 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSOLARIS: Speculative Offloading of Latent-bAsed Representation for Inference Scaling
Apr 13, 2026Recent advances in recommendation scaling laws have led to foundation models of unprecedented complexity. While these models offer superior performance, their computational demands make real-time serving impractical, often forcing practitioners to rely on knowledge distillation-compromising serving quality for efficiency. To address this challenge, we present SOLARIS (Speculative Offloading of Latent-bAsed Representation for Inference Scaling), a novel framework inspired by speculative decoding. SOLARIS proactively precomputes user-item interaction embeddings by predicting which user-item pairs are likely to appear in future requests, and asynchronously generating their foundation model representations ahead of time. This approach decouples the costly foundation model inference from the latency-critical serving path, enabling real-time knowledge transfer from models previously considered too expensive for online use. Deployed across Meta's advertising system serving billions of daily requests, SOLARIS achieves 0.67% revenue-driving top-line metrics gain, demonstrating its effectiveness at scale.
EgoForge: Goal-Directed Egocentric World Simulator
Mar 20, 2026Generative world models have shown promise for simulating dynamic environments, yet egocentric video remains challenging due to rapid viewpoint changes, frequent hand-object interactions, and goal-directed procedures whose evolution depends on latent human intent. Existing approaches either focus on hand-centric instructional synthesis with limited scene evolution, perform static view translation without modeling action dynamics, or rely on dense supervision, such as camera trajectories, long video prefixes, synchronized multicamera capture, etc. In this work, we introduce EgoForge, an egocentric goal-directed world simulator that generates coherent, first-person video rollouts from minimal static inputs: a single egocentric image, a high-level instruction, and an optional auxiliary exocentric view. To improve intent alignment and temporal consistency, we propose VideoDiffusionNFT, a trajectory-level reward-guided refinement that optimizes goal completion, temporal causality, scene consistency, and perceptual fidelity during diffusion sampling. Extensive experiments show EgoForge achieves consistent gains in semantic alignment, geometric stability, and motion fidelity over strong baselines, and robust performance in real-world smart-glasses experiments.
EvalMVX: A Unified Benchmarking for Neural 3D Reconstruction under Diverse Multiview Setups
Mar 04, 2026Recent advancements in neural surface reconstruction have significantly enhanced 3D reconstruction. However, current real world datasets mainly focus on benchmarking multiview stereo (MVS) based on RGB inputs. Multiview photometric stereo (MVPS) and multiview shape from polarization (MVSfP), though indispensable on high-fidelity surface reconstruction and sparse inputs, have not been quantitatively assessed together with MVS. To determine the working range of different MVX (MVS, MVSfP, and MVPS) techniques, we propose EvalMVX, a real-world dataset containing $25$ objects, each captured with a polarized camera under $20$ varying views and $17$ light conditions including OLAT and natural illumination, leading to $8,500$ images. Each object includes aligned ground-truth 3D mesh, facilitating quantitative benchmarking of MVX methods simultaneously. Based on our EvalMVX, we evaluate $13$ MVX methods published in recent years, record the best-performing methods, and identify open problems under diverse geometric details and reflectance types. We hope EvalMVX and the benchmarking results can inspire future research on multiview 3D reconstruction.
RepSPD: Enhancing SPD Manifold Representation in EEGs via Dynamic Graphs
Feb 26, 2026Decoding brain activity from electroencephalography (EEG) is crucial for neuroscience and clinical applications. Among recent advances in deep learning for EEG, geometric learning stands out as its theoretical underpinnings on symmetric positive definite (SPD) allows revealing structural connectivity analysis in a physics-grounded manner. However, current SPD-based methods focus predominantly on statistical aggregation of EEGs, with frequency-specific synchronization and local topological structures of brain regions neglected. Given this, we propose RepSPD, a novel geometric deep learning (GDL)-based model. RepSPD implements a cross-attention mechanism on the Riemannian manifold to modulate the geometric attributes of SPD with graph-derived functional connectivity features. On top of this, we introduce a global bidirectional alignment strategy to reshape tangent-space embeddings, mitigating geometric distortions caused by curvature and thereby enhancing geometric consistency. Extensive experiments demonstrate that our proposed framework significantly outperforms existing EEG representation methods, exhibiting superior robustness and generalization capabilities.
