 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Robust Reasoning through Guided Adversarial Self-Play
Jan 30, 2026Reinforcement learning from verifiable rewards (RLVR) produces strong reasoning models, yet they can fail catastrophically when the conditioning context is fallible (e.g., corrupted chain-of-thought, misleading partial solutions, or mild input perturbations), since standard RLVR optimizes final-answer correctness only under clean conditioning. We introduce GASP (Guided Adversarial Self-Play), a robustification method that explicitly trains detect-and-repair capabilities using only outcome verification. Without human labels or external teachers, GASP forms an adversarial self-play game within a single model: a polluter learns to induce failure via locally coherent corruptions, while an agent learns to diagnose and recover under the same corrupted conditioning. To address the scarcity of successful recoveries early in training, we propose in-distribution repair guidance, an imitation term on self-generated repairs that increases recovery probability while preserving previously acquired capabilities. Across four open-weight models (1.5B--8B), GASP transforms strong-but-brittle reasoners into robust ones that withstand misleading and perturbed context while often improving clean accuracy. Further analysis shows that adversarial corruptions induce an effective curriculum, and in-distribution guidance enables rapid recovery learning with minimal representational drift.
Wow, wo, val! A Comprehensive Embodied World Model Evaluation Turing Test
Jan 07, 2026As world models gain momentum in Embodied AI, an increasing number of works explore using video foundation models as predictive world models for downstream embodied tasks like 3D prediction or interactive generation. However, before exploring these downstream tasks, video foundation models still have two critical questions unanswered: (1) whether their generative generalization is sufficient to maintain perceptual fidelity in the eyes of human observers, and (2) whether they are robust enough to serve as a universal prior for real-world embodied agents. To provide a standardized framework for answering these questions, we introduce the Embodied Turing Test benchmark: WoW-World-Eval (Wow,wo,val). Building upon 609 robot manipulation data, Wow-wo-val examines five core abilities, including perception, planning, prediction, generalization, and execution. We propose a comprehensive evaluation protocol with 22 metrics to assess the models' generation ability, which achieves a high Pearson Correlation between the overall score and human preference (>0.93) and establishes a reliable foundation for the Human Turing Test. On Wow-wo-val, models achieve only 17.27 on long-horizon planning and at best 68.02 on physical consistency, indicating limited spatiotemporal consistency and physical reasoning. For the Inverse Dynamic Model Turing Test, we first use an IDM to evaluate the video foundation models' execution accuracy in the real world. However, most models collapse to $\approx$ 0% success, while WoW maintains a 40.74% success rate. These findings point to a noticeable gap between the generated videos and the real world, highlighting the urgency and necessity of benchmarking World Model in Embodied AI.
Cautious Weight Decay
Oct 14, 2025We introduce Cautious Weight Decay (CWD), a one-line, optimizer-agnostic modification that applies weight decay only to parameter coordinates whose signs align with the optimizer update. Unlike standard decoupled decay, which implicitly optimizes a regularized or constrained objective, CWD preserves the original loss and admits a bilevel interpretation: it induces sliding-mode behavior upon reaching the stationary manifold, allowing it to search for locally Pareto-optimal stationary points of the unmodified objective. In practice, CWD is a drop-in change for optimizers such as AdamW, Lion, and Muon, requiring no new hyperparameters or additional tuning. For language model pre-training and ImageNet classification, CWD consistently improves final loss and accuracy at million- to billion-parameter scales.
WoW: Towards a World omniscient World model Through Embodied Interaction
Sep 26, 2025Humans develop an understanding of intuitive physics through active interaction with the world. This approach is in stark contrast to current video models, such as Sora, which rely on passive observation and therefore struggle with grasping physical causality. This observation leads to our central hypothesis: authentic physical intuition of the world model must be grounded in extensive, causally rich interactions with the real world. To test this hypothesis, we present WoW, a 14-billion-parameter generative world model trained on 2 million robot interaction trajectories. Our findings reveal that the model's understanding of physics is a probabilistic distribution of plausible outcomes, leading to stochastic instabilities and physical hallucinations. Furthermore, we demonstrate that this emergent capability can be actively constrained toward physical realism by SOPHIA, where vision-language model agents evaluate the DiT-generated output and guide its refinement by iteratively evolving the language instructions. In addition, a co-trained Inverse Dynamics Model translates these refined plans into executable robotic actions, thus closing the imagination-to-action loop. We establish WoWBench, a new benchmark focused on physical consistency and causal reasoning in video, where WoW achieves state-of-the-art performance in both human and autonomous evaluation, demonstrating strong ability in physical causality, collision dynamics, and object permanence. Our work provides systematic evidence that large-scale, real-world interaction is a cornerstone for developing physical intuition in AI. Models, data, and benchmarks will be open-sourced.
