 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeL2R: Low-Rank and Lipschitz-Controlled Routing for Mixture-of-Experts
Jan 29, 2026Mixture-of-Experts (MoE) models scale neural networks by conditionally activating a small subset of experts, where the router plays a central role in determining expert specialization and overall model performance. However, many modern MoE systems still adopt linear routers in raw high-dimensional representation spaces, where representation mismatch, angular concentration, and scale-sensitive scoring can jointly undermine routing discriminability and stable expert specialization. In this work, we propose Low-rank \& Lipschitz-controlled Routing (L2R), a unified routing framework that reshapes both the routing space and scoring geometry. L2R performs expert assignment in a shared low-rank latent routing space and introduces Saturated Inner-Product Scoring (SIPS) to explicitly control the Lipschitz behavior of routing functions, yielding smoother and more stable routing geometry. In addition, L2R incorporates a parameter-efficient multi-anchor routing mechanism to enhance expert expressiveness. Extensive experiments on a large-scale language MoE model and a vision MoE setting on ImageNet demonstrate that L2R consistently improves routing stability, expert specialization, and overall model performance.
Adaptive Shared Experts with LoRA-Based Mixture of Experts for Multi-Task Learning
Oct 01, 2025Mixture-of-Experts (MoE) has emerged as a powerful framework for multi-task learning (MTL). However, existing MoE-MTL methods often rely on single-task pretrained backbones and suffer from redundant adaptation and inefficient knowledge sharing during the transition from single-task to multi-task learning (STL to MTL). To address these limitations, we propose adaptive shared experts (ASE) within a low-rank adaptation (LoRA) based MoE, where shared experts are assigned router-computed gating weights jointly normalized with sparse experts. This design facilitates STL to MTL transition, enhances expert specialization, and cooperation. Furthermore, we incorporate fine-grained experts by increasing the number of LoRA experts while proportionally reducing their rank, enabling more effective knowledge sharing under a comparable parameter budget. Extensive experiments on the PASCAL-Context benchmark, under unified training settings, demonstrate that ASE consistently improves performance across diverse configurations and validates the effectiveness of fine-grained designs for MTL.
TaskCraft: Automated Generation of Agentic Tasks
Jun 11, 2025Agentic tasks, which require multi-step problem solving with autonomy, tool use, and adaptive reasoning, are becoming increasingly central to the advancement of NLP and AI. However, existing instruction data lacks tool interaction, and current agentic benchmarks rely on costly human annotation, limiting their scalability. We introduce \textsc{TaskCraft}, an automated workflow for generating difficulty-scalable, multi-tool, and verifiable agentic tasks with execution trajectories. TaskCraft expands atomic tasks using depth-based and width-based extensions to create structurally and hierarchically complex challenges. Empirical results show that these tasks improve prompt optimization in the generation workflow and enhance supervised fine-tuning of agentic foundation models. We present a large-scale synthetic dataset of approximately 36,000 tasks with varying difficulty to support future research on agent tuning and evaluation.
