 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Answers to Arguments: Toward Trustworthy Clinical Diagnostic Reasoning with Toulmin-Guided Curriculum Goal-Conditioned Learning
Apr 13, 2026The integration of Large Language Models (LLMs) into clinical decision support is critically obstructed by their opaque and often unreliable reasoning. In the high-stakes domain of healthcare, correct answers alone are insufficient; clinical practice demands full transparency to ensure patient safety and enable professional accountability. A pervasive and dangerous weakness of current LLMs is their tendency to produce "correct answers through flawed reasoning." This issue is far more than a minor academic flaw; such process errors signal a fundamental lack of robust understanding, making the model prone to broader hallucinations and unpredictable failures when faced with real-world clinical complexity. In this paper, we establish a framework for trustworthy clinical argumentation by adapting the Toulmin model to the diagnostic process. We propose a novel training pipeline: Curriculum Goal-Conditioned Learning (CGCL), designed to progressively train LLM to generate diagnostic arguments that explicitly follow this Toulmin structure. CGCL's progressive three-stage curriculum systematically builds a solid clinical argument: (1) extracting facts and generating differential diagnoses; (2) justifying a core hypothesis while rebutting alternatives; and (3) synthesizing the analysis into a final, qualified conclusion. We validate CGCL using T-Eval, a quantitative framework measuring the integrity of the diagnosis reasoning. Experiments show that our method achieves diagnostic accuracy and reasoning quality comparable to resource-intensive Reinforcement Learning (RL) methods, while offering a more stable and efficient training pipeline.
VIVID-Med: LLM-Supervised Structured Pretraining for Deployable Medical ViTs
Mar 11, 2026Vision-language pretraining has driven significant progress in medical image analysis. However, current methods typically supervise visual encoders using one-hot labels or free-form text, neither of which effectively captures the complex semantic relationships among clinical findings. In this study, we introduce VIVID-Med, a novel framework that leverages a frozen large language model (LLM) as a structured semantic teacher to pretrain medical vision transformers (ViTs). VIVID-Med translates clinical findings into verifiable JSON field-state pairs via a Unified Medical Schema (UMS), utilizing answerability-aware masking to focus optimization. It then employs Structured Prediction Decomposition (SPD) to partition cross-attention into orthogonality-regularized query groups, extracting complementary visual aspects. Crucially, the LLM is discarded post-training, yielding a lightweight, deployable ViT-only backbone. We evaluated VIVID-Med across multiple settings: on CheXpert linear probing, it achieves a macro-AUC of 0.8588, outperforming BiomedCLIP by +6.65 points while using 500x less data. It also demonstrates robust zero-shot cross-domain transfer to NIH ChestX-ray14 (0.7225 macro-AUC) and strong cross-modality generalization to CT, achieving 0.8413 AUC on LIDC-IDRI lung nodule classification and 0.9969 macro-AUC on OrganAMNIST 11-organ classification. VIVID-Med offers a highly efficient, scalable alternative to deploying resource-heavy vision-language models in clinical settings.
PRISM: Festina Lente Proactivity -- Risk-Sensitive, Uncertainty-Aware Deliberation for Proactive Agents
Feb 02, 2026Proactive agents must decide not only what to say but also whether and when to intervene. Many current systems rely on brittle heuristics or indiscriminate long reasoning, which offers little control over the benefit-burden tradeoff. We formulate the problem as cost-sensitive selective intervention and present PRISM, a novel framework that couples a decision-theoretic gate with a dual-process reasoning architecture. At inference time, the agent intervenes only when a calibrated probability of user acceptance exceeds a threshold derived from asymmetric costs of missed help and false alarms. Inspired by festina lente (Latin: "make haste slowly"), we gate by an acceptance-calibrated, cost-derived threshold and invoke a resource-intensive Slow mode with counterfactual checks only near the decision boundary, concentrating computation on ambiguous and high-stakes cases. Training uses gate-aligned, schema-locked distillation: a teacher running the full PRISM pipeline provides dense, executable supervision on unlabeled interaction traces, while the student learns a response policy that is explicitly decoupled from the intervention gate to enable tunable and auditable control. On ProactiveBench, PRISM reduces false alarms by 22.78% and improves F1 by 20.14% over strong baselines. These results show that principled decision-theoretic gating, paired with selective slow reasoning and aligned distillation, yields proactive agents that are precise, computationally efficient, and controllable. To facilitate reproducibility, we release our code, models, and resources at https://prism-festinalente.github.io/; all experiments use the open-source ProactiveBench benchmark.
