 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompTrack: Information Bottleneck-Guided Low-Rank Dynamic Token Compression for Point Cloud Tracking
Nov 19, 20253D single object tracking (SOT) in LiDAR point clouds is a critical task in computer vision and autonomous driving. Despite great success having been achieved, the inherent sparsity of point clouds introduces a dual-redundancy challenge that limits existing trackers: (1) vast spatial redundancy from background noise impairs accuracy, and (2) informational redundancy within the foreground hinders efficiency. To tackle these issues, we propose CompTrack, a novel end-to-end framework that systematically eliminates both forms of redundancy in point clouds. First, CompTrack incorporates a Spatial Foreground Predictor (SFP) module to filter out irrelevant background noise based on information entropy, addressing spatial redundancy. Subsequently, its core is an Information Bottleneck-guided Dynamic Token Compression (IB-DTC) module that eliminates the informational redundancy within the foreground. Theoretically grounded in low-rank approximation, this module leverages an online SVD analysis to adaptively compress the redundant foreground into a compact and highly informative set of proxy tokens. Extensive experiments on KITTI, nuScenes and Waymo datasets demonstrate that CompTrack achieves top-performing tracking performance with superior efficiency, running at a real-time 90 FPS on a single RTX 3090 GPU.
FQ-PETR: Fully Quantized Position Embedding Transformation for Multi-View 3D Object Detection
Nov 14, 2025Camera-based multi-view 3D detection is crucial for autonomous driving. PETR and its variants (PETRs) excel in benchmarks but face deployment challenges due to high computational cost and memory footprint. Quantization is an effective technique for compressing deep neural networks by reducing the bit width of weights and activations. However, directly applying existing quantization methods to PETRs leads to severe accuracy degradation. This issue primarily arises from two key challenges: (1) significant magnitude disparity between multi-modal features-specifically, image features and camera-ray positional embeddings (PE), and (2) the inefficiency and approximation error of quantizing non-linear operators, which commonly rely on hardware-unfriendly computations. In this paper, we propose FQ-PETR, a fully quantized framework for PETRs, featuring three key innovations: (1) Quantization-Friendly LiDAR-ray Position Embedding (QFPE): Replacing multi-point sampling with LiDAR-prior-guided single-point sampling and anchor-based embedding eliminates problematic non-linearities (e.g., inverse-sigmoid) and aligns PE scale with image