 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAGE: Spuriousness-Aware Guided Prompt Exploration for Mitigating Multimodal Bias
Nov 17, 2025Large vision-language models, such as CLIP, have shown strong zero-shot classification performance by aligning images and text in a shared embedding space. However, CLIP models often develop multimodal spurious biases, which is the undesirable tendency to rely on spurious features. For example, CLIP may infer object types in images based on frequently co-occurring backgrounds rather than the object's core features. This bias significantly impairs the robustness of pre-trained CLIP models on out-of-distribution data, where such cross-modal associations no longer hold. Existing methods for mitigating multimodal spurious bias typically require fine-tuning on downstream data or prior knowledge of the bias, which undermines the out-of-the-box usability of CLIP. In this paper, we first theoretically analyze the impact of multimodal spurious bias in zero-shot classification. Based on this insight, we propose Spuriousness-Aware Guided Exploration (SAGE), a simple and effective method that mitigates spurious bias through guided prompt selection. SAGE requires no training, fine-tuning, or external annotations. It explores a space of prompt templates and selects the prompts that induce the largest semantic separation between classes, thereby improving worst-group robustness. Extensive experiments on four real-world benchmark datasets and five popular backbone models demonstrate that SAGE consistently improves zero-shot performance and generalization, outperforming previous zero-shot approaches without any external knowledge or model updates.
Rectifying Shortcut Behaviors in Preference-based Reward Learning
Oct 21, 2025In reinforcement learning from human feedback, preference-based reward models play a central role in aligning large language models to human-aligned behavior. However, recent studies show that these models are prone to reward hacking and often fail to generalize well due to over-optimization. They achieve high reward scores by exploiting shortcuts, that is, exploiting spurious features (e.g., response verbosity, agreeable tone, or sycophancy) that correlate with human preference labels in the training data rather than genuinely reflecting the intended objectives. In this paper, instead of probing these issues one at a time, we take a broader view of the reward hacking problem as shortcut behaviors and introduce a principled yet flexible approach to mitigate shortcut behaviors in preference-based reward learning. Inspired by the invariant theory in the kernel perspective, we propose Preference-based Reward Invariance for Shortcut Mitigation (PRISM), which learns group-invariant kernels with feature maps in a closed-form learning objective. Experimental results in several benchmarks show that our method consistently improves the accuracy of the reward model on diverse out-of-distribution tasks and reduces the dependency on shortcuts in downstream policy models, establishing a robust framework for preference-based alignment.
