 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAG-REPA: Causal Layer Selection for Representation Alignment in Audio Flow Matching
Mar 01, 2026REPresentation Alignment (REPA) improves the training of generative flow models by aligning intermediate hidden states with pretrained teacher features, but its effectiveness in token-conditioned audio Flow Matching critically depends on the choice of supervised layers, which is typically made heuristically based on the depth. In this work, we introduce Attribution-Guided REPresentation Alignment (AG-REPA), a novel causal layer selection strategy for representation alignment in audio Flow Matching. Firstly, we find that layers that best store semantic/acoustic information (high teacher-space similarity) are not necessarily the layers that contribute most to the velocity field that drives generation, and we call it Store-Contribute Dissociation (SCD). To turn this insight into an actionable training guidance, we propose a forward-only gate ablation (FoG-A) that quantifies each layer's causal contribution via the induced change in the predicted velocity field, enabling sparse layer selection and adaptive weighting for alignment. Across unified speech and general-audio training (LibriSpeech + AudioSet) under different token-conditioning topologies, AG-REPA consistently outperforms REPA baselines. Overall, our results show that alignment is most effective when applied to the causally dominant layers that drive the velocity field, rather than to layers that are representationally rich but functionally passive.
Generative Recommendation for Large-Scale Advertising
Feb 26, 2026Generative recommendation has recently attracted widespread attention in industry due to its potential for scaling and stronger model capacity. However, deploying real-time generative recommendation in large-scale advertising requires designs beyond large-language-model (LLM)-style training and serving recipes. We present a production-oriented generative recommender co-designed across architecture, learning, and serving, named GR4AD (Generative Recommendation for ADdvertising). As for tokenization, GR4AD proposes UA-SID (Unified Advertisement Semantic ID) to capture complicated business information. Furthermore, GR4AD introduces LazyAR, a lazy autoregressive decoder that relaxes layer-wise dependencies for short, multi-candidate generation, preserving effectiveness while reducing inference cost, which facilitates scaling under fixed serving budgets. To align optimization with business value, GR4AD employs VSL (Value-Aware Supervised Learning) and proposes RSPO (Ranking-Guided Softmax Preference Optimization), a ranking-aware, list-wise reinforcement learning algorithm that optimizes value-based rewards under list-level metrics for continual online updates. For online inference, we further propose dynamic beam serving, which adapts beam width across generation levels and online load to control compute. Large-scale online A/B tests show up to 4.2% ad revenue improvement over an existing DLRM-based stack, with consistent gains from both model scaling and inference-time scaling. GR4AD has been fully deployed in Kuaishou advertising system with over 400 million users and achieves high-throughput real-time serving.
Resp-Agent: An Agent-Based System for Multimodal Respiratory Sound Generation and Disease Diagnosis
Feb 19, 2026Deep learning-based respiratory auscultation is currently hindered by two fundamental challenges: (i) inherent information loss, as converting signals into spectrograms discards transient acoustic events and clinical context; (ii) limited data availability, exacerbated by severe class imbalance. To bridge these gaps, we present Resp-Agent, an autonomous multimodal system orchestrated by a novel Active Adversarial Curriculum Agent (Thinker-A$^2$CA). Unlike static pipelines, Thinker-A$^2$CA serves as a central controller that actively identifies diagnostic weaknesses and schedules targeted synthesis in a closed loop. To address the representation gap, we introduce a Modality-Weaving Diagnoser that weaves EHR data with audio tokens via Strategic Global Attention and sparse audio anchors, capturing both long-range clinical context and millisecond-level transients. To address the data gap, we design a Flow Matching Generator that adapts a text-only Large Language Model (LLM) via modality injection, decoupling pathological content from acoustic style to synthesize hard-to-diagnose samples. As a foundation for these efforts, we introduce Resp-229k, a benchmark corpus of 229k recordings paired with LLM-distilled clinical narratives. Extensive experiments demonstrate that Resp-Agent consistently outperforms prior approaches across diverse evaluation settings, improving diagnostic robustness under data scarcity and long-tailed class imbalance. Our code and data are available at https://github.com/zpforlove/Resp-Agent.
* 24 pages, 3 figures. Published as a conference paper at ICLR 2026
Instruction Anchors: Dissecting the Causal Dynamics of Modality Arbitration
Feb 03, 2026Modality following serves as the capacity of multimodal large language models (MLLMs) to selectively utilize multimodal contexts based on user instructions. It is fundamental to ensuring safety and reliability in real-world deployments. However, the underlying mechanisms governing this decision-making process remain poorly understood. In this paper, we investigate its working mechanism through an information flow lens. Our findings reveal that instruction tokens function as structural anchors for modality arbitration: Shallow attention layers perform non-selective information transfer, routing multimodal cues to these anchors as a latent buffer; Modality competition is resolved within deep attention layers guided by the instruction intent, while MLP layers exhibit semantic inertia, acting as an adversarial force. Furthermore, we identify a sparse set of specialized attention heads that drive this arbitration. Causal interventions demonstrate that manipulating a mere $5\%$ of these critical heads can decrease the modality-following ratio by $60\%$ through blocking, or increase it by $60\%$ through targeted amplification of failed samples. Our work provides a substantial step toward model transparency and offers a principled framework for the orchestration of multimodal information in MLLMs.
