 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoiceTTA: Enhancing Zero-Shot Text-to-Speech via Reinforcement Learning-Based Test-Time Adaptation
Jun 25, 2026Recently, zero-shot text-to-speech (TTS) has enabled high-fidelity and expressive speech synthesis, but it often fails to imitate unseen speaking styles from uncommon scenarios (e.g., crosstalk, dialects). Moreover, fine-tuning pretrained models requires large, high-quality datasets, limiting rapid personalization. We propose VoiceTTA, a reinforcement learning-based test-time adaptation (TTA) method that improves voice imitation of pretrained zero-shot TTS models. VoiceTTA introduces two style rewards based on coefficient-of-variation differences of F0 and energy, combined with speaker similarity and intelligibility (WER from a pretrained Whisper model), and optimizes learnable prefixes via group relative preference optimization (GRPO) in a flow matching-based model at inference time. Extensive experiments demonstrate substantial improvements on uncommon speech prompts, outperforming state-of-the-art baselines. Audio samples are available at https://voicetta.pages.dev/
Audio-DeepThinker: Progressive Reasoning-Aware Reinforcement Learning for High-Quality Chain-of-Thought Emergence in Audio Language Models
Apr 20, 2026Large Audio-Language Models (LALMs) have made significant progress in audio understanding, yet they primarily operate as perception-and-answer systems without explicit reasoning processes. Existing methods for enhancing audio reasoning rely either on supervised chain-of-thought (CoT) fine-tuning, which is limited by training data quality, or on reinforcement learning (RL) with coarse rewards that do not directly evaluate reasoning quality. As a result, the generated reasoning chains often appear well-structured yet lack specific acoustic grounding. We propose Audio-DeepThinker, a framework built on two core ideas. First, we introduce a hybrid reasoning similarity reward that directly supervises the quality of generated reasoning chains by combining an LLM evaluator assessing logical path alignment, key step coverage, and analytical depth with an embedding similarity component enforcing semantic alignment with reference reasoning chains. Second, we propose a progressive two-stage curriculum that enables high-quality CoT reasoning to emerge through pure RL exploration, without any supervised reasoning fine-tuning, from an instruction-tuned model that possesses no prior chain-of-thought capability. Stage 1 trains on foundational audio QA with the hybrid reward to foster basic reasoning patterns, while Stage 2 shifts to acoustically challenging boundary cases with an LLM-only reward for greater reasoning diversity. Audio-DeepThinker achieves state-of-the-art results on MMAR (74.0%), MMAU-test-mini (78.5%), and MMSU (77.26%), winning 1st Place in the Interspeech 2026 Audio Reasoning Challenge (Single Model Track). Interpretability analyses further reveal that RL training primarily reshapes upper-layer MoE gating mechanisms and that reasoning tokens crystallize progressively in the upper transformer layers, offering mechanistic insights into how audio reasoning emerges through exploration.
Boosting ASR Robustness via Test-Time Reinforcement Learning with Audio-Text Semantic Rewards
Mar 05, 2026Recently, Automatic Speech Recognition (ASR) systems (e.g., Whisper) have achieved remarkable accuracy improvements but remain highly sensitive to real-world unseen data (data with large distribution shifts), including noisy environments and diverse accents. To address this issue, test-time adaptation (TTA) has shown great potential in improving the model adaptability at inference time without ground-truth labels, and existing TTA methods often rely on pseudo-labeling or entropy minimization. However, by treating model confidence as a learning signal, these methods may reinforce high-confidence errors, leading to confirmation bias that undermines adaptation. To overcome these limitations, we present ASR-TRA, a novel Test-time Reinforcement Adaptation framework inspired by causal intervention. More precisely, our method introduces a learnable decoder prompt and utilizes temperature-controlled stochastic decoding to generate diverse transcription candidates. These are scored by a reward model that measures audio-text semantic alignment, and the resulting feedback is used to update both model and prompt parameters via reinforcement learning. Comprehensive experiments on LibriSpeech with synthetic noise and L2 Arctic accented English datasets demonstrate that our method achieves higher accuracy while maintaining lower latency than existing TTA baselines. Ablation studies further confirm the effectiveness of combining audio and language-based rewards, highlighting our method's enhanced stability and interpretability. Overall, our approach provides a practical and robust solution for deploying ASR systems in challenging real-world conditions.