Towards Unveiling Predictive Uncertainty Vulnerabilities in the Context of the Right to Be Forgotten
Aug 10, 2025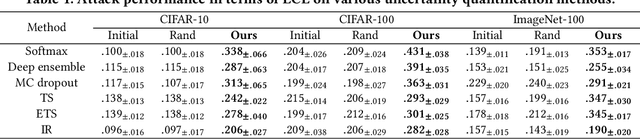
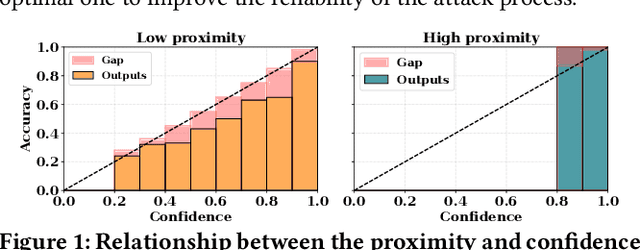
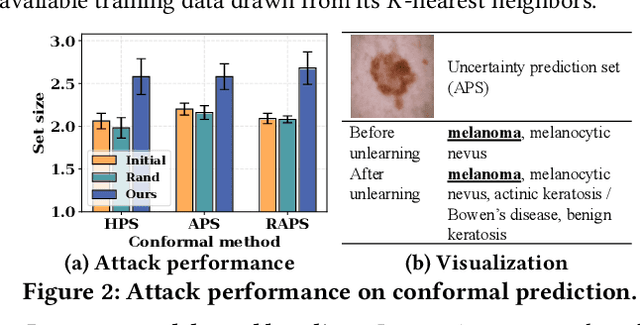
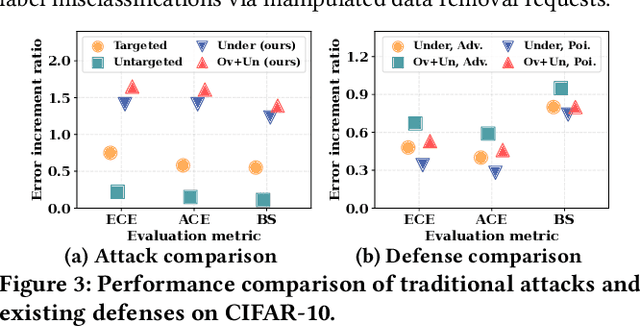
Currently, various uncertainty quantification methods have been proposed to provide certainty and probability estimates for deep learning models' label predictions. Meanwhile, with the growing demand for the right to be forgotten, machine unlearning has been extensively studied as a means to remove the impact of requested sensitive data from a pre-trained model without retraining the model from scratch. However, the vulnerabilities of such generated predictive uncertainties with regard to dedicated malicious unlearning attacks remain unexplored. To bridge this gap, for the first time, we propose a new class of malicious unlearning attacks against predictive uncertainties, where the adversary aims to cause the desired manipulations of specific predictive uncertainty results. We also design novel optimization frameworks for our attacks and conduct extensive experiments, including black-box scenarios. Notably, our extensive experiments show that our attacks are more effective in manipulating predictive uncertainties than traditional attacks that focus on label misclassifications, and existing defenses against conventional attacks are ineffective against our attacks.
NeuronTune: Towards Self-Guided Spurious Bias Mitigation
May 29, 2025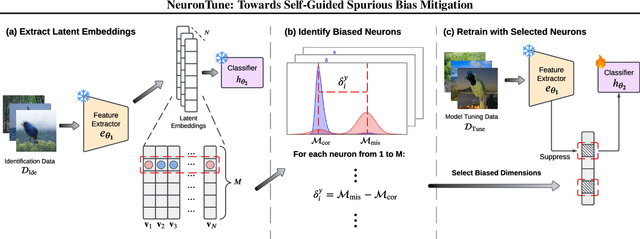
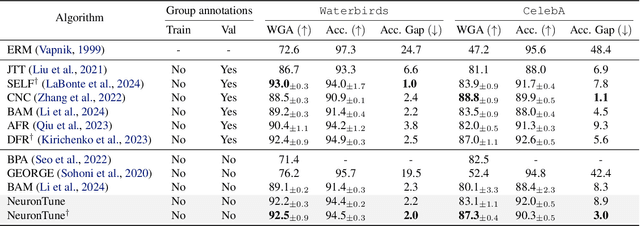
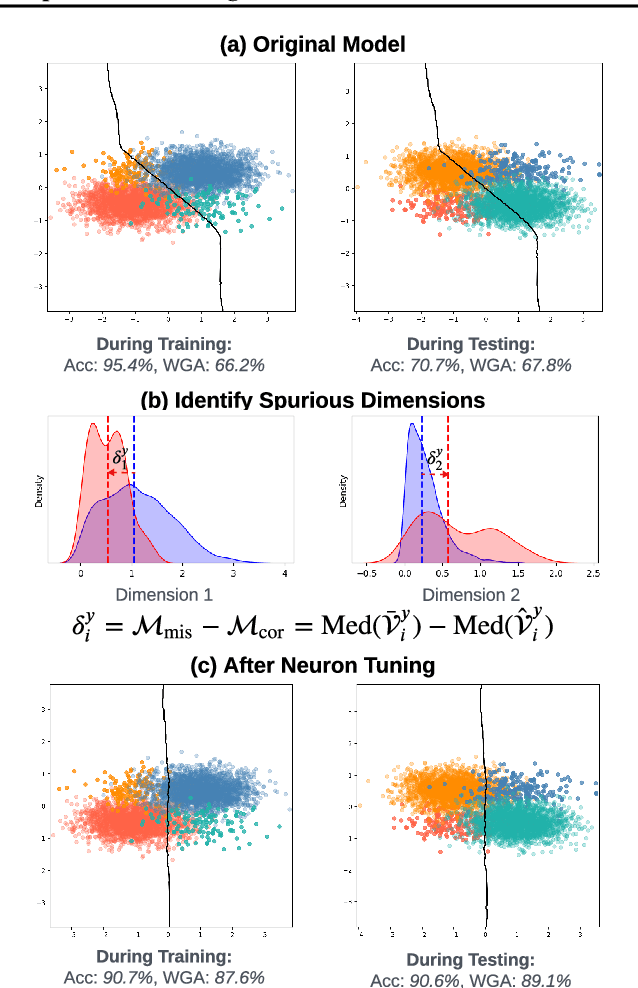
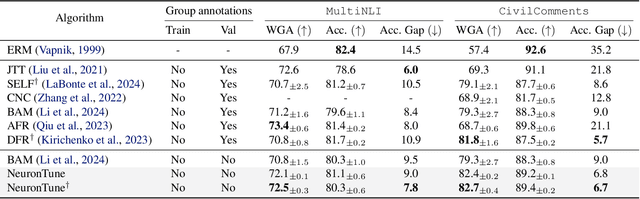
Deep neural networks often develop spurious bias, reliance on correlations between non-essential features and classes for predictions. For example, a model may identify objects based on frequently co-occurring backgrounds rather than intrinsic features, resulting in degraded performance on data lacking these correlations. Existing mitigation approaches typically depend on external annotations of spurious correlations, which may be difficult to obtain and are not relevant to the spurious bias in a model. In this paper, we take a step towards self-guided mitigation of spurious bias by proposing NeuronTune, a post hoc method that directly intervenes in a model's internal decision process. Our method probes in a model's latent embedding space to identify and regulate neurons that lead to spurious prediction behaviors. We theoretically justify our approach and show that it brings the model closer to an unbiased one. Unlike previous methods, NeuronTune operates without requiring spurious correlation annotations, making it a practical and effective tool for improving model robustness. Experiments across different architectures and data modalities demonstrate that our method significantly mitigates spurious bias in a self-guided way.