MedSpeak: A Knowledge Graph-Aided ASR Error Correction Framework for Spoken Medical QA
Feb 01, 2026Spoken question-answering (SQA) systems relying on automatic speech recognition (ASR) often struggle with accurately recognizing medical terminology. To this end, we propose MedSpeak, a novel knowledge graph-aided ASR error correction framework that refines noisy transcripts and improves downstream answer prediction by leveraging both semantic relationships and phonetic information encoded in a medical knowledge graph, together with the reasoning power of LLMs. Comprehensive experimental results on benchmarks demonstrate that MedSpeak significantly improves the accuracy of medical term recognition and overall medical SQA performance, establishing MedSpeak as a state-of-the-art solution for medical SQA. The code is available at https://github.com/RainieLLM/MedSpeak.
PhyAVBench: A Challenging Audio Physics-Sensitivity Benchmark for Physically Grounded Text-to-Audio-Video Generation
Dec 30, 2025Text-to-audio-video (T2AV) generation underpins a wide range of applications demanding realistic audio-visual content, including virtual reality, world modeling, gaming, and filmmaking. However, existing T2AV models remain incapable of generating physically plausible sounds, primarily due to their limited understanding of physical principles. To situate current research progress, we present PhyAVBench, a challenging audio physics-sensitivity benchmark designed to systematically evaluate the audio physics grounding capabilities of existing T2AV models. PhyAVBench comprises 1,000 groups of paired text prompts with controlled physical variables that implicitly induce sound variations, enabling a fine-grained assessment of models' sensitivity to changes in underlying acoustic conditions. We term this evaluation paradigm the Audio-Physics Sensitivity Test (APST). Unlike prior benchmarks that primarily focus on audio-video synchronization, PhyAVBench explicitly evaluates models' understanding of the physical mechanisms underlying sound generation, covering 6 major audio physics dimensions, 4 daily scenarios (music, sound effects, speech, and their mix), and 50 fine-grained test points, ranging from fundamental aspects such as sound diffraction to more complex phenomena, e.g., Helmholtz resonance. Each test point consists of multiple groups of paired prompts, where each prompt is grounded by at least 20 newly recorded or collected real-world videos, thereby minimizing the risk of data leakage during model pre-training. Both prompts and videos are iteratively refined through rigorous human-involved error correction and quality control to ensure high quality. We argue that only models with a genuine grasp of audio-related physical principles can generate physically consistent audio-visual content. We hope PhyAVBench will stimulate future progress in this critical yet largely unexplored domain.