features, preserving accuracy. (2) Dual-Lookup Table (DULUT): This algorithm approximates complex non-linear functions using two cascaded linear LUTs, achieving high fidelity with minimal entries and no specialized hardware. (3) Quantization After Numerical Stabilization (QANS): Performing quantization after softmax numerical stabilization mitigates attention distortion from large inputs. On PETRs (e.g. PETR, StreamPETR, PETRv2, MV2d), FQ-PETR under W8A8 achieves near-floating-point accuracy (1% degradation) while reducing latency by up to 75%, significantly outperforming existing PTQ and QAT baselines.
MoEQuant: Enhancing Quantization for Mixture-of-Experts Large Language Models via Expert-Balanced Sampling and Affinity Guidance
May 02, 2025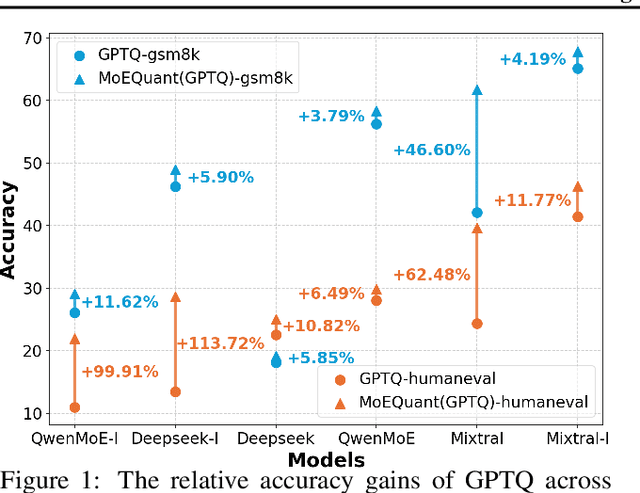
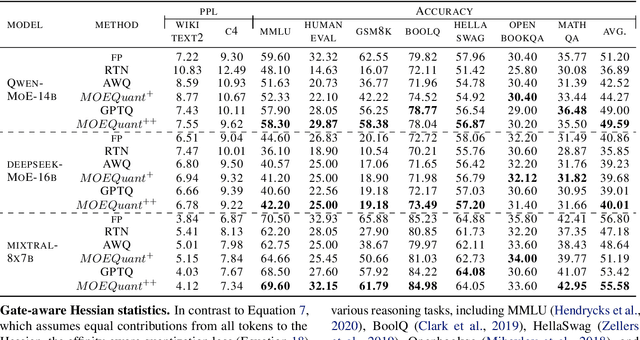
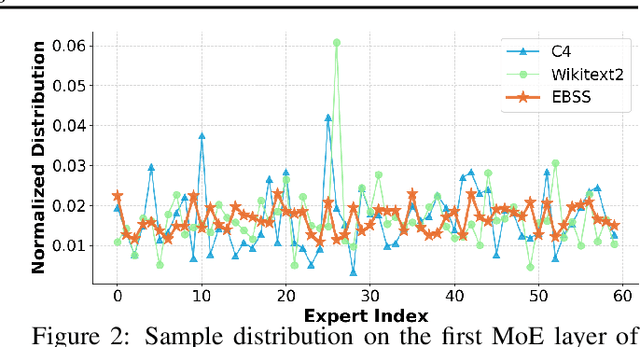
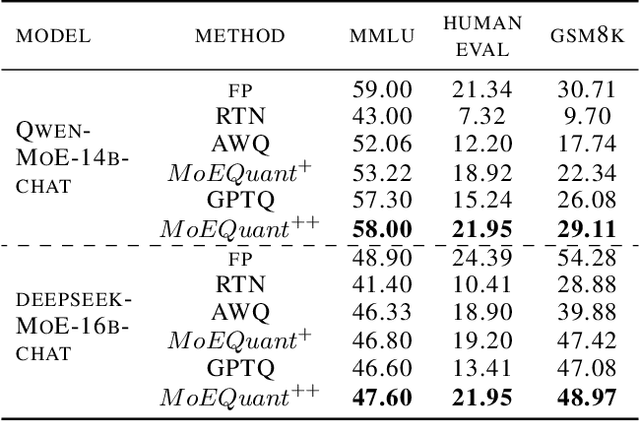
Mixture-of-Experts (MoE) large language models (LLMs), which leverage dynamic routing and sparse activation to enhance efficiency and scalability, have achieved higher performance while reducing computational costs. However, these models face significant memory overheads, limiting their practical deployment and broader adoption. Post-training quantization (PTQ), a widely used method for compressing LLMs, encounters severe accuracy degradation and diminished generalization performance when applied to MoE models. This paper investigates the impact of MoE's sparse and dynamic characteristics on quantization and identifies two primary challenges: (1) Inter-expert imbalance, referring to the uneven distribution of samples across experts, which leads to insufficient and biased calibration for less frequently utilized experts; (2) Intra-expert imbalance, arising from MoE's unique aggregation mechanism, which leads to varying degrees of correlation between different samples and their assigned experts. To address these challenges, we propose MoEQuant, a novel quantization framework tailored for MoE LLMs. MoE-Quant includes two novel techniques: 1) Expert-Balanced Self-Sampling (EBSS) is an efficient sampling method that efficiently constructs a calibration set with balanced expert distributions by leveraging the cumulative probabilities of tokens and expert balance metrics as guiding factors. 2) Affinity-Guided Quantization (AGQ), which incorporates affinities between experts and samples into the quantization process, thereby accurately assessing the impact of individual samples on different experts within the MoE layer. Experiments demonstrate that MoEQuant achieves substantial performance gains (more than 10 points accuracy gain in the HumanEval for DeepSeekMoE-16B under 4-bit quantization) and boosts efficiency.