Toward Cognitive Supersensing in Multimodal Large Language Model
Feb 02, 2026Multimodal Large Language Models (MLLMs) have achieved remarkable success in open-vocabulary perceptual tasks, yet their ability to solve complex cognitive problems remains limited, especially when visual details are abstract and require visual memory. Current approaches primarily scale Chain-of-Thought (CoT) reasoning in the text space, even when language alone is insufficient for clear and structured reasoning, and largely neglect visual reasoning mechanisms analogous to the human visuospatial sketchpad and visual imagery. To mitigate this deficiency, we introduce Cognitive Supersensing, a novel training paradigm that endows MLLMs with human-like visual imagery capabilities by integrating a Latent Visual Imagery Prediction (LVIP) head that jointly learns sequences of visual cognitive latent embeddings and aligns them with the answer, thereby forming vision-based internal reasoning chains. We further introduce a reinforcement learning stage that optimizes text reasoning paths based on this grounded visual latent. To evaluate the cognitive capabilities of MLLMs, we present CogSense-Bench, a comprehensive visual question answering (VQA) benchmark assessing five cognitive dimensions. Extensive experiments demonstrate that MLLMs trained with Cognitive Supersensing significantly outperform state-of-the-art baselines on CogSense-Bench and exhibit superior generalization on out-of-domain mathematics and science VQA benchmarks, suggesting that internal visual imagery is potentially key to bridging the gap between perceptual recognition and cognitive understanding. We will open-source the CogSense-Bench and our model weights.
KaoLRM: Repurposing Pre-trained Large Reconstruction Models for Parametric 3D Face Reconstruction
Jan 19, 2026We propose KaoLRM to re-target the learned prior of the Large Reconstruction Model (LRM) for parametric 3D face reconstruction from single-view images. Parametric 3D Morphable Models (3DMMs) have been widely used for facial reconstruction due to their compact and interpretable parameterization, yet existing 3DMM regressors often exhibit poor consistency across varying viewpoints. To address this, we harness the pre-trained 3D prior of LRM and incorporate FLAME-based 2D Gaussian Splatting into LRM's rendering pipeline. Specifically, KaoLRM projects LRM's pre-trained triplane features into the FLAME parameter space to recover geometry, and models appearance via 2D Gaussian primitives that are tightly coupled to the FLAME mesh. The rich prior enables the FLAME regressor to be aware of the 3D structure, leading to accurate and robust reconstructions under self-occlusions and diverse viewpoints. Experiments on both controlled and in-the-wild benchmarks demonstrate that KaoLRM achieves superior reconstruction accuracy and cross-view consistency, while existing methods remain sensitive to viewpoint variations. The code is released at https://github.com/CyberAgentAILab/KaoLRM.
PALM: Progress-Aware Policy Learning via Affordance Reasoning for Long-Horizon Robotic Manipulation
Jan 11, 2026Recent advancements in vision-language-action (VLA) models have shown promise in robotic manipulation, yet they continue to struggle with long-horizon, multi-step tasks. Existing methods lack internal reasoning mechanisms that can identify task-relevant interaction cues or track progress within a subtask, leading to critical execution errors such as repeated actions, missed steps, and premature termination. To address these challenges, we introduce PALM, a VLA framework that structures policy learning around interaction-centric affordance reasoning and subtask progress cues. PALM distills complementary affordance representations that capture object relevance, contact geometry, spatial placements, and motion dynamics, and serve as task-relevant anchors for visuomotor control. To further stabilize long-horizon execution, PALM predicts continuous within-subtask progress, enabling seamless subtask transitions. Across extensive simulation and real-world experiments, PALM consistently outperforms baselines, achieving a 91.8% success rate on LIBERO-LONG, a 12.5% improvement in average length on CALVIN ABC->D, and a 2x improvement over real-world baselines across three long-horizon generalization settings.