Curiosity Driven Knowledge Retrieval for Mobile Agents
Jan 27, 2026Mobile agents have made progress toward reliable smartphone automation, yet performance in complex applications remains limited by incomplete knowledge and weak generalization to unseen environments. We introduce a curiosity driven knowledge retrieval framework that formalizes uncertainty during execution as a curiosity score. When this score exceeds a threshold, the system retrieves external information from documentation, code repositories, and historical trajectories. Retrieved content is organized into structured AppCards, which encode functional semantics, parameter conventions, interface mappings, and interaction patterns. During execution, an enhanced agent selectively integrates relevant AppCards into its reasoning process, thereby compensating for knowledge blind spots and improving planning reliability. Evaluation on the AndroidWorld benchmark shows consistent improvements across backbones, with an average gain of six percentage points and a new state of the art success rate of 88.8\% when combined with GPT-5. Analysis indicates that AppCards are particularly effective for multi step and cross application tasks, while improvements depend on the backbone model. Case studies further confirm that AppCards reduce ambiguity, shorten exploration, and support stable execution trajectories. Task trajectories are publicly available at https://lisalsj.github.io/Droidrun-appcard/.
SRU-Pix2Pix: A Fusion-Driven Generator Network for Medical Image Translation with Few-Shot Learning
Jan 08, 2026Magnetic Resonance Imaging (MRI) provides detailed tissue information, but its clinical application is limited by long acquisition time, high cost, and restricted resolution. Image translation has recently gained attention as a strategy to address these limitations. Although Pix2Pix has been widely applied in medical image translation, its potential has not been fully explored. In this study, we propose an enhanced Pix2Pix framework that integrates Squeeze-and-Excitation Residual Networks (SEResNet) and U-Net++ to improve image generation quality and structural fidelity. SEResNet strengthens critical feature representation through channel attention, while U-Net++ enhances multi-scale feature fusion. A simplified PatchGAN discriminator further stabilizes training and refines local anatomical realism. Experimental results demonstrate that under few-shot conditions with fewer than 500 images, the proposed method achieves consistent structural fidelity and superior image quality across multiple intra-modality MRI translation tasks, showing strong generalization ability. These results suggest an effective extension of Pix2Pix for medical image translation.
Reflective Personalization Optimization: A Post-hoc Rewriting Framework for Black-Box Large Language Models
Nov 07, 2025The personalization of black-box large language models (LLMs) is a critical yet challenging task. Existing approaches predominantly rely on context injection, where user history is embedded into the prompt to directly guide the generation process. However, this single-step paradigm imposes a dual burden on the model: generating accurate content while simultaneously aligning with user-specific styles. This often results in a trade-off that compromises output quality and limits precise control. To address this fundamental tension, we propose Reflective Personalization Optimization (RPO), a novel framework that redefines the personalization paradigm by decoupling content generation from alignment. RPO operates in two distinct stages: first, a base model generates a high-quality, generic response; then, an external reflection module explicitly rewrites this output to align with the user's preferences. This reflection module is trained using a two-stage process. Initially, supervised fine-tuning is employed on structured rewriting trajectories to establish a core personalized reasoning policy that models the transformation from generic to user-aligned responses. Subsequently, reinforcement learning is applied to further refine and enhance the quality of the personalized outputs. Comprehensive experiments on the LaMP benchmark demonstrate that RPO, by decoupling content generation from personalization, significantly outperforms state-of-the-art baselines. These findings underscore the superiority of explicit response shaping over implicit context injection. Moreover, RPO introduces an efficient, model-agnostic personalization layer that can be seamlessly integrated with any underlying base model, paving the way for a new and effective direction in user-centric generation scenarios.
AURORA:Automated Training Framework of Universal Process Reward Models via Ensemble Prompting and Reverse Verification
Feb 17, 2025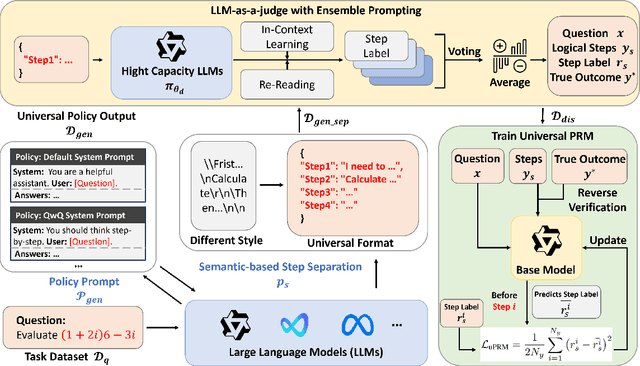
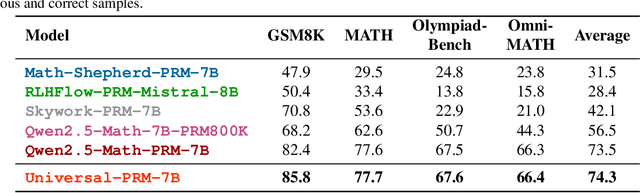
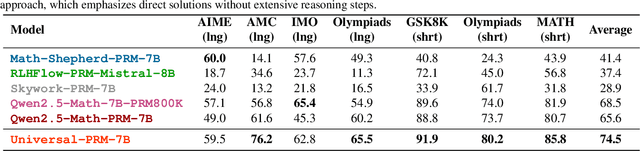
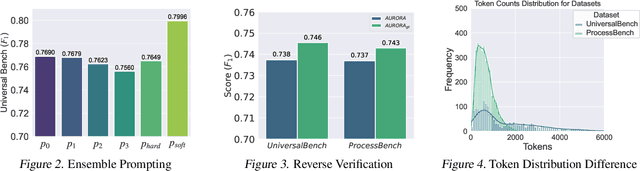
