 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCautious Weight Decay
Oct 14, 2025We introduce Cautious Weight Decay (CWD), a one-line, optimizer-agnostic modification that applies weight decay only to parameter coordinates whose signs align with the optimizer update. Unlike standard decoupled decay, which implicitly optimizes a regularized or constrained objective, CWD preserves the original loss and admits a bilevel interpretation: it induces sliding-mode behavior upon reaching the stationary manifold, allowing it to search for locally Pareto-optimal stationary points of the unmodified objective. In practice, CWD is a drop-in change for optimizers such as AdamW, Lion, and Muon, requiring no new hyperparameters or additional tuning. For language model pre-training and ImageNet classification, CWD consistently improves final loss and accuracy at million- to billion-parameter scales.
Composition of Experts: A Modular Compound AI System Leveraging Large Language Models
Dec 02, 2024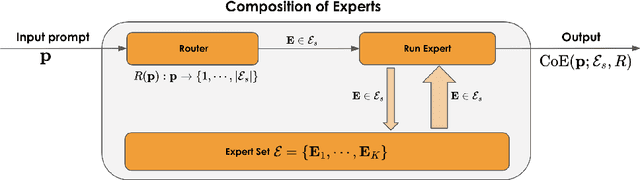
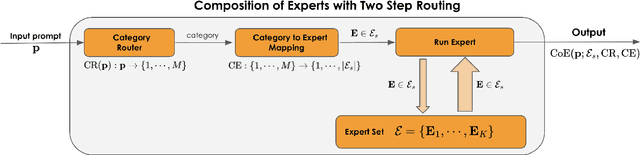
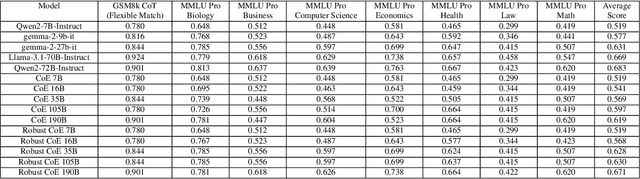
Large Language Models (LLMs) have achieved remarkable advancements, but their monolithic nature presents challenges in terms of scalability, cost, and customization. This paper introduces the Composition of Experts (CoE), a modular compound AI system leveraging multiple expert LLMs. CoE leverages a router to dynamically select the most appropriate expert for a given input, enabling efficient utilization of resources and improved performance. We formulate the general problem of training a CoE and discuss inherent complexities associated with it. We propose a two-step routing approach to address these complexities that first uses a router to classify the input into distinct categories followed by a category-to-expert mapping to obtain desired experts. CoE offers a flexible and cost-effective solution to build compound AI systems. Our empirical evaluation demonstrates the effectiveness of CoE in achieving superior performance with reduced computational overhead. Given that CoE comprises of many expert LLMs it has unique system requirements for cost-effective serving. We present an efficient implementation of CoE leveraging SambaNova SN40L RDUs unique three-tiered memory architecture. CoEs obtained using open weight LLMs Qwen/Qwen2-7B-Instruct, google/gemma-2-9b-it, google/gemma-2-27b-it, meta-llama/Llama-3.1-70B-Instruct and Qwen/Qwen2-72B-Instruct achieve a score of $59.4$ with merely $31$ billion average active parameters on Arena-Hard and a score of $9.06$ with $54$ billion average active parameters on MT-Bench.