Multimodal 3D Genome Pre-training
Apr 12, 2025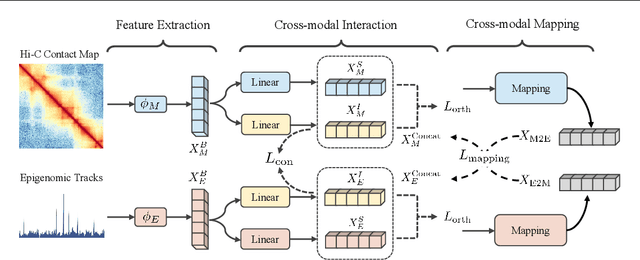
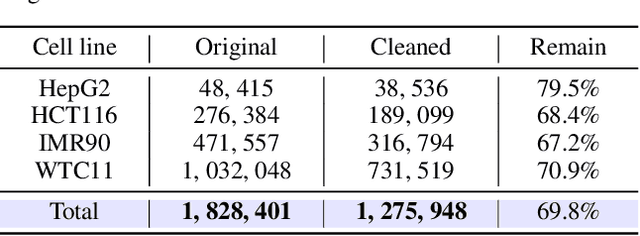
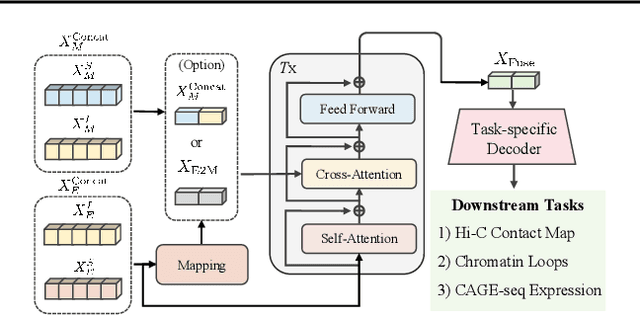
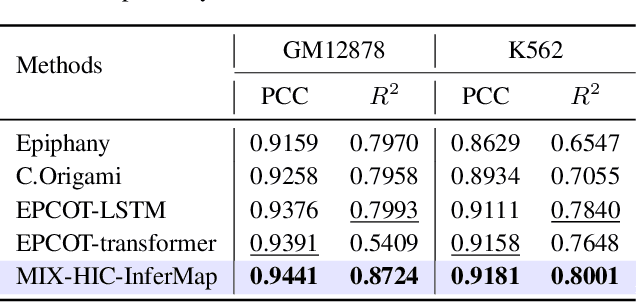
Deep learning techniques have driven significant progress in various analytical tasks within 3D genomics in computational biology. However, a holistic understanding of 3D genomics knowledge remains underexplored. Here, we propose MIX-HIC, the first multimodal foundation model of 3D genome that integrates both 3D genome structure and epigenomic tracks, which obtains unified and comprehensive semantics. For accurate heterogeneous semantic fusion, we design the cross-modal interaction and mapping blocks for robust unified representation, yielding the accurate aggregation of 3D genome knowledge. Besides, we introduce the first large-scale dataset comprising over 1 million pairwise samples of Hi-C contact maps and epigenomic tracks for high-quality pre-training, enabling the exploration of functional implications in 3D genomics. Extensive experiments show that MIX-HIC can significantly surpass existing state-of-the-art methods in diverse downstream tasks. This work provides a valuable resource for advancing 3D genomics research.
AURORA:Automated Training Framework of Universal Process Reward Models via Ensemble Prompting and Reverse Verification
Feb 17, 2025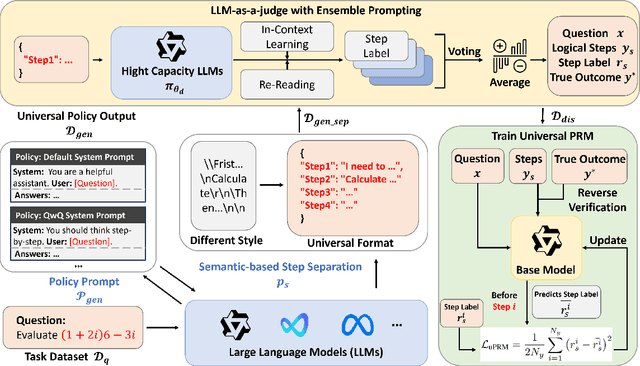
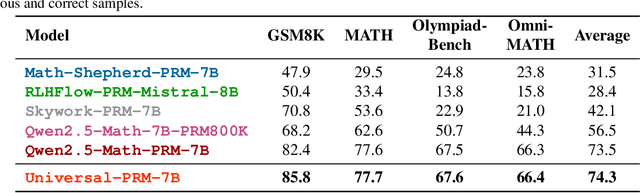
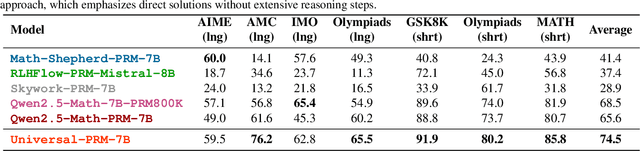
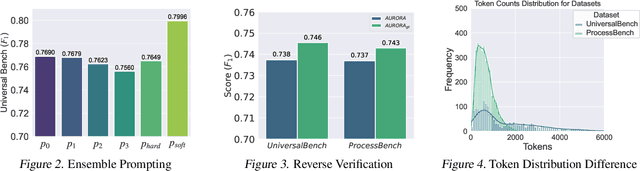
The reasoning capabilities of advanced large language models (LLMs) like o1 have revolutionized artificial intelligence applications. Nevertheless, evaluating and optimizing complex reasoning processes remain significant challenges due to diverse policy distributions and the inherent limitations of human effort and accuracy. In this paper, we present AURORA, a novel automated framework for training universal process reward models (PRMs) using ensemble prompting and reverse verification. The framework employs a two-phase approach: First, it uses diverse prompting strategies and ensemble methods to perform automated annotation and evaluation of processes, ensuring robust assessments for reward learning. Second, it leverages practical reference answers for reverse verification, enhancing