forecasts the onset, intensity, and morphology of 10 events up to 20 days in advance, achieving ensemble accuracies above 50%. Its performance is comparable to or exceeds leading NWP systems while requiring only two minutes for a 50-member, 30-day forecast on a consumer GPU. Furthermore, leveraging FM-Cast as a scientific tool, we demonstrate through idealized experiments that SSW predictability is fundamentally linked to its underlying physical drivers, distinguishing between events forced from the troposphere and those driven by internal stratospheric dynamics. Our work thus establishes a computationally efficient paradigm for probabilistic forecasting stratospheric anomalies and showcases generative AI's potential to deepen the physical understanding of atmosphere-climate dynamics.
Multi-Turn Jailbreaks Are Simpler Than They Seem
Aug 11, 2025While defenses against single-turn jailbreak attacks on Large Language Models (LLMs) have improved significantly, multi-turn jailbreaks remain a persistent vulnerability, often achieving success rates exceeding 70% against models optimized for single-turn protection. This work presents an empirical analysis of automated multi-turn jailbreak attacks across state-of-the-art models including GPT-4, Claude, and Gemini variants, using the StrongREJECT benchmark. Our findings challenge the perceived sophistication of multi-turn attacks: when accounting for the attacker's ability to learn from how models refuse harmful requests, multi-turn jailbreaking approaches are approximately equivalent to simply resampling single-turn attacks multiple times. Moreover, attack success is correlated among similar models, making it easier to jailbreak newly released ones. Additionally, for reasoning models, we find surprisingly that higher reasoning effort often leads to higher attack success rates. Our results have important implications for AI safety evaluation and the design of jailbreak-resistant systems. We release the source code at https://github.com/diogo-cruz/multi_turn_simpler
Mamba-Adaptor: State Space Model Adaptor for Visual Recognition
May 19, 2025Recent State Space Models (SSM), especially Mamba, have demonstrated impressive performance in visual modeling and possess superior model efficiency. However, the application of Mamba to visual tasks suffers inferior performance due to three main constraints existing in the sequential model: 1) Casual computing is incapable of accessing global context; 2) Long-range forgetting when computing the current hidden states; 3) Weak spatial structural modeling due to the transformed sequential input. To address these issues, we investigate a simple yet powerful vision task Adaptor for Mamba models, which consists of two functional modules: Adaptor-T and Adaptor-S. When solving the hidden states for SSM, we apply a lightweight prediction module Adaptor-T to select a set of learnable locations as memory augmentations to ease long-range forgetting issues. Moreover, we leverage Adapator-S, composed of multi-scale dilated convolutional kernels, to enhance the spatial modeling and introduce the image inductive bias into the feature output. Both modules can enlarge the context modeling in casual computing, as the output is enhanced by the inaccessible features. We explore three usages of Mamba-Adaptor: A general visual backbone for various vision tasks; A booster module to raise the performance of pretrained backbones; A highly efficient fine-tuning module that adapts the base model for transfer learning tasks. Extensive experiments verify the effectiveness of Mamba-Adaptor in three settings. Notably, our Mamba-Adaptor achieves state-of the-art performance on the ImageNet and COCO benchmarks.
VRM: Knowledge Distillation via Virtual Relation Matching
Feb 28, 2025Knowledge distillation (KD) aims to transfer the knowledge of a more capable yet cumbersome teacher model to a lightweight student model. In recent years, relation-based KD methods have fallen behind, as their instance-matching counterparts dominate in performance. In this paper, we revive relational KD by identifying and tackling several key issues in relation-based methods, including their susceptibility to overfitting and spurious responses. Specifically, we transfer novelly constructed affinity graphs that compactly encapsulate a wealth of beneficial inter-sample, inter-class, and inter-view correlations by exploiting virtual views and relations as a new kind of knowledge. As a result, the student has access to richer guidance signals and stronger regularisation throughout the distillation process. To further mitigate the adverse impact of spurious responses, we prune the affinity graphs by dynamically detaching redundant and unreliable edges. Extensive experiments on CIFAR-100 and ImageNet datasets demonstrate the superior performance of the proposed virtual relation matching (VRM) method over a range of models, architectures, and set-ups. For instance, VRM for the first time hits 74.0% accuracy for ResNet50-to-MobileNetV2 distillation on ImageNet, and improves DeiT-T by 14.44% on CIFAR-100 with a ResNet56 teacher. Thorough analyses are also conducted to gauge the soundness, properties, and complexity of our designs. Code and models will be released.