Cautious Optimizers: Improving Training with One Line of Code
Nov 25, 2024

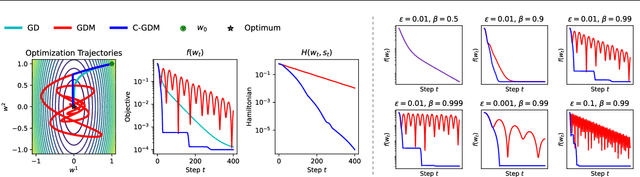

AdamW has been the default optimizer for transformer pretraining. For many years, our community searches for faster and more stable optimizers with only constraint positive outcomes. In this work, we propose a \textbf{single-line modification in Pytorch} to any momentum-based optimizer, which we rename Cautious Optimizer, e.g. C-AdamW and C-Lion. Our theoretical result shows that this modification preserves Adam's Hamiltonian function and it does not break the convergence guarantee under the Lyapunov analysis. In addition, a whole new family of optimizers is revealed by our theoretical insight. Among them, we pick the simplest one for empirical experiments, showing speed-up on Llama and MAE pretraining up to $1.47\times$. Code is available at https://github.com/kyleliang919/C-Optim
Medical Video Generation for Disease Progression Simulation
Nov 18, 2024Modeling disease progression is crucial for improving the quality and efficacy of clinical diagnosis and prognosis, but it is often hindered by a lack of longitudinal medical image monitoring for individual patients. To address this challenge, we propose the first Medical Video Generation (MVG) framework that enables controlled manipulation of disease-related image and video features, allowing precise, realistic, and personalized simulations of disease progression. Our approach begins by leveraging large language models (LLMs) to recaption prompt for disease trajectory. Next, a controllable multi-round diffusion model simulates the disease progression state for each patient, creating realistic intermediate disease state sequence. Finally, a diffusion-based video transition generation model interpolates disease progression between these states. We validate our framework across three medical imaging domains: chest X-ray, fundus photography, and skin image. Our results demonstrate that MVG significantly outperforms baseline models in generating coherent and clinically plausible disease trajectories. Two user studies by veteran physicians, provide further validation and insights into the clinical utility of the generated sequences. MVG has the potential to assist healthcare providers in modeling disease trajectories, interpolating missing medical image data, and enhancing medical education through realistic, dynamic visualizations of disease progression.
Memory-Efficient LLM Training with Online Subspace Descent
Aug 23, 2024Recently, a wide range of memory-efficient LLM training algorithms have gained substantial popularity. These methods leverage the low-rank structure of gradients to project optimizer states into a subspace using projection matrix found by singular value decomposition (SVD). However, convergence of these algorithms is highly dependent on the update rules of their projection matrix. In this work, we provide the \emph{first} convergence guarantee for arbitrary update rules of projection matrix. This guarantee is generally applicable to optimizers that can be analyzed with Hamiltonian Descent, including most common ones, such as LION, Adam. Inspired by our theoretical understanding, we propose Online Subspace Descent, a new family of subspace descent optimizer without SVD. Instead of updating the projection matrix with eigenvectors, Online Subspace Descent updates the projection matrix with online PCA. Online Subspace Descent is flexible and introduces only minimum overhead to training. We show that for the task of pretraining LLaMA models ranging from 60M to 7B parameters on the C4 dataset, Online Subspace Descent achieves lower perplexity and better downstream tasks performance than state-of-the-art low-rank training methods across different settings and narrows the gap with full-rank baselines.