ShortcutProbe: Probing Prediction Shortcuts for Learning Robust Models
May 20, 2025Deep learning models often achieve high performance by inadvertently learning spurious correlations between targets and non-essential features. For example, an image classifier may identify an object via its background that spuriously correlates with it. This prediction behavior, known as spurious bias, severely degrades model performance on data that lacks the learned spurious correlations. Existing methods on spurious bias mitigation typically require a variety of data groups with spurious correlation annotations called group labels. However, group labels require costly human annotations and often fail to capture subtle spurious biases such as relying on specific pixels for predictions. In this paper, we propose a novel post hoc spurious bias mitigation framework without requiring group labels. Our framework, termed ShortcutProbe, identifies prediction shortcuts that reflect potential non-robustness in predictions in a given model's latent space. The model is then retrained to be invariant to the identified prediction shortcuts for improved robustness. We theoretically analyze the effectiveness of the framework and empirically demonstrate that it is an efficient and practical tool for improving a model's robustness to spurious bias on diverse datasets.
Medical Video Generation for Disease Progression Simulation
Nov 18, 2024Modeling disease progression is crucial for improving the quality and efficacy of clinical diagnosis and prognosis, but it is often hindered by a lack of longitudinal medical image monitoring for individual patients. To address this challenge, we propose the first Medical Video Generation (MVG) framework that enables controlled manipulation of disease-related image and video features, allowing precise, realistic, and personalized simulations of disease progression. Our approach begins by leveraging large language models (LLMs) to recaption prompt for disease trajectory. Next, a controllable multi-round diffusion model simulates the disease progression state for each patient, creating realistic intermediate disease state sequence. Finally, a diffusion-based video transition generation model interpolates disease progression between these states. We validate our framework across three medical imaging domains: chest X-ray, fundus photography, and skin image. Our results demonstrate that MVG significantly outperforms baseline models in generating coherent and clinically plausible disease trajectories. Two user studies by veteran physicians, provide further validation and insights into the clinical utility of the generated sequences. MVG has the potential to assist healthcare providers in modeling disease trajectories, interpolating missing medical image data, and enhancing medical education through realistic, dynamic visualizations of disease progression.