the model's ability to validate outputs and improving training accuracy. To assess the framework's performance, we extend beyond the existing ProcessBench benchmark by introducing UniversalBench, which evaluates reward predictions across full trajectories under diverse policy distribtion with long Chain-of-Thought (CoT) outputs. Experimental results demonstrate that AURORA enhances process evaluation accuracy, improves PRMs' accuracy for diverse policy distributions and long-CoT responses. The project will be open-sourced at https://auroraprm.github.io/. The Universal-PRM-7B is available at https://huggingface.co/infly/Universal-PRM-7B.
Biology Instructions: A Dataset and Benchmark for Multi-Omics Sequence Understanding Capability of Large Language Models
Dec 26, 2024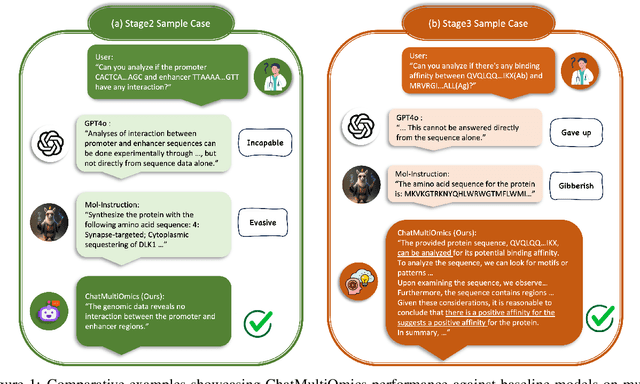
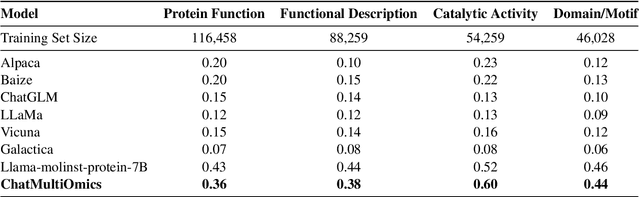
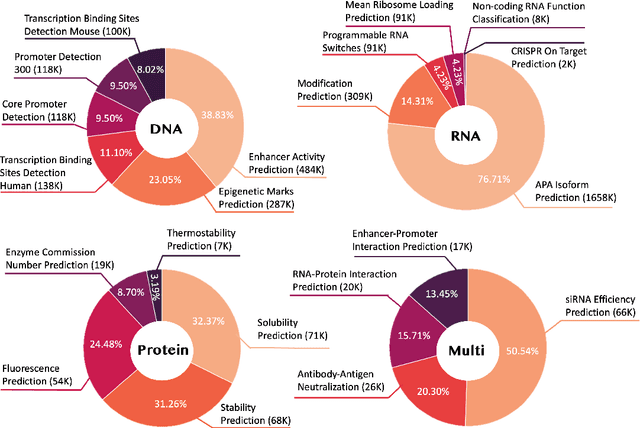
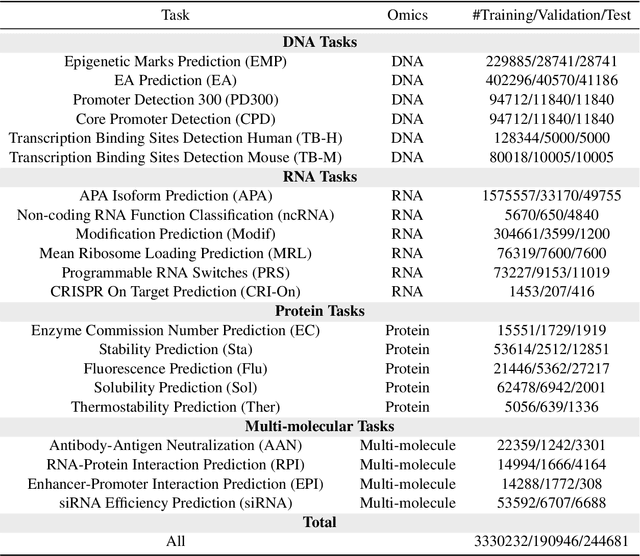
Large language models have already demonstrated their formidable capabilities in general domains, ushering in a revolutionary transformation. However, exploring and exploiting the extensive knowledge of these models to comprehend multi-omics biology remains underexplored. To fill this research gap, we first introduce Biology-Instructions, the first large-scale multi-omics biological sequences-related instruction-tuning dataset including DNA, RNA, proteins, and multi-molecules, designed to bridge the gap between large language models (LLMs) and complex biological sequences-related tasks. This dataset can enhance the versatility of LLMs by integrating diverse biological sequenced-based prediction tasks with advanced reasoning capabilities, while maintaining conversational fluency. Additionally, we reveal significant performance limitations in even state-of-the-art LLMs on biological sequence-related multi-omics tasks without specialized pre-training and instruction-tuning. We further develop a strong baseline called ChatMultiOmics with a novel three-stage training pipeline, demonstrating the powerful ability to understand biology by using Biology-Instructions. Biology-Instructions and ChatMultiOmics are publicly available and crucial resources for enabling more effective integration of LLMs with multi-omics sequence analysis.
Detect an Object At Once without Fine-tuning
Nov 04, 2024



