 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Brain-inspired Embodied Intelligence for Fluid and Fast Reflexive Robotics Control
Jan 21, 2026Recent advances in embodied intelligence have leveraged massive scaling of data and model parameters to master natural-language command following and multi-task control. In contrast, biological systems demonstrate an innate ability to acquire skills rapidly from sparse experience. Crucially, current robotic policies struggle to replicate the dynamic stability, reflexive responsiveness, and temporal memory inherent in biological motion. Here we present Neuromorphic Vision-Language-Action (NeuroVLA), a framework that mimics the structural organization of the bio-nervous system between the cortex, cerebellum, and spinal cord. We adopt a system-level bio-inspired design: a high-level model plans goals, an adaptive cerebellum module stabilizes motion using high-frequency sensors feedback, and a bio-inspired spinal layer executes lightning-fast actions generation. NeuroVLA represents the first deployment of a neuromorphic VLA on physical robotics, achieving state-of-the-art performance. We observe the emergence of biological motor characteristics without additional data or special guidance: it stops the shaking in robotic arms, saves significant energy(only 0.4w on Neuromorphic Processor), shows temporal memory ability and triggers safety reflexes in less than 20 milliseconds.
From Events to Clarity: The Event-Guided Diffusion Framework for Dehazing
Nov 14, 2025Clear imaging under hazy conditions is a critical task. Prior-based and neural methods have improved results. However, they operate on RGB frames, which suffer from limited dynamic range. Therefore, dehazing remains ill-posed and can erase structure and illumination details. To address this, we use event cameras for dehazing for the \textbf{first time}. Event cameras offer much higher HDR ($120 dBvs.60 dB$) and microsecond latency, therefore they suit hazy scenes. In practice, transferring HDR cues from events to frames is hard because real paired data are scarce. To tackle this, we propose an event-guided diffusion model that utilizes the strong generative priors of diffusion models to reconstruct clear images from hazy inputs by effectively transferring HDR information from events. Specifically, we design an event-guided module that maps sparse HDR event features, \textit{e.g.,} edges, corners, into the diffusion latent space. This clear conditioning provides precise structural guidance during generation, improves visual realism, and reduces semantic drift. For real-world evaluation, we collect a drone dataset in heavy haze (AQI = 341) with synchronized RGB and event sensors. Experiments on two benchmarks and our dataset achieve state-of-the-art results.
Beyond Boundaries: Leveraging Vision Foundation Models for Source-Free Object Detection
Nov 10, 2025Source-Free Object Detection (SFOD) aims to adapt a source-pretrained object detector to a target domain without access to source data. However, existing SFOD methods predominantly rely on internal knowledge from the source model, which limits their capacity to generalize across domains and often results in biased pseudo-labels, thereby hindering both transferability and discriminability. In contrast, Vision Foundation Models (VFMs), pretrained on massive and diverse data, exhibit strong perception capabilities and broad generalization, yet their potential remains largely untapped in the SFOD setting. In this paper, we propose a novel SFOD framework that leverages VFMs as external knowledge sources to jointly enhance feature alignment and label quality. Specifically, we design three VFM-based modules: (1) Patch-weighted Global Feature Alignment (PGFA) distills global features from VFMs using patch-similarity-based weighting to enhance global feature transferability; (2) Prototype-based Instance Feature Alignment (PIFA) performs instance-level contrastive learning guided by momentum-updated VFM prototypes; and (3) Dual-source Enhanced Pseudo-label Fusion (DEPF) fuses predictions from detection VFMs and teacher models via an entropy-aware strategy to yield more reliable supervision. Extensive experiments on six benchmarks demonstrate that our method achieves state-of-the-art SFOD performance, validating the effectiveness of integrating VFMs to simultaneously improve transferability and discriminability.