On-Board Vision-Language Models for Personalized Autonomous Vehicle Motion Control: System Design and Real-World Validation
Nov 17, 2024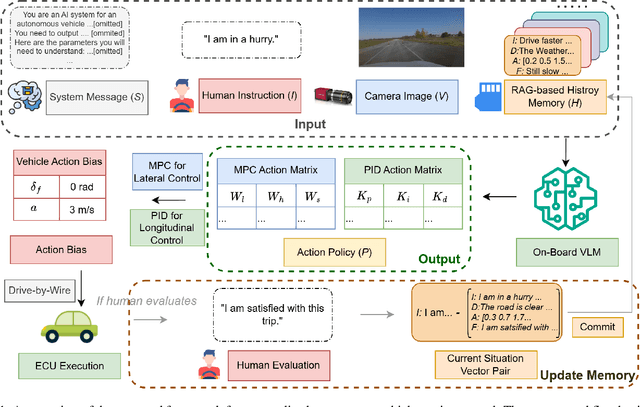
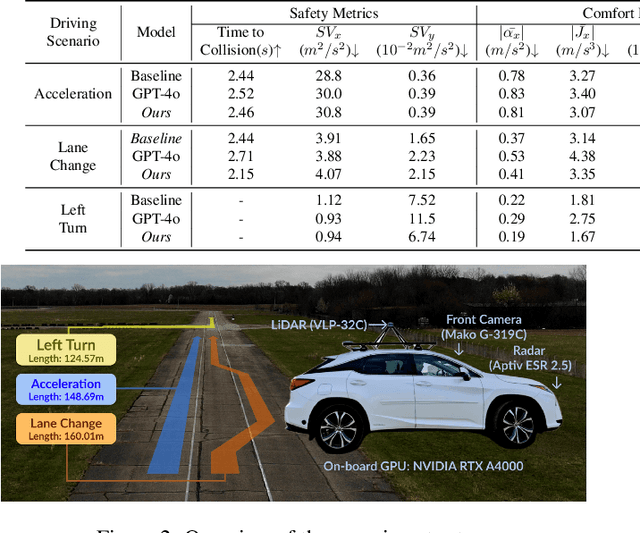

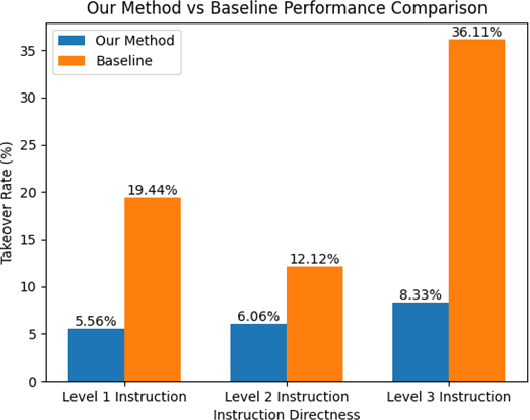
Personalized driving refers to an autonomous vehicle's ability to adapt its driving behavior or control strategies to match individual users' preferences and driving styles while maintaining safety and comfort standards. However, existing works either fail to capture every individual preference precisely or become computationally inefficient as the user base expands. Vision-Language Models (VLMs) offer promising solutions to this front through their natural language understanding and scene reasoning capabilities. In this work, we propose a lightweight yet effective on-board VLM framework that provides low-latency personalized driving performance while maintaining strong reasoning capabilities. Our solution incorporates a Retrieval-Augmented Generation (RAG)-based memory module that enables continuous learning of individual driving preferences through human feedback. Through comprehensive real-world vehicle deployment and experiments, our system has demonstrated the ability to provide safe, comfortable, and personalized driving experiences across various scenarios and significantly reduce takeover rates by up to 76.9%. To the best of our knowledge, this work represents the first end-to-end VLM-based motion control system in real-world autonomous vehicles.