QuadMamba: Learning Quadtree-based Selective Scan for Visual State Space Model
Oct 10, 2024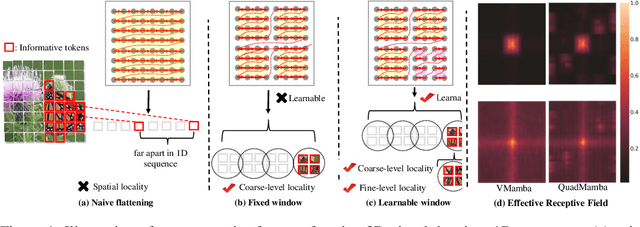
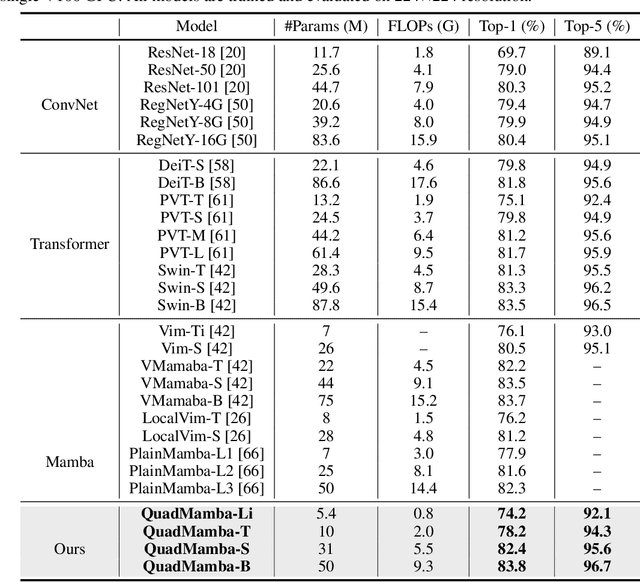
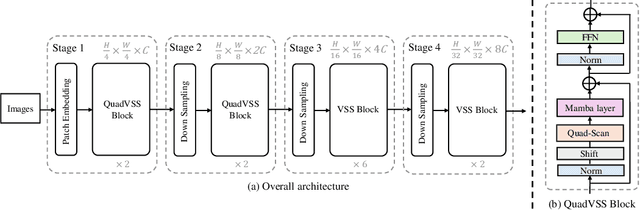
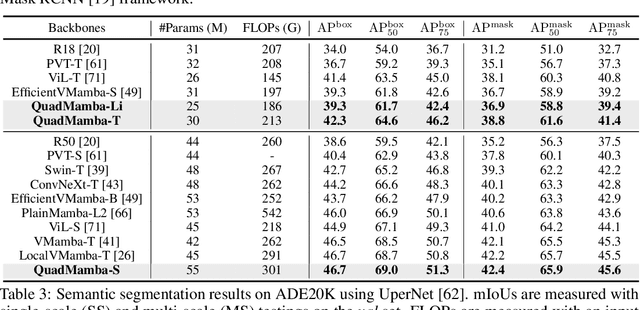
Recent advancements in State Space Models, notably Mamba, have demonstrated superior performance over the dominant Transformer models, particularly in reducing the computational complexity from quadratic to linear. Yet, difficulties in adapting Mamba from language to vision tasks arise due to the distinct characteristics of visual data, such as the spatial locality and adjacency within images and large variations in information granularity across visual tokens. Existing vision Mamba approaches either flatten tokens into sequences in a raster scan fashion, which breaks the local adjacency of images, or manually partition tokens into windows, which limits their long-range modeling and generalization capabilities. To address these limitations, we present a new vision Mamba model, coined QuadMamba, that effectively captures local dependencies of varying granularities via quadtree-based image partition and scan. Concretely, our lightweight quadtree-based scan module learns to preserve the 2D locality of spatial regions within learned window quadrants. The module estimates the locality score of each token from their features, before adaptively partitioning tokens into window quadrants. An omnidirectional window shifting scheme is also introduced to capture more intact and informative features across different local regions. To make the discretized quadtree partition end-to-end trainable, we further devise a sequence masking strategy based on Gumbel-Softmax and its straight-through gradient estimator. Extensive experiments demonstrate that QuadMamba achieves state-of-the-art performance in various vision tasks, including image classification, object detection, instance segmentation, and semantic segmentation. The code is in https://github.com/VISION-SJTU/QuadMamba.