AG-REPA: Causal Layer Selection for Representation Alignment in Audio Flow Matching
Mar 01, 2026REPresentation Alignment (REPA) improves the training of generative flow models by aligning intermediate hidden states with pretrained teacher features, but its effectiveness in token-conditioned audio Flow Matching critically depends on the choice of supervised layers, which is typically made heuristically based on the depth. In this work, we introduce Attribution-Guided REPresentation Alignment (AG-REPA), a novel causal layer selection strategy for representation alignment in audio Flow Matching. Firstly, we find that layers that best store semantic/acoustic information (high teacher-space similarity) are not necessarily the layers that contribute most to the velocity field that drives generation, and we call it Store-Contribute Dissociation (SCD). To turn this insight into an actionable training guidance, we propose a forward-only gate ablation (FoG-A) that quantifies each layer's causal contribution via the induced change in the predicted velocity field, enabling sparse layer selection and adaptive weighting for alignment. Across unified speech and general-audio training (LibriSpeech + AudioSet) under different token-conditioning topologies, AG-REPA consistently outperforms REPA baselines. Overall, our results show that alignment is most effective when applied to the causally dominant layers that drive the velocity field, rather than to layers that are representationally rich but functionally passive.
Resp-Agent: An Agent-Based System for Multimodal Respiratory Sound Generation and Disease Diagnosis
Feb 19, 2026Deep learning-based respiratory auscultation is currently hindered by two fundamental challenges: (i) inherent information loss, as converting signals into spectrograms discards transient acoustic events and clinical context; (ii) limited data availability, exacerbated by severe class imbalance. To bridge these gaps, we present Resp-Agent, an autonomous multimodal system orchestrated by a novel Active Adversarial Curriculum Agent (Thinker-A$^2$CA). Unlike static pipelines, Thinker-A$^2$CA serves as a central controller that actively identifies diagnostic weaknesses and schedules targeted synthesis in a closed loop. To address the representation gap, we introduce a Modality-Weaving Diagnoser that weaves EHR data with audio tokens via Strategic Global Attention and sparse audio anchors, capturing both long-range clinical context and millisecond-level transients. To address the data gap, we design a Flow Matching Generator that adapts a text-only Large Language Model (LLM) via modality injection, decoupling pathological content from acoustic style to synthesize hard-to-diagnose samples. As a foundation for these efforts, we introduce Resp-229k, a benchmark corpus of 229k recordings paired with LLM-distilled clinical narratives. Extensive experiments demonstrate that Resp-Agent consistently outperforms prior approaches across diverse evaluation settings, improving diagnostic robustness under data scarcity and long-tailed class imbalance. Our code and data are available at https://github.com/zpforlove/Resp-Agent.
* 24 pages, 3 figures. Published as a conference paper at ICLR 2026
PhyAVBench: A Challenging Audio Physics-Sensitivity Benchmark for Physically Grounded Text-to-Audio-Video Generation
Dec 30, 2025Text-to-audio-video (T2AV) generation underpins a wide range of applications demanding realistic audio-visual content, including virtual reality, world modeling, gaming, and filmmaking. However, existing T2AV models remain incapable of generating physically plausible sounds, primarily due to their limited understanding of physical principles. To situate current research progress, we present PhyAVBench, a challenging audio physics-sensitivity benchmark designed to systematically evaluate the audio physics grounding capabilities of existing T2AV models. PhyAVBench comprises 1,000 groups of paired text prompts with controlled physical variables that implicitly induce sound variations, enabling a fine-grained assessment of models' sensitivity to changes in underlying acoustic conditions. We term this evaluation paradigm the Audio-Physics Sensitivity Test (APST). Unlike prior benchmarks that primarily focus on audio-video synchronization, PhyAVBench explicitly evaluates models' understanding of the physical mechanisms underlying sound generation, covering 6 major audio physics dimensions, 4 daily scenarios (music, sound effects, speech, and their mix), and 50 fine-grained test points, ranging from fundamental aspects such as sound diffraction to more complex phenomena, e.g., Helmholtz resonance. Each test point consists of multiple groups of paired prompts, where each prompt is grounded by at least 20 newly recorded or collected real-world videos, thereby minimizing the risk of data leakage during model pre-training. Both prompts and videos are iteratively refined through rigorous human-involved error correction and quality control to ensure high quality. We argue that only models with a genuine grasp of audio-related physical principles can generate physically consistent audio-visual content. We hope PhyAVBench will stimulate future progress in this critical yet largely unexplored domain.
Hi-Reco: High-Fidelity Real-Time Conversational Digital Humans
Nov 16, 2025High-fidelity digital humans are increasingly used in interactive applications, yet achieving both visual realism and real-time responsiveness remains a major challenge. We present a high-fidelity, real-time conversational digital human system that seamlessly combines a visually realistic 3D avatar, persona-driven expressive speech synthesis, and knowledge-grounded dialogue generation. To support natural and timely interaction, we introduce an asynchronous execution pipeline that coordinates multi-modal components with minimal latency. The system supports advanced features such as wake word detection, emotionally expressive prosody, and highly accurate, context-aware response generation. It leverages novel retrieval-augmented methods, including history augmentation to maintain conversational flow and intent-based routing for efficient knowledge access. Together, these components form an integrated system that enables responsive and believable digital humans, suitable for immersive applications in communication, education, and entertainment.