MpoxVLM: A Vision-Language Model for Diagnosing Skin Lesions from Mpox Virus Infection
Nov 16, 2024



In the aftermath of the COVID-19 pandemic and amid accelerating climate change, emerging infectious diseases, particularly those arising from zoonotic spillover, remain a global threat. Mpox (caused by the monkeypox virus) is a notable example of a zoonotic infection that often goes undiagnosed, especially as its rash progresses through stages, complicating detection across diverse populations with different presentations. In August 2024, the WHO Director-General declared the mpox outbreak a public health emergency of international concern for a second time. Despite the deployment of deep learning techniques for detecting diseases from skin lesion images, a robust and publicly accessible foundation model for mpox diagnosis is still lacking due to the unavailability of open-source mpox skin lesion images, multimodal clinical data, and specialized training pipelines. To address this gap, we propose MpoxVLM, a vision-language model (VLM) designed to detect mpox by analyzing both skin lesion images and patient clinical information. MpoxVLM integrates the CLIP visual encoder, an enhanced Vision Transformer (ViT) classifier for skin lesions, and LLaMA-2-7B models, pre-trained and fine-tuned on visual instruction-following question-answer pairs from our newly released mpox skin lesion dataset. Our work achieves 90.38% accuracy for mpox detection, offering a promising pathway to improve early diagnostic accuracy in combating mpox.
Benchmarking Spurious Bias in Few-Shot Image Classifiers
Sep 04, 2024Few-shot image classifiers are designed to recognize and classify new data with minimal supervision and limited data but often show reliance on spurious correlations between classes and spurious attributes, known as spurious bias. Spurious correlations commonly hold in certain samples and few-shot classifiers can suffer from spurious bias induced from them. There is an absence of an automatic benchmarking system to assess the robustness of few-shot classifiers against spurious bias. In this paper, we propose a systematic and rigorous benchmark framework, termed FewSTAB, to fairly demonstrate and quantify varied degrees of robustness of few-shot classifiers to spurious bias. FewSTAB creates few-shot evaluation tasks with biased attributes so that using them for predictions can demonstrate poor performance. To construct these tasks, we propose attribute-based sample selection strategies based on a pre-trained vision-language model, eliminating the need for manual dataset curation. This allows FewSTAB to automatically benchmark spurious bias using any existing test data. FewSTAB offers evaluation results in a new dimension along with a new design guideline for building robust classifiers. Moreover, it can benchmark spurious bias in varied degrees and enable designs for varied degrees of robustness. Its effectiveness is demonstrated through experiments on ten few-shot learning methods across three datasets. We hope our framework can inspire new designs of robust few-shot classifiers. Our code is available at https://github.com/gtzheng/FewSTAB.
MM-SpuBench: Towards Better Understanding of Spurious Biases in Multimodal LLMs
Jun 24, 2024



Spurious bias, a tendency to use spurious correlations between non-essential input attributes and target variables for predictions, has revealed a severe robustness pitfall in deep learning models trained on single modality data. Multimodal Large Language Models (MLLMs), which integrate both vision and language models, have demonstrated strong capability in joint vision-language understanding. However, whether spurious biases are prevalent in MLLMs remains under-explored. We mitigate this gap by analyzing the spurious biases in a multimodal setting, uncovering the specific test data patterns that can manifest this problem when biases in the vision model cascade into the alignment between visual and text tokens in MLLMs. To better understand this problem, we introduce MM-SpuBench, a comprehensive visual question-answering (VQA) benchmark designed to evaluate MLLMs' reliance on nine distinct categories of spurious correlations from five open-source image datasets. The VQA dataset is built from human-understandable concept information (attributes). Leveraging this benchmark, we conduct a thorough evaluation of current state-of-the-art MLLMs. Our findings illuminate the persistence of the reliance on spurious correlations from these models and underscore the urge for new methodologies to mitigate spurious biases. To support the MLLM robustness research, we release our VQA benchmark at https://huggingface.co/datasets/mmbench/MM-SpuBench.