PredFormer: Transformers Are Effective Spatial-Temporal Predictive Learners
Oct 07, 2024


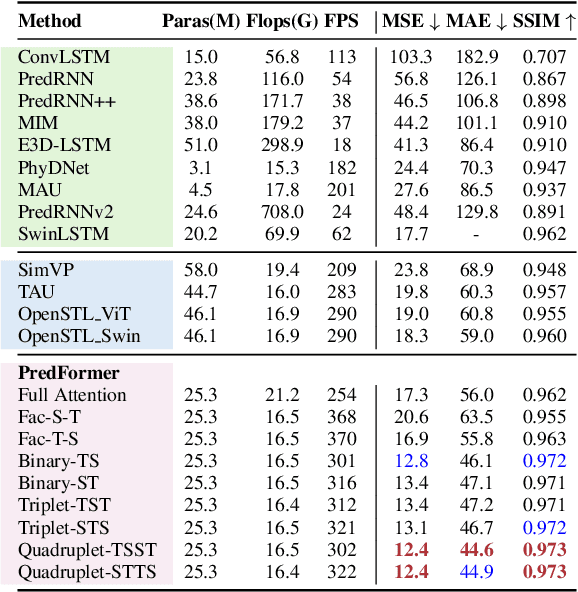
Spatiotemporal predictive learning methods generally fall into two categories: recurrent-based approaches, which face challenges in parallelization and performance, and recurrent-free methods, which employ convolutional neural networks (CNNs) as encoder-decoder architectures. These methods benefit from strong inductive biases but often at the expense of scalability and generalization. This paper proposes PredFormer, a pure transformer-based framework for spatiotemporal predictive learning. Motivated by the Vision Transformers (ViT) design, PredFormer leverages carefully designed Gated Transformer blocks, following a comprehensive analysis of 3D attention mechanisms, including full-, factorized-, and interleaved- spatial-temporal attention. With its recurrent-free, transformer-based design, PredFormer is both simple and efficient, significantly outperforming previous methods by large margins. Extensive experiments on synthetic and real-world datasets demonstrate that PredFormer achieves state-of-the-art performance. On Moving MNIST, PredFormer achieves a 51.3% reduction in MSE relative to SimVP. For TaxiBJ, the model decreases MSE by 33.1% and boosts FPS from 533 to 2364. Additionally, on WeatherBench, it reduces MSE by 11.1% while enhancing FPS from 196 to 404. These performance gains in both accuracy and efficiency demonstrate PredFormer's potential for real-world applications. The source code will be released at https://github.com/yyyujintang/PredFormer.