The reasoning capabilities of advanced large language models (LLMs) like o1 have revolutionized artificial intelligence applications. Nevertheless, evaluating and optimizing complex reasoning processes remain significant challenges due to diverse policy distributions and the inherent limitations of human effort and accuracy. In this paper, we present AURORA, a novel automated framework for training universal process reward models (PRMs) using ensemble prompting and reverse verification. The framework employs a two-phase approach: First, it uses diverse prompting strategies and ensemble methods to perform automated annotation and evaluation of processes, ensuring robust assessments for reward learning. Second, it leverages practical reference answers for reverse verification, enhancing the model's ability to validate outputs and improving training accuracy. To assess the framework's performance, we extend beyond the existing ProcessBench benchmark by introducing UniversalBench, which evaluates reward predictions across full trajectories under diverse policy distribtion with long Chain-of-Thought (CoT) outputs. Experimental results demonstrate that AURORA enhances process evaluation accuracy, improves PRMs' accuracy for diverse policy distributions and long-CoT responses. The project will be open-sourced at https://auroraprm.github.io/. The Universal-PRM-7B is available at https://huggingface.co/infly/Universal-PRM-7B.
An Attentive Dual-Encoder Framework Leveraging Multimodal Visual and Semantic Information for Automatic OSAHS Diagnosis
Dec 25, 2024



Obstructive sleep apnea-hypopnea syndrome (OSAHS) is a common sleep disorder caused by upper airway blockage, leading to oxygen deprivation and disrupted sleep. Traditional diagnosis using polysomnography (PSG) is expensive, time-consuming, and uncomfortable. Existing deep learning methods using facial image analysis lack accuracy due to poor facial feature capture and limited sample sizes. To address this, we propose a multimodal dual encoder model that integrates visual and language inputs for automated OSAHS diagnosis. The model balances data using randomOverSampler, extracts key facial features with attention grids, and converts physiological data into meaningful text. Cross-attention combines image and text data for better feature extraction, and ordered regression loss ensures stable learning. Our approach improves diagnostic efficiency and accuracy, achieving 91.3% top-1 accuracy in a four-class severity classification task, demonstrating state-of-the-art performance. Code will be released upon acceptance.
Distribution-aware Noisy-label Crack Segmentation
Oct 12, 2024



Road crack segmentation is critical for robotic systems tasked with the inspection, maintenance, and monitoring of road infrastructures. Existing deep learning-based methods for crack segmentation are typically trained on specific datasets, which can lead to significant performance degradation when applied to unseen real-world scenarios. To address this, we introduce the SAM-Adapter, which incorporates the general knowledge of the Segment Anything Model (SAM) into crack segmentation, demonstrating enhanced performance and generalization capabilities. However, the effectiveness of the SAM-Adapter is constrained by noisy labels within small-scale training sets, including omissions and mislabeling of cracks. In this paper, we present an innovative joint learning framework that utilizes distribution-aware domain-specific semantic knowledge to guide the discriminative learning process of the SAM-Adapter. To our knowledge, this is the first approach that effectively minimizes the adverse effects of noisy labels on the supervised learning of the SAM-Adapter. Our experimental results on two public pavement crack segmentation datasets confirm that our method significantly outperforms existing state-of-the-art techniques. Furthermore, evaluations on the completely unseen CFD dataset demonstrate the high cross-domain generalization capability of our model, underscoring its potential for practical applications in crack segmentation.
PTQ4RIS: Post-Training Quantization for Referring Image Segmentation
Sep 25, 2024Referring Image Segmentation (RIS), aims to segment the object referred by a given sentence in an image by understanding both visual and linguistic information. However, existing RIS methods tend to explore top-performance models, disregarding considerations for practical applications on resources-limited edge devices. This oversight poses a significant challenge for on-device RIS inference. To this end, we propose an effective and efficient post-training quantization framework termed PTQ4RIS. Specifically, we first conduct an in-depth analysis of the root causes of performance degradation in RIS model quantization and propose dual-region quantization (DRQ) and reorder-based outlier-retained quantization (RORQ) to address the quantization difficulties in visual and text encoders. Extensive experiments on three benchmarks with different bits settings (from 8 to 4 bits) demonstrates its superior performance. Importantly, we are the first PTQ method specifically designed for the RIS task, highlighting the feasibility of PTQ in RIS applications. Code will be available at {https://github.com/gugu511yy/PTQ4RIS}.