RWKVQuant: Quantizing the RWKV Family with Proxy Guided Hybrid of Scalar and Vector Quantization
May 02, 2025



RWKV is a modern RNN architecture with comparable performance to Transformer, but still faces challenges when deployed to resource-constrained devices. Post Training Quantization (PTQ), which is a an essential technique to reduce model size and inference latency, has been widely used in Transformer models. However, it suffers significant degradation of performance when applied to RWKV. This paper investigates and identifies two key constraints inherent in the properties of RWKV: (1) Non-linear operators hinder the parameter-fusion of both smooth- and rotation-based quantization, introducing extra computation overhead. (2) The larger amount of uniformly distributed weights poses challenges for cluster-based quantization, leading to reduced accuracy. To this end, we propose RWKVQuant, a PTQ framework tailored for RWKV models, consisting of two novel techniques: (1) a coarse-to-fine proxy capable of adaptively selecting different quantization approaches by assessing the uniformity and identifying outliers in the weights, and (2) a codebook optimization algorithm that enhances the performance of cluster-based quantization methods for element-wise multiplication in RWKV. Experiments show that RWKVQuant can quantize RWKV-6-14B into about 3-bit with less than 1% accuracy loss and 2.14x speed up.
GSQ-Tuning: Group-Shared Exponents Integer in Fully Quantized Training for LLMs On-Device Fine-tuning
Feb 18, 2025Large Language Models (LLMs) fine-tuning technologies have achieved remarkable results. However, traditional LLM fine-tuning approaches face significant challenges: they require large Floating Point (FP) computation, raising privacy concerns when handling sensitive data, and are impractical for resource-constrained edge devices. While Parameter-Efficient Fine-Tuning (PEFT) techniques reduce trainable parameters, their reliance on floating-point arithmetic creates fundamental incompatibilities with edge hardware. In this work, we introduce a novel framework for on-device LLM fine-tuning that eliminates the need for floating-point operations in both inference and training, named GSQ-Tuning. At its core is the Group-Shared Exponents Integer format, which efficiently represents model parameters in integer format using shared exponents among parameter groups. When combined with LoRA-like adapters, this enables fully integer-based fine-tuning that is both memory and compute efficient. We demonstrate that our approach achieves accuracy comparable to FP16-based fine-tuning while significantly reducing memory usage (50%). Moreover, compared to FP8, our method can reduce 5x power consumption and 11x chip area with same performance, making large-scale model adaptation feasible on edge devices.
GSRender: Deduplicated Occupancy Prediction via Weakly Supervised 3D Gaussian Splatting
Dec 19, 2024



3D occupancy perception is gaining increasing attention due to its capability to offer detailed and precise environment representations. Previous weakly-supervised NeRF methods balance efficiency and accuracy, with mIoU varying by 5-10 points due to sampling count along camera rays. Recently, real-time Gaussian splatting has gained widespread popularity in 3D reconstruction, and the occupancy prediction task can also be viewed as a reconstruction task. Consequently, we propose GSRender, which naturally employs 3D Gaussian Splatting for occupancy prediction, simplifying the sampling process. In addition, the limitations of 2D supervision result in duplicate predictions along the same camera ray. We implemented the Ray Compensation (RC) module, which mitigates this issue by compensating for features from adjacent frames. Finally, we redesigned the loss to eliminate the impact of dynamic objects from adjacent frames. Extensive experiments demonstrate that our approach achieves SOTA (state-of-the-art) results in RayIoU (+6.0), while narrowing the gap with 3D supervision methods. Our code will be released soon.