P2P: Part-to-Part Motion Cues Guide a Strong Tracking Framework for LiDAR Point Clouds
Jul 09, 20243D single object tracking (SOT) methods based on appearance matching has long suffered from insufficient appearance information incurred by incomplete, textureless and semantically deficient LiDAR point clouds. While motion paradigm exploits motion cues instead of appearance matching for tracking, it incurs complex multi-stage processing and segmentation module. In this paper, we first provide in-depth explorations on motion paradigm, which proves that (\textbf{i}) it is feasible to directly infer target relative motion from point clouds across consecutive frames; (\textbf{ii}) fine-grained information comparison between consecutive point clouds facilitates target motion modeling. We thereby propose to perform part-to-part motion modeling for consecutive point clouds and introduce a novel tracking framework, termed \textbf{P2P}. The novel framework fuses each corresponding part information between consecutive point clouds, effectively exploring detailed information changes and thus modeling accurate target-related motion cues. Following this framework, we present P2P-point and P2P-voxel models, incorporating implicit and explicit part-to-part motion modeling by point- and voxel-based representation, respectively. Without bells and whistles, P2P-voxel sets a new state-of-the-art performance ($\sim$\textbf{89\%}, \textbf{72\%} and \textbf{63\%} precision on KITTI, NuScenes and Waymo Open Dataset, respectively). Moreover, under the same point-based representation, P2P-point outperforms the previous motion tracker M$^2$Track by \textbf{3.3\%} and \textbf{6.7\%} on the KITTI and NuScenes, while running at a considerably high speed of \textbf{107 Fps} on a single RTX3090 GPU. The source code and pre-trained models are available at \url{https://github.com/haooozi/P2P}.
Correlation-Embedded Transformer Tracking: A Single-Branch Framework
Jan 23, 2024Developing robust and discriminative appearance models has been a long-standing research challenge in visual object tracking. In the prevalent Siamese-based paradigm, the features extracted by the Siamese-like networks are often insufficient to model the tracked targets and distractor objects, thereby hindering them from being robust and discriminative simultaneously. While most Siamese trackers focus on designing robust correlation operations, we propose a novel single-branch tracking framework inspired by the transformer. Unlike the Siamese-like feature extraction, our tracker deeply embeds cross-image feature correlation in multiple layers of the feature network. By extensively matching the features of the two images through multiple layers, it can suppress non-target features, resulting in target-aware feature extraction. The output features can be directly used for predicting target locations without additional correlation steps. Thus, we reformulate the two-branch Siamese tracking as a conceptually simple, fully transformer-based Single-Branch Tracking pipeline, dubbed SBT. After conducting an in-depth analysis of the SBT baseline, we summarize many effective design principles and propose an improved tracker dubbed SuperSBT. SuperSBT adopts a hierarchical architecture with a local modeling layer to enhance shallow-level features. A unified relation modeling is proposed to remove complex handcrafted layer pattern designs. SuperSBT is further improved by masked image modeling pre-training, integrating temporal modeling, and equipping with dedicated prediction heads. Thus, SuperSBT outperforms the SBT baseline by 4.7%,3.0%, and 4.5% AUC scores in LaSOT, TrackingNet, and GOT-10K. Notably, SuperSBT greatly raises the speed of SBT from 37 FPS to 81 FPS. Extensive experiments show that our method achieves superior results on eight VOT benchmarks.
Towards Category Unification of 3D Single Object Tracking on Point Clouds
Jan 20, 2024Category-specific models are provenly valuable methods in 3D single object tracking (SOT) regardless of Siamese or motion-centric paradigms. However, such over-specialized model designs incur redundant parameters, thus limiting the broader applicability of 3D SOT task. This paper first introduces unified models that can simultaneously track objects across all categories using a single network with shared model parameters. Specifically, we propose to explicitly encode distinct attributes associated to different object categories, enabling the model to adapt to cross-category data. We find that the attribute variances of point cloud objects primarily occur from the varying size and shape (e.g., large and square vehicles v.s. small and slender humans). Based on this observation, we design a novel point set representation learning network inheriting transformer architecture, termed AdaFormer, which adaptively encodes the dynamically varying shape and size information from cross-category data in a unified manner. We further incorporate the size and shape prior derived from the known template targets into the model's inputs and learning objective, facilitating the learning of unified representation. Equipped with such designs, we construct two category-unified models SiamCUT and MoCUT.Extensive experiments demonstrate that SiamCUT and MoCUT exhibit strong generalization and training stability. Furthermore, our category-unified models outperform the category-specific counterparts by a significant margin (e.g., on KITTI dataset, 12% and 3% performance gains on the Siamese and motion paradigms). Our code will be available.