SambaNova SN40L: Scaling the AI Memory Wall with Dataflow and Composition of Experts
May 13, 2024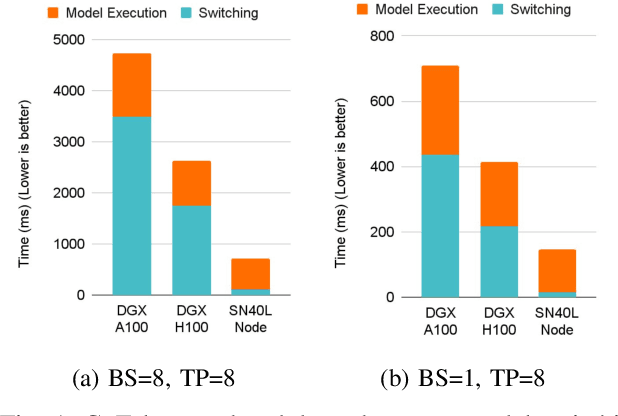
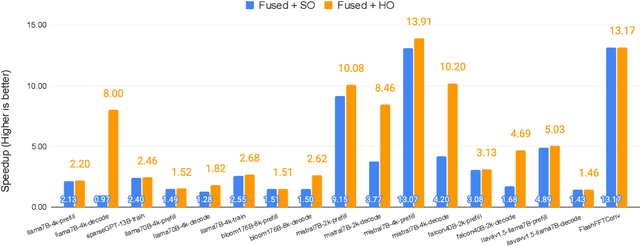
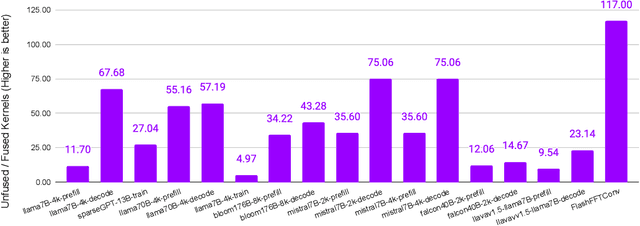
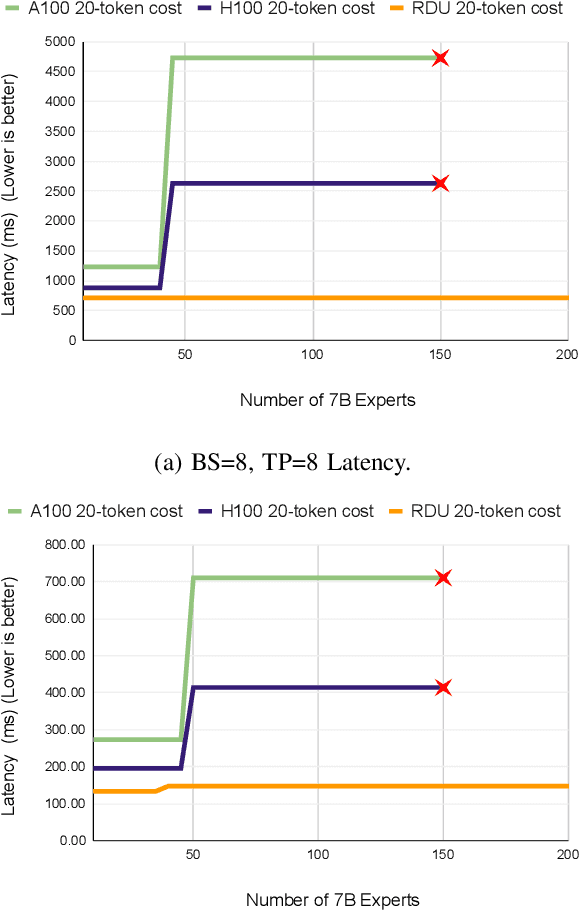
Monolithic large language models (LLMs) like GPT-4 have paved the way for modern generative AI applications. Training, serving, and maintaining monolithic LLMs at scale, however, remains prohibitively expensive and challenging. The disproportionate increase in compute-to-memory ratio of modern AI accelerators have created a memory wall, necessitating new methods to deploy AI. Composition of Experts (CoE) is an alternative modular approach that lowers the cost and complexity of training and serving. However, this approach presents two key challenges when using conventional hardware: (1) without fused operations, smaller models have lower operational intensity, which makes high utilization more challenging to achieve; and (2) hosting a large number of models can be either prohibitively expensive or slow when dynamically switching between them. In this paper, we describe how combining CoE, streaming dataflow, and a three-tier memory system scales the AI memory wall. We describe Samba-CoE, a CoE system with 150 experts and a trillion total parameters. We deploy Samba-CoE on the SambaNova SN40L Reconfigurable Dataflow Unit (RDU) - a commercial dataflow accelerator architecture that has been co-designed for enterprise inference and training applications. The chip introduces a new three-tier memory system with on-chip distributed SRAM, on-package HBM, and off-package DDR DRAM. A dedicated inter-RDU network enables scaling up and out over multiple sockets. We demonstrate speedups ranging from 2x to 13x on various benchmarks running on eight RDU sockets compared with an unfused baseline. We show that for CoE inference deployments, the 8-socket RDU Node reduces machine footprint by up to 19x, speeds up model switching time by 15x to 31x, and achieves an overall speedup of 3.7x over a DGX H100 and 6.6x over a DGX A100.
Communication Efficient Distributed Training with Distributed Lion
Mar 30, 2024



The Lion optimizer has been a promising competitor with the AdamW for training large AI models, with advantages on memory, computation, and sample efficiency. In this paper, we introduce Distributed Lion, an innovative adaptation of Lion for distributed training environments. Leveraging the sign operator in Lion, our Distributed Lion only requires communicating binary or lower-precision vectors between workers to the center server, significantly reducing the communication cost. Our theoretical analysis confirms Distributed Lion's convergence properties. Empirical results demonstrate its robustness across a range of tasks, worker counts, and batch sizes, on both vision and language problems. Notably, Distributed Lion attains comparable performance to standard Lion or AdamW optimizers applied on aggregated gradients, but with significantly reduced communication bandwidth. This feature is particularly advantageous for training large models. In addition, we also demonstrate that Distributed Lion presents a more favorable performance-bandwidth balance compared to existing efficient distributed methods such as deep gradient compression and ternary gradients.