MVCTrack: Boosting 3D Point Cloud Tracking via Multimodal-Guided Virtual Cues
Dec 03, 2024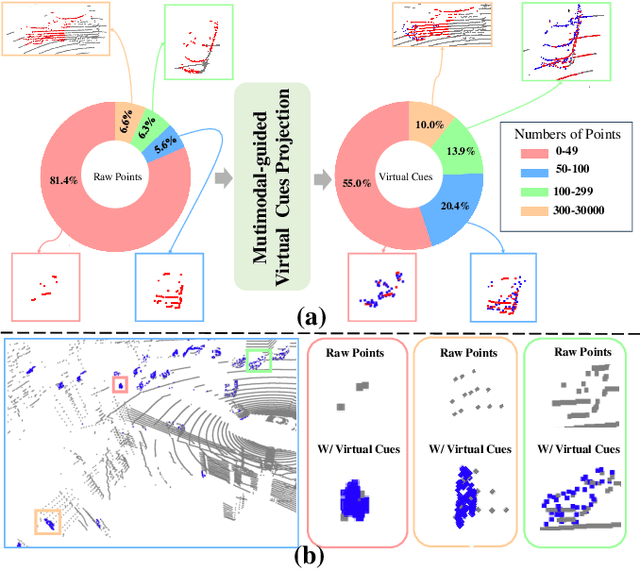
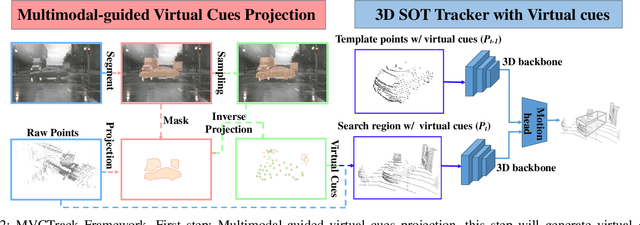
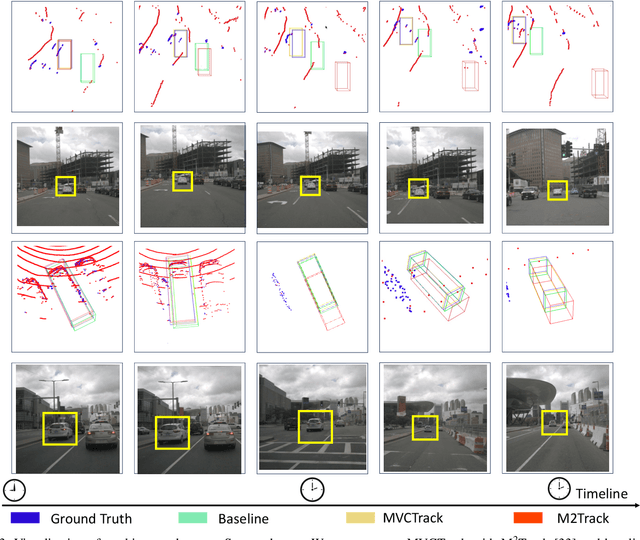

3D single object tracking is essential in autonomous driving and robotics. Existing methods often struggle with sparse and incomplete point cloud scenarios. To address these limitations, we propose a Multimodal-guided Virtual Cues Projection (MVCP) scheme that generates virtual cues to enrich sparse point clouds. Additionally, we introduce an enhanced tracker MVCTrack based on the generated virtual cues. Specifically, the MVCP scheme seamlessly integrates RGB sensors into LiDAR-based systems, leveraging a set of 2D detections to create dense 3D virtual cues that significantly improve the sparsity of point clouds. These virtual cues can naturally integrate with existing LiDAR-based 3D trackers, yielding substantial performance gains. Extensive experiments demonstrate that our method achieves competitive performance on the NuScenes dataset.
PTQ4RIS: Post-Training Quantization for Referring Image Segmentation
Sep 25, 2024Referring Image Segmentation (RIS), aims to segment the object referred by a given sentence in an image by understanding both visual and linguistic information. However, existing RIS methods tend to explore top-performance models, disregarding considerations for practical applications on resources-limited edge devices. This oversight poses a significant challenge for on-device RIS inference. To this end, we propose an effective and efficient post-training quantization framework termed PTQ4RIS. Specifically, we first conduct an in-depth analysis of the root causes of performance degradation in RIS model quantization and propose dual-region quantization (DRQ) and reorder-based outlier-retained quantization (RORQ) to address the quantization difficulties in visual and text encoders. Extensive experiments on three benchmarks with different bits settings (from 8 to 4 bits) demonstrates its superior performance. Importantly, we are the first PTQ method specifically designed for the RIS task, highlighting the feasibility of PTQ in RIS applications. Code will be available at {https://github.com/gugu511yy/PTQ4RIS}.