When presented with one or a few photos of a previously unseen object, humans can instantly recognize it in different scenes. Although the human brain mechanism behind this phenomenon is still not fully understood, this work introduces a novel technical realization of this task. It consists of two phases: (1) generating a Similarity Density Map (SDM) by convolving the scene image with the given object image patch(es) so that the highlight areas in the SDM indicate the possible locations; (2) obtaining the object occupied areas in the scene through a Region Alignment Network (RAN). The RAN is constructed on a backbone of Deep Siamese Network (DSN), and different from the traditional DSNs, it aims to obtain the object accurate regions by regressing the location and area differences between the ground truths and the predicted ones indicated by the highlight areas in SDM. By pre-learning from labels annotated in traditional datasets, the SDM-RAN can detect previously unknown objects without fine-tuning. Experiments were conducted on the MS COCO, PASCAL VOC datasets. The results indicate that the proposed method outperforms state-of-the-art methods on the same task.
Decay Pruning Method: Smooth Pruning With a Self-Rectifying Procedure
Jun 06, 2024



Current structured pruning methods often result in considerable accuracy drops due to abrupt network changes and loss of information from pruned structures. To address these issues, we introduce the Decay Pruning Method (DPM), a novel smooth pruning approach with a self-rectifying mechanism. DPM consists of two key components: (i) Smooth Pruning: It converts conventional single-step pruning into multi-step smooth pruning, gradually reducing redundant structures to zero over N steps with ongoing optimization. (ii) Self-Rectifying: This procedure further enhances the aforementioned process by rectifying sub-optimal pruning based on gradient information. Our approach demonstrates strong generalizability and can be easily integrated with various existing pruning methods. We validate the effectiveness of DPM by integrating it with three popular pruning methods: OTOv2, Depgraph, and Gate Decorator. Experimental results show consistent improvements in performance compared to the original pruning methods, along with further reductions of FLOPs in most scenarios.