HOLO: Homography-Guided Pose Estimator Network for Fine-Grained Visual Localization on SD Maps
Jan 07, 2026Visual localization on standard-definition (SD) maps has emerged as a promising low-cost and scalable solution for autonomous driving. However, existing regression-based approaches often overlook inherent geometric priors, resulting in suboptimal training efficiency and limited localization accuracy. In this paper, we propose a novel homography-guided pose estimator network for fine-grained visual localization between multi-view images and standard-definition (SD) maps. We construct input pairs that satisfy a homography constraint by projecting ground-view features into the BEV domain and enforcing semantic alignment with map features. Then we leverage homography relationships to guide feature fusion and restrict the pose outputs to a valid feasible region, which significantly improves training efficiency and localization accuracy compared to prior methods relying on attention-based fusion and direct 3-DoF pose regression. To the best of our knowledge, this is the first work to unify BEV semantic reasoning with homography learning for image-to-map localization. Furthermore, by explicitly modeling homography transformations, the proposed framework naturally supports cross-resolution inputs, enhancing model flexibility. Extensive experiments on the nuScenes dataset demonstrate that our approach significantly outperforms existing state-of-the-art visual localization methods. Code and pretrained models will be publicly released to foster future research.
EAROL: Environmental Augmented Perception-Aware Planning and Robust Odometry via Downward-Mounted Tilted LiDAR
Aug 20, 2025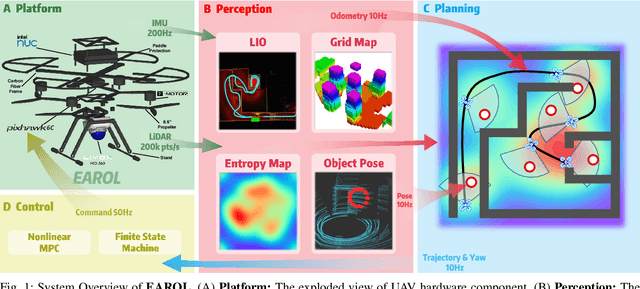
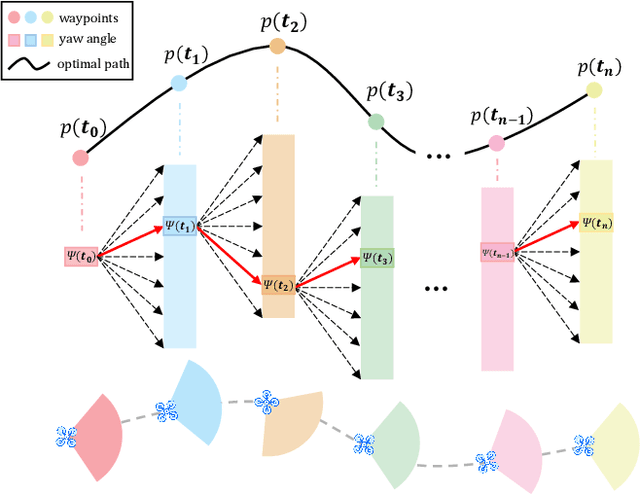

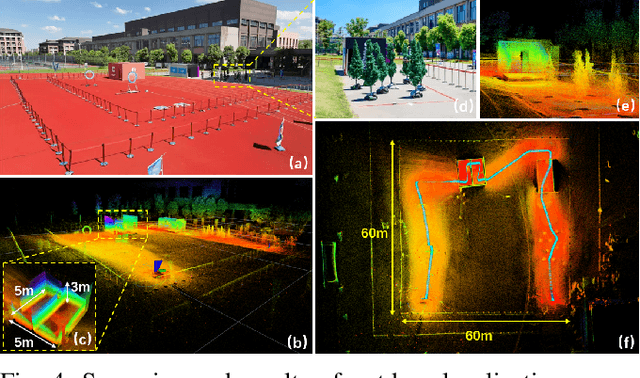
To address the challenges of localization drift and perception-planning coupling in unmanned aerial vehicles (UAVs) operating in open-top scenarios (e.g., collapsed buildings, roofless mazes), this paper proposes EAROL, a novel framework with a downward-mounted tilted LiDAR configuration (20{\deg} inclination), integrating a LiDAR-Inertial Odometry (LIO) system and a hierarchical trajectory-yaw optimization algorithm. The hardware innovation enables constraint enhancement via dense ground point cloud acquisition and forward environmental awareness for dynamic obstacle detection. A tightly-coupled LIO system, empowered by an Iterative Error-State Kalman Filter (IESKF) with dynamic motion compensation, achieves high level 6-DoF localization accuracy in feature-sparse environments. The planner, augmented by environment, balancing environmental exploration, target tracking precision, and energy efficiency. Physical experiments demonstrate 81% tracking error reduction, 22% improvement in perceptual coverage, and near-zero vertical drift across indoor maze and 60-meter-scale outdoor scenarios. This work proposes a hardware-algorithm co-design paradigm, offering a robust solution for UAV autonomy in post-disaster search and rescue missions. We will release our software and hardware as an open-source package for the community. Video: https://youtu.be/7av2ueLSiYw.