P2P: Part-to-Part Motion Cues Guide a Strong Tracking Framework for LiDAR Point Clouds
Jul 09, 20243D single object tracking (SOT) methods based on appearance matching has long suffered from insufficient appearance information incurred by incomplete, textureless and semantically deficient LiDAR point clouds. While motion paradigm exploits motion cues instead of appearance matching for tracking, it incurs complex multi-stage processing and segmentation module. In this paper, we first provide in-depth explorations on motion paradigm, which proves that (\textbf{i}) it is feasible to directly infer target relative motion from point clouds across consecutive frames; (\textbf{ii}) fine-grained information comparison between consecutive point clouds facilitates target motion modeling. We thereby propose to perform part-to-part motion modeling for consecutive point clouds and introduce a novel tracking framework, termed \textbf{P2P}. The novel framework fuses each corresponding part information between consecutive point clouds, effectively exploring detailed information changes and thus modeling accurate target-related motion cues. Following this framework, we present P2P-point and P2P-voxel models, incorporating implicit and explicit part-to-part motion modeling by point- and voxel-based representation, respectively. Without bells and whistles, P2P-voxel sets a new state-of-the-art performance ($\sim$\textbf{89\%}, \textbf{72\%} and \textbf{63\%} precision on KITTI, NuScenes and Waymo Open Dataset, respectively). Moreover, under the same point-based representation, P2P-point outperforms the previous motion tracker M$^2$Track by \textbf{3.3\%} and \textbf{6.7\%} on the KITTI and NuScenes, while running at a considerably high speed of \textbf{107 Fps} on a single RTX3090 GPU. The source code and pre-trained models are available at \url{https://github.com/haooozi/P2P}.
Sub-SA: Strengthen In-context Learning via Submodular Selective Annotation
Jul 08, 2024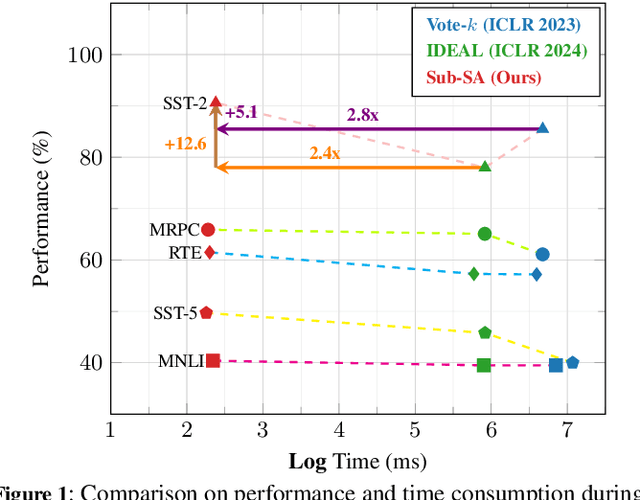
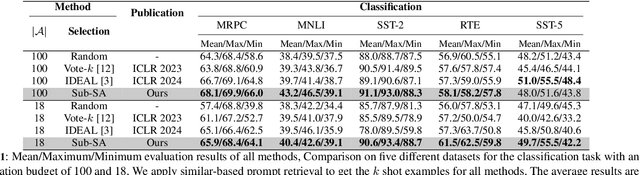

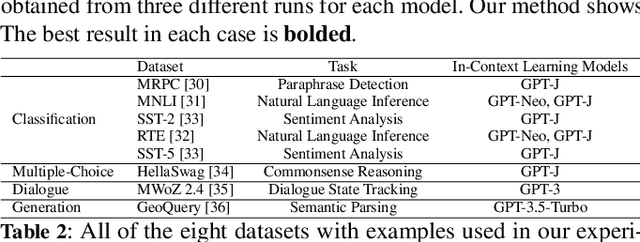
In-context learning (ICL) leverages in-context examples as prompts for the predictions of Large Language Models (LLMs). These prompts play a crucial role in achieving strong performance. However, the selection of suitable prompts from a large pool of labeled examples often entails significant annotation costs. To address this challenge, we propose \textbf{Sub-SA} (\textbf{Sub}modular \textbf{S}elective \textbf{A}nnotation), a submodule-based selective annotation method. The aim of Sub-SA is to reduce annotation costs while improving the quality of in-context examples and minimizing the time consumption of the selection process. In Sub-SA, we design a submodular function that facilitates effective subset selection for annotation and demonstrates the characteristics of monotonically and submodularity from the theoretical perspective. Specifically, we propose \textbf{RPR} (\textbf{R}eward and \textbf{P}enalty \textbf{R}egularization) to better balance the diversity and representativeness of the unlabeled dataset attributed to a reward term and a penalty term, respectively. Consequently, the selection for annotations can be effectively addressed with a simple yet effective greedy search algorithm based on the submodular function. Finally, we apply the similarity prompt retrieval to get the examples for ICL.