Image Generation Method Based on Heat Diffusion Models
Apr 28, 2025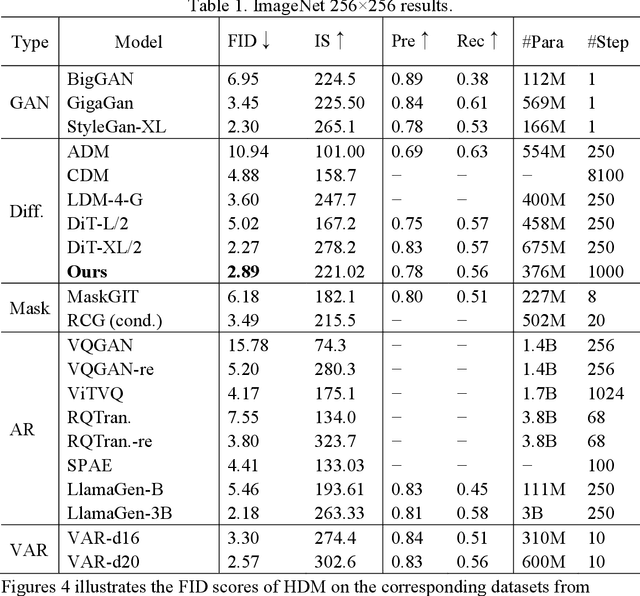
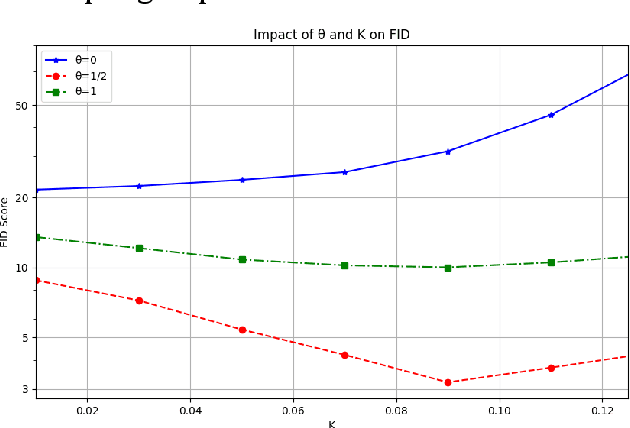
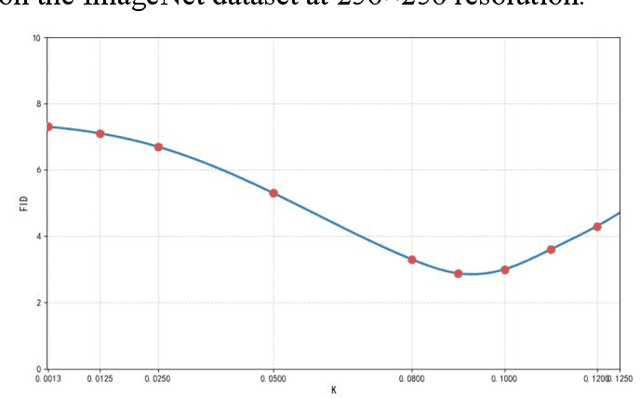

Denoising Diffusion Probabilistic Models (DDPMs) achieve high-quality image generation without adversarial training, but they process images as a whole. Since adjacent pixels are highly likely to belong to the same object, we propose the Heat Diffusion Model (HDM) to further preserve image details and generate more realistic images. HDM is a model that incorporates pixel-level operations while maintaining the same training process as DDPM. In HDM, the discrete form of the two-dimensional heat equation is integrated into the diffusion and generation formulas of DDPM, enabling the model to compute relationships between neighboring pixels during image processing. Our experiments demonstrate that HDM can generate higher-quality samples compared to models such as DDPM, Consistency Diffusion Models (CDM), Latent Diffusion Models (LDM), and Vector Quantized Generative Adversarial Networks (VQGAN).
Multimodal 3D Genome Pre-training
Apr 12, 2025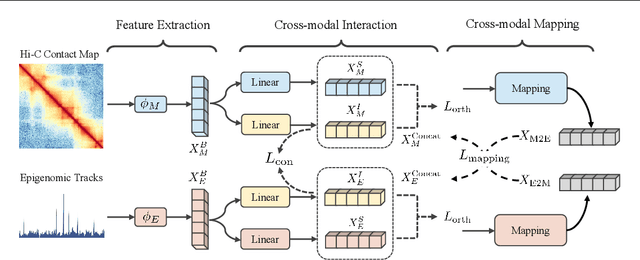
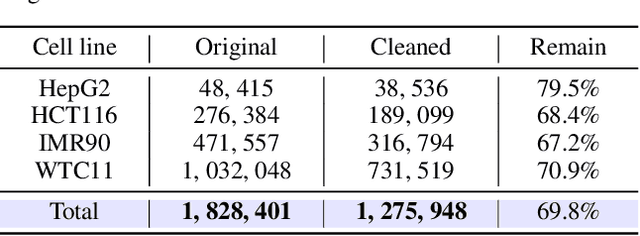
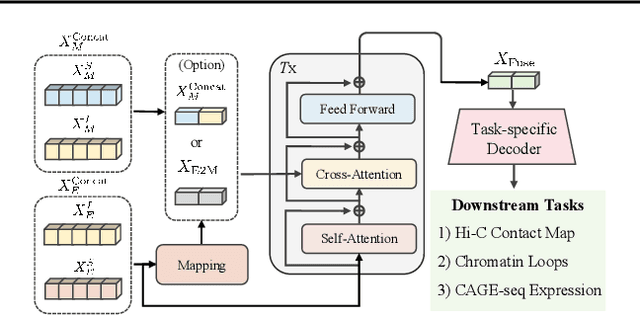
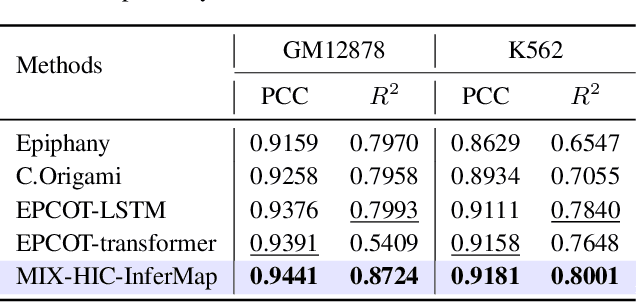
Deep learning techniques have driven significant progress in various analytical tasks within 3D genomics in computational biology. However, a holistic understanding of 3D genomics knowledge remains underexplored. Here, we propose MIX-HIC, the first multimodal foundation model of 3D genome that integrates both 3D genome structure and epigenomic tracks, which obtains unified and comprehensive semantics. For accurate heterogeneous semantic fusion, we design the cross-modal interaction and mapping blocks for robust unified representation, yielding the accurate aggregation of 3D genome knowledge. Besides, we introduce the first large-scale dataset comprising over 1 million pairwise samples of Hi-C contact maps and epigenomic tracks for high-quality pre-training, enabling the exploration of functional implications in 3D genomics. Extensive experiments show that MIX-HIC can significantly surpass existing state-of-the-art methods in diverse downstream tasks. This work provides a valuable resource for advancing 3D genomics research.