Rene: A Pre-trained Multi-modal Architecture for Auscultation of Respiratory Diseases
May 13, 2024

This study presents a novel methodology utilizing a pre-trained speech recognition model for processing respiratory sound data. By incorporating medical record information, we introduce an innovative multi-modal deep-learning architecture, named Rene, which addresses the challenges of poor interpretability and underperformance in real-time clinical diagnostic response observed in previous respiratory disease-focused models. The proposed Rene architecture demonstrated significant improvements of 10.24%, 16.15%, 15.29%, and 18.90% respectively, compared to the baseline across four tasks related to respiratory event detection and audio record classification on the SPRSound database. In patient disease prediction tests on the ICBHI database, the architecture exhibited improvements of 23% in the mean of average score and harmonic score compared to the baseline. Furthermore, we developed a real-time respiratory sound discrimination system based on the Rene architecture, featuring a dual-thread design and compressed model parameters for simultaneous microphone recording and real-time dynamic decoding. Employing state-of-the-art Edge AI technology, this system enables rapid and accurate responses for respiratory sound auscultation, facilitating deployment on wearable clinical detection devices to capture incremental data, which can be synergistically evolved with large-scale models deployed on cloud servers for downstream tasks.
Off-Policy Reinforcement Learning for Efficient and Effective GAN Architecture Search
Jul 17, 2020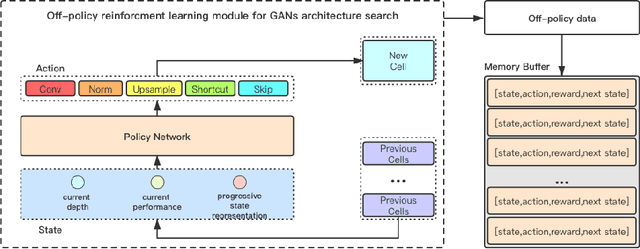
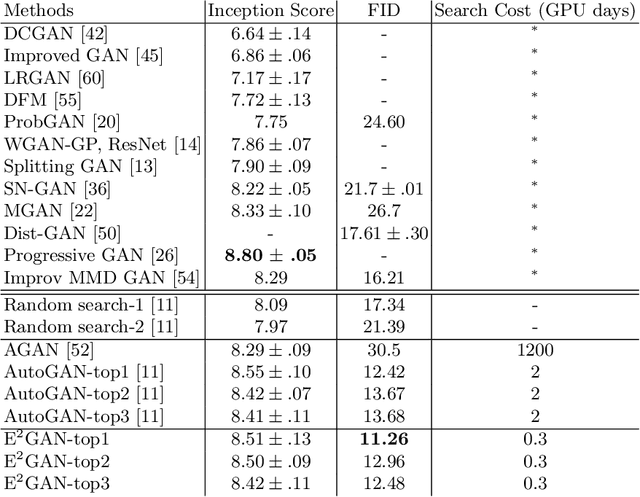
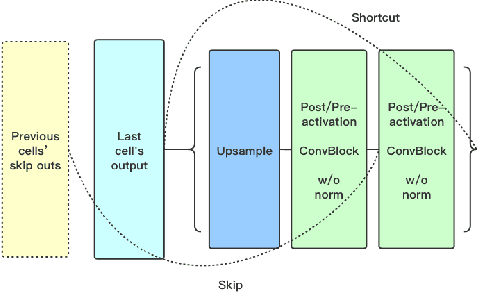

In this paper, we introduce a new reinforcement learning (RL) based neural architecture search (NAS) methodology for effective and efficient generative adversarial network (GAN) architecture search. The key idea is to formulate the GAN architecture search problem as a Markov decision process (MDP) for smoother architecture sampling, which enables a more effective RL-based search algorithm by targeting the potential global optimal architecture. To improve efficiency, we exploit an off-policy GAN architecture search algorithm that makes efficient use of the samples generated by previous policies. Evaluation on two standard benchmark datasets (i.e., CIFAR-10 and STL-10) demonstrates that the proposed method is able to discover highly competitive architectures for generally better image generation results with a considerably reduced computational burden: 7 GPU hours. Our code is available at https://github.com/Yuantian013/E2GAN.