Sage Deer: A Super-Aligned Driving Generalist Is Your Copilot
May 15, 2025The intelligent driving cockpit, an important part of intelligent driving, needs to match different users' comfort, interaction, and safety needs. This paper aims to build a Super-Aligned and GEneralist DRiving agent, SAGE DeeR. Sage Deer achieves three highlights: (1) Super alignment: It achieves different reactions according to different people's preferences and biases. (2) Generalist: It can understand the multi-view and multi-mode inputs to reason the user's physiological indicators, facial emotions, hand movements, body movements, driving scenarios, and behavioral decisions. (3) Self-Eliciting: It can elicit implicit thought chains in the language space to further increase generalist and super-aligned abilities. Besides, we collected multiple data sets and built a large-scale benchmark. This benchmark measures the deer's perceptual decision-making ability and the super alignment's accuracy.
Towards Controllable Speech Synthesis in the Era of Large Language Models: A Survey
Dec 09, 2024



Text-to-speech (TTS), also known as speech synthesis, is a prominent research area that aims to generate natural-sounding human speech from text. Recently, with the increasing industrial demand, TTS technologies have evolved beyond synthesizing human-like speech to enabling controllable speech generation. This includes fine-grained control over various attributes of synthesized speech such as emotion, prosody, timbre, and duration. Besides, advancements in deep learning, such as diffusion and large language models, have significantly enhanced controllable TTS over the past several years. In this paper, we conduct a comprehensive survey of controllable TTS, covering approaches ranging from basic control techniques to methods utilizing natural language prompts, aiming to provide a clear understanding of the current state of research. We examine the general controllable TTS pipeline, challenges, model architectures, and control strategies, offering a comprehensive and clear taxonomy of existing methods. Additionally, we provide a detailed summary of datasets and evaluation metrics and shed some light on the applications and future directions of controllable TTS. To the best of our knowledge, this survey paper provides the first comprehensive review of emerging controllable TTS methods, which can serve as a beneficial resource for both academic researchers and industry practitioners.
Pseudo Replay-based Class Continual Learning for Online New Category Anomaly Detection in Additive Manufacturing
Dec 05, 2023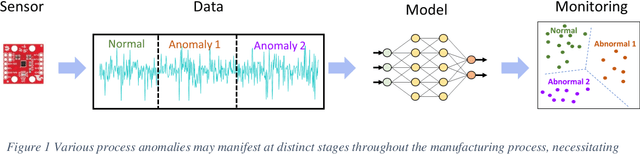
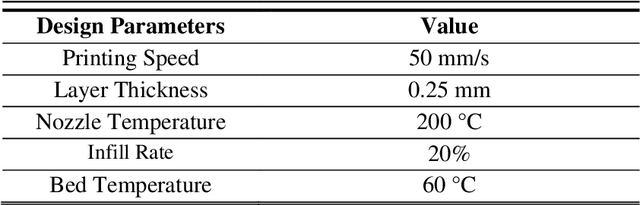
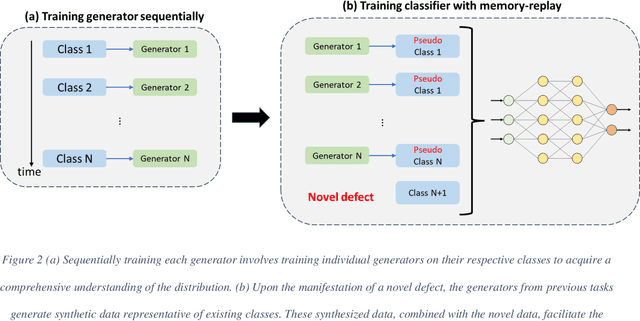

The incorporation of advanced sensors and machine learning techniques has enabled modern manufacturing enterprises to perform data-driven in-situ quality monitoring based on the sensor data collected in manufacturing processes. However, one critical challenge is that newly presented defect category may manifest as the manufacturing process continues, resulting in monitoring performance deterioration of previously trained machine learning models. Hence, there is an increasing need for empowering machine learning model to learn continually. Among all continual learning methods, memory-based continual learning has the best performance but faces the constraints of data storage capacity. To address this issue, this paper develops a novel pseudo replay-based continual learning by integrating class incremental learning and oversampling-based data generation. Without storing all the data, the developed framework could generate high-quality data representing previous classes to train machine learning model incrementally when new category anomaly occurs. In addition, it could even enhance the monitoring performance since it also effectively improves the data quality. The effectiveness of the proposed framework is validated in an additive manufacturing process, which leverages supervised classification problem for anomaly detection. The experimental results show that the developed method is very promising in detecting novel anomaly while maintaining a good performance on the previous task and brings up more flexibility in model architecture.