DEMENTIA-PLAN: An Agent-Based Framework for Multi-Knowledge Graph Retrieval-Augmented Generation in Dementia Care
Mar 26, 2025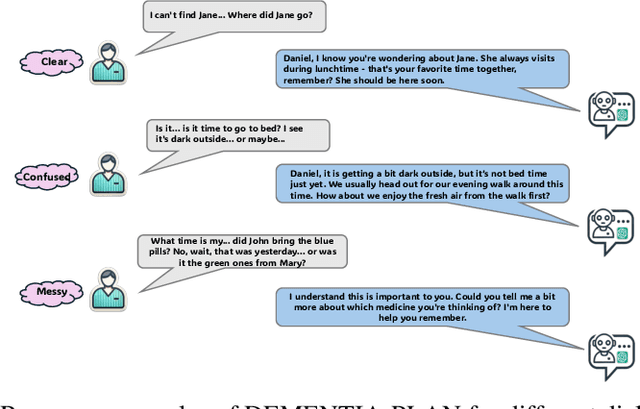

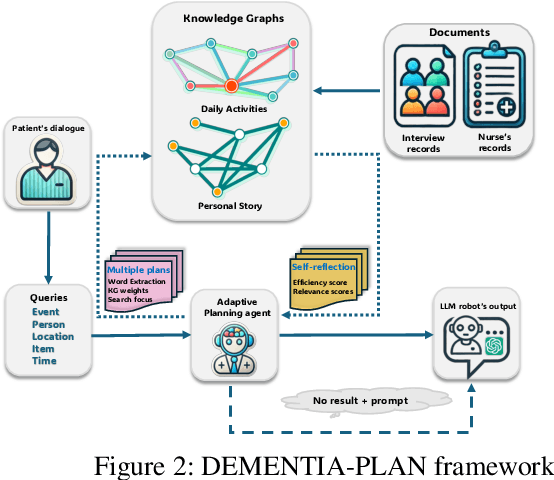

Mild-stage dementia patients primarily experience two critical symptoms: severe memory loss and emotional instability. To address these challenges, we propose DEMENTIA-PLAN, an innovative retrieval-augmented generation framework that leverages large language models to enhance conversational support. Our model employs a multiple knowledge graph architecture, integrating various dimensional knowledge representations including daily routine graphs and life memory graphs. Through this multi-graph architecture, DEMENTIA-PLAN comprehensively addresses both immediate care needs and facilitates deeper emotional resonance through personal memories, helping stabilize patient mood while providing reliable memory support. Our notable innovation is the self-reflection planning agent, which systematically coordinates knowledge retrieval and semantic integration across multiple knowledge graphs, while scoring retrieved content from daily routine and life memory graphs to dynamically adjust their retrieval weights for optimized response generation. DEMENTIA-PLAN represents a significant advancement in the clinical application of large language models for dementia care, bridging the gap between AI tools and caregivers interventions.
Contextual Gesture: Co-Speech Gesture Video Generation through Context-aware Gesture Representation
Feb 11, 2025Co-speech gesture generation is crucial for creating lifelike avatars and enhancing human-computer interactions by synchronizing gestures with speech. Despite recent advancements, existing methods struggle with accurately identifying the rhythmic or semantic triggers from audio for generating contextualized gesture patterns and achieving pixel-level realism. To address these challenges, we introduce Contextual Gesture, a framework that improves co-speech gesture video generation through three innovative components: (1) a chronological speech-gesture alignment that temporally connects two modalities, (2) a contextualized gesture tokenization that incorporate speech context into motion pattern representation through distillation, and (3) a structure-aware refinement module that employs edge connection to link gesture keypoints to improve video generation. Our extensive experiments demonstrate that Contextual Gesture not only produces realistic and speech-aligned gesture videos but also supports long-sequence generation and video gesture editing applications, shown in Fig.1 Project Page: https://andypinxinliu.github.io/Contextual-Gesture/.