A Survey on Multimodal Large Language Models for Autonomous Driving
Nov 21, 2023


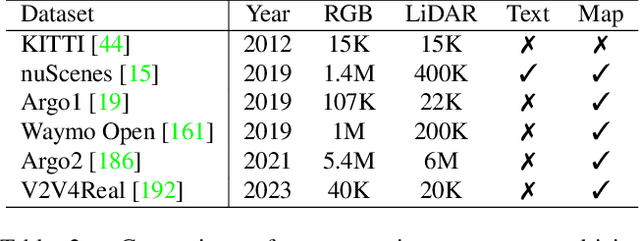
With the emergence of Large Language Models (LLMs) and Vision Foundation Models (VFMs), multimodal AI systems benefiting from large models have the potential to equally perceive the real world, make decisions, and control tools as humans. In recent months, LLMs have shown widespread attention in autonomous driving and map systems. Despite its immense potential, there is still a lack of a comprehensive understanding of key challenges, opportunities, and future endeavors to apply in LLM driving systems. In this paper, we present a systematic investigation in this field. We first introduce the background of Multimodal Large Language Models (MLLMs), the multimodal models development using LLMs, and the history of autonomous driving. Then, we overview existing MLLM tools for driving, transportation, and map systems together with existing datasets and benchmarks. Moreover, we summarized the works in The 1st WACV Workshop on Large Language and Vision Models for Autonomous Driving (LLVM-AD), which is the first workshop of its kind regarding LLMs in autonomous driving. To further promote the development of this field, we also discuss several important problems regarding using MLLMs in autonomous driving systems that need to be solved by both academia and industry.
Lion Secretly Solves Constrained Optimization: As Lyapunov Predicts
Oct 12, 2023



Lion (Evolved Sign Momentum), a new optimizer discovered through program search, has shown promising results in training large AI models. It performs comparably or favorably to AdamW but with greater memory efficiency. As we can expect from the results of a random search program, Lion incorporates elements from several existing algorithms, including signed momentum, decoupled weight decay, Polak, and Nesterov momentum, but does not fit into any existing category of theoretically grounded optimizers. Thus, even though Lion appears to perform well as a general-purpose optimizer for a wide range of tasks, its theoretical basis remains uncertain. This lack of theoretical clarity limits opportunities to further enhance and expand Lion's efficacy. This work aims to demystify Lion. Based on both continuous-time and discrete-time analysis, we demonstrate that Lion is a theoretically novel and principled approach for minimizing a general loss function $f(x)$ while enforcing a bound constraint $\|x\|_\infty \leq 1/\lambda$. Lion achieves this through the incorporation of decoupled weight decay, where $\lambda$ represents the weight decay coefficient. Our analysis is made possible by the development of a new Lyapunov function for the Lion updates. It applies to a broader family of Lion-$\kappa$ algorithms, where the $\text{sign}(\cdot)$ operator in Lion is replaced by the subgradient of a convex function $\kappa$, leading to the solution of a general composite optimization problem of $\min_x f(x) + \kappa^*(x)$. Our findings provide valuable insights into the dynamics of Lion and pave the way for further improvements and extensions of Lion-related algorithms.
PIE: Simulating Disease Progression via Progressive Image Editing
Sep 21, 2023Disease progression simulation is a crucial area of research that has significant implications for clinical diagnosis, prognosis, and treatment. One major challenge in this field is the lack of continuous medical imaging monitoring of individual patients over time. To address this issue, we develop a novel framework termed Progressive Image Editing (PIE) that enables controlled manipulation of disease-related image features, facilitating precise and realistic disease progression simulation. Specifically, we leverage recent advancements in text-to-image generative models to simulate disease progression accurately and personalize it for each patient. We theoretically analyze the iterative refining process in our framework as a gradient descent with an exponentially decayed learning rate. To validate our framework, we conduct experiments in three medical imaging domains. Our results demonstrate the superiority of PIE over existing methods such as Stable Diffusion Walk and Style-Based Manifold Extrapolation based on CLIP score (Realism) and Disease Classification Confidence (Alignment). Our user study collected feedback from 35 veteran physicians to assess the generated progressions. Remarkably, 76.2% of the feedback agrees with the fidelity of the generated progressions. To our best knowledge, PIE is the first of its kind to generate disease progression images meeting real-world standards. It is a promising tool for medical research and clinical practice, potentially allowing healthcare providers to model disease trajectories over time, predict future treatment responses, and improve patient outcomes.