See&Trek: Training-Free Spatial Prompting for Multimodal Large Language Model
Sep 19, 2025We introduce SEE&TREK, the first training-free prompting framework tailored to enhance the spatial understanding of Multimodal Large Language Models (MLLMS) under vision-only constraints. While prior efforts have incorporated modalities like depth or point clouds to improve spatial reasoning, purely visualspatial understanding remains underexplored. SEE&TREK addresses this gap by focusing on two core principles: increasing visual diversity and motion reconstruction. For visual diversity, we conduct Maximum Semantic Richness Sampling, which employs an off-the-shell perception model to extract semantically rich keyframes that capture scene structure. For motion reconstruction, we simulate visual trajectories and encode relative spatial positions into keyframes to preserve both spatial relations and temporal coherence. Our method is training&GPU-free, requiring only a single forward pass, and can be seamlessly integrated into existing MLLM'S. Extensive experiments on the VSI-B ENCH and STI-B ENCH show that S EE &T REK consistently boosts various MLLM S performance across diverse spatial reasoning tasks with the most +3.5% improvement, offering a promising path toward stronger spatial intelligence.
Multimodal 3D Genome Pre-training
Apr 12, 2025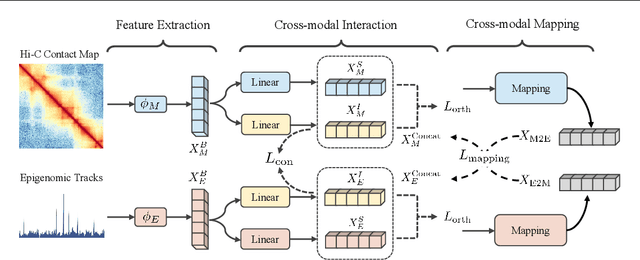
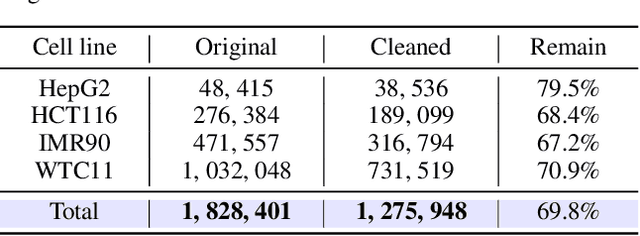
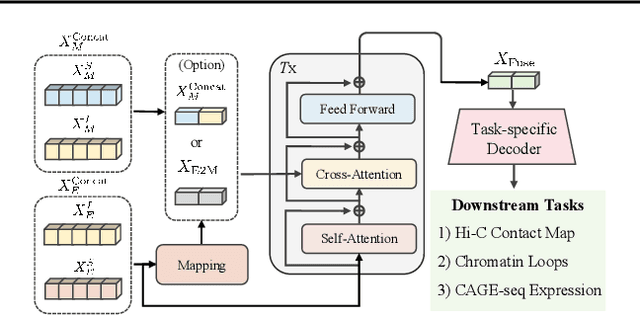
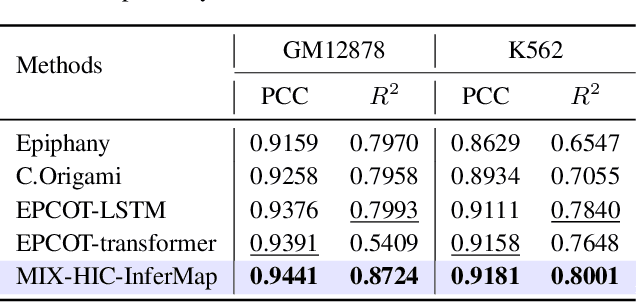
Deep learning techniques have driven significant progress in various analytical tasks within 3D genomics in computational biology. However, a holistic understanding of 3D genomics knowledge remains underexplored. Here, we propose MIX-HIC, the first multimodal foundation model of 3D genome that integrates both 3D genome structure and epigenomic tracks, which obtains unified and comprehensive semantics. For accurate heterogeneous semantic fusion, we design the cross-modal interaction and mapping blocks for robust unified representation, yielding the accurate aggregation of 3D genome knowledge. Besides, we introduce the first large-scale dataset comprising over 1 million pairwise samples of Hi-C contact maps and epigenomic tracks for high-quality pre-training, enabling the exploration of functional implications in 3D genomics. Extensive experiments show that MIX-HIC can significantly surpass existing state-of-the-art methods in diverse downstream tasks. This work provides a valuable resource for advancing 3D genomics research.