Incorporating Flexible Image Conditioning into Text-to-Video Diffusion Models without Training
May 27, 2025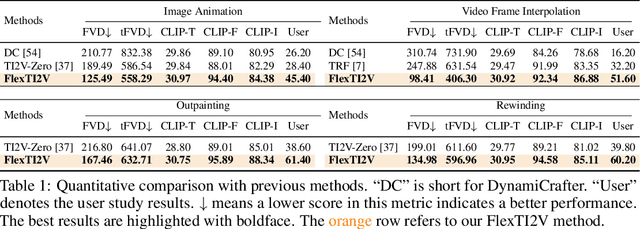
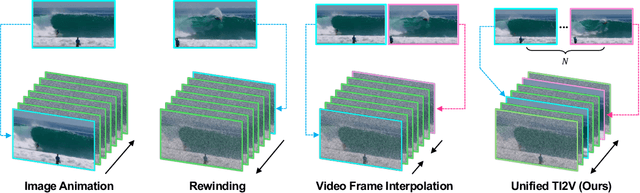
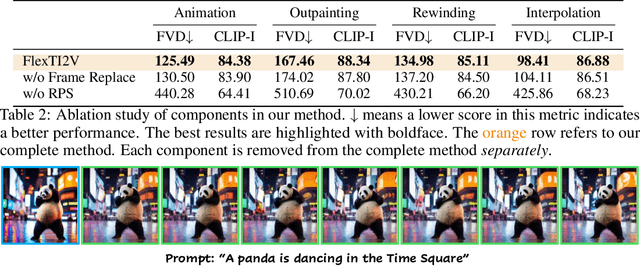
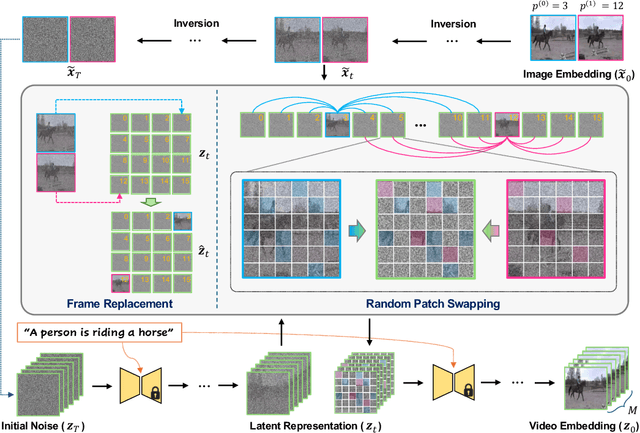
Text-image-to-video (TI2V) generation is a critical problem for controllable video generation using both semantic and visual conditions. Most existing methods typically add visual conditions to text-to-video (T2V) foundation models by finetuning, which is costly in resources and only limited to a few predefined conditioning settings. To tackle this issue, we introduce a unified formulation for TI2V generation with flexible visual conditioning. Furthermore, we propose an innovative training-free approach, dubbed FlexTI2V, that can condition T2V foundation models on an arbitrary amount of images at arbitrary positions. Specifically, we firstly invert the condition images to noisy representation in a latent space. Then, in the denoising process of T2V models, our method uses a novel random patch swapping strategy to incorporate visual features into video representations through local image patches. To balance creativity and fidelity, we use a dynamic control mechanism to adjust the strength of visual conditioning to each video frame. Extensive experiments validate that our method surpasses previous training-free image conditioning methods by a notable margin. We also show more insights of our method by detailed ablation study and analysis.