SEE: See Everything Every Time -- Adaptive Brightness Adjustment for Broad Light Range Images via Events
Feb 28, 2025Event cameras, with a high dynamic range exceeding $120dB$, significantly outperform traditional embedded cameras, robustly recording detailed changing information under various lighting conditions, including both low- and high-light situations. However, recent research on utilizing event data has primarily focused on low-light image enhancement, neglecting image enhancement and brightness adjustment across a broader range of lighting conditions, such as normal or high illumination. Based on this, we propose a novel research question: how to employ events to enhance and adaptively adjust the brightness of images captured under broad lighting conditions? To investigate this question, we first collected a new dataset, SEE-600K, consisting of 610,126 images and corresponding events across 202 scenarios, each featuring an average of four lighting conditions with over a 1000-fold variation in illumination. Subsequently, we propose a framework that effectively utilizes events to smoothly adjust image brightness through the use of prompts. Our framework captures color through sensor patterns, uses cross-attention to model events as a brightness dictionary, and adjusts the image's dynamic range to form a broad light-range representation (BLR), which is then decoded at the pixel level based on the brightness prompt. Experimental results demonstrate that our method not only performs well on the low-light enhancement dataset but also shows robust performance on broader light-range image enhancement using the SEE-600K dataset. Additionally, our approach enables pixel-level brightness adjustment, providing flexibility for post-processing and inspiring more imaging applications. The dataset and source code are publicly available at:https://github.com/yunfanLu/SEE.
EventVL: Understand Event Streams via Multimodal Large Language Model
Jan 23, 2025The event-based Vision-Language Model (VLM) recently has made good progress for practical vision tasks. However, most of these works just utilize CLIP for focusing on traditional perception tasks, which obstruct model understanding explicitly the sufficient semantics and context from event streams. To address the deficiency, we propose EventVL, the first generative event-based MLLM (Multimodal Large Language Model) framework for explicit semantic understanding. Specifically, to bridge the data gap for connecting different modalities semantics, we first annotate a large event-image/video-text dataset, containing almost 1.4 million high-quality pairs of data, which enables effective learning across various scenes, e.g., drive scene or human motion. After that, we design Event Spatiotemporal Representation to fully explore the comprehensive information by diversely aggregating and segmenting the event stream. To further promote a compact semantic space, Dynamic Semantic Alignment is introduced to improve and complete sparse semantic spaces of events. Extensive experiments show that our EventVL can significantly surpass existing MLLM baselines in event captioning and scene description generation tasks. We hope our research could contribute to the development of the event vision community.
Robot Trajectron: Trajectory Prediction-based Shared Control for Robot Manipulation
Feb 04, 2024



We address the problem of (a) predicting the trajectory of an arm reaching motion, based on a few seconds of the motion's onset, and (b) leveraging this predictor to facilitate shared-control manipulation tasks, easing the cognitive load of the operator by assisting them in their anticipated direction of motion. Our novel intent estimator, dubbed the \emph{Robot Trajectron} (RT), produces a probabilistic representation of the robot's anticipated trajectory based on its recent position, velocity and acceleration history. Taking arm dynamics into account allows RT to capture the operator's intent better than other SOTA models that only use the arm's position, making it particularly well-suited to assist in tasks where the operator's intent is susceptible to change. We derive a novel shared-control solution that combines RT's predictive capacity to a representation of the locations of potential reaching targets. Our experiments demonstrate RT's effectiveness in both intent estimation and shared-control tasks. We will make the code and data supporting our experiments publicly available at https://github.com/mousecpn/Robot-Trajectron.git.