Muon Optimizes Under Spectral Norm Constraints
Jun 18, 2025The pursuit of faster optimization algorithms remains an active and important research direction in deep learning. Recently, the Muon optimizer [JJB+24] has demonstrated promising empirical performance, but its theoretical foundation remains less understood. In this paper, we bridge this gap and provide a theoretical analysis of Muon by placing it within the Lion-$\mathcal{K}$ family of optimizers [CLLL24]. Specifically, we show that Muon corresponds to Lion-$\mathcal{K}$ when equipped with the nuclear norm, and we leverage the theoretical results of Lion-$\mathcal{K}$ to establish that Muon (with decoupled weight decay) implicitly solves an optimization problem that enforces a constraint on the spectral norm of weight matrices. This perspective not only demystifies the implicit regularization effects of Muon but also leads to natural generalizations through varying the choice of convex map $\mathcal{K}$, allowing for the exploration of a broader class of implicitly regularized and constrained optimization algorithms.
Improving Adaptive Moment Optimization via Preconditioner Diagonalization
Feb 11, 2025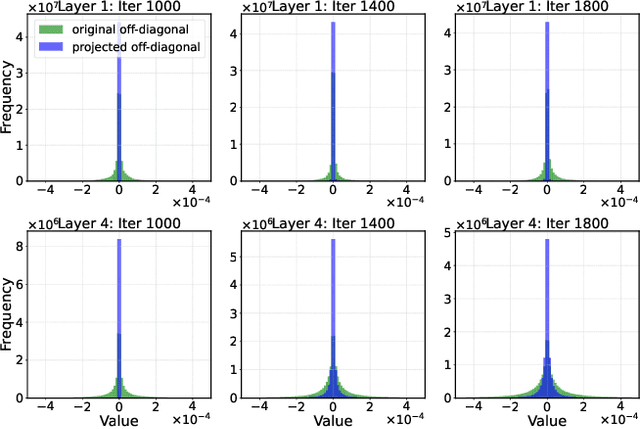
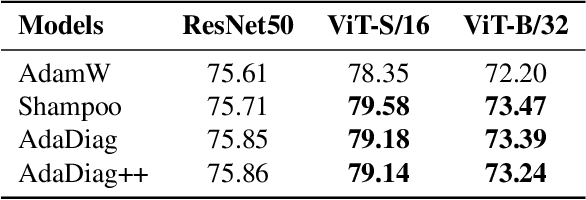
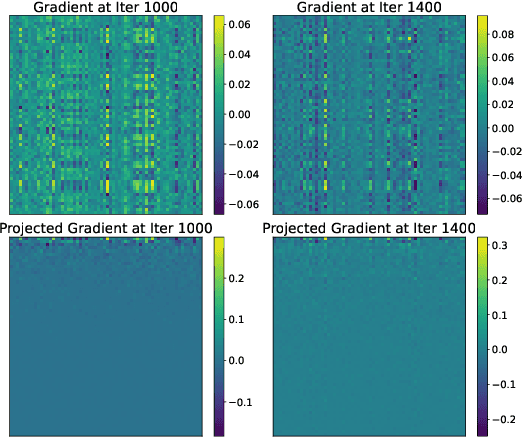
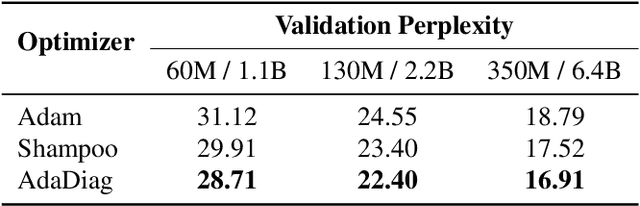
Modern adaptive optimization methods, such as Adam and its variants, have emerged as the most widely used tools in deep learning over recent years. These algorithms offer automatic mechanisms for dynamically adjusting the update step based on estimates of gradient statistics. Compared to traditional algorithms like Stochastic Gradient Descent, these adaptive methods are typically more robust to model scale and hyperparameter tuning. However, the gradient statistics employed by these methods often do not leverage sufficient gradient covariance information, leading to suboptimal updates in certain directions of the parameter space and potentially slower convergence. In this work, we keep track of such covariance statistics in the form of a structured preconditioner matrix. Unlike other works, our approach does not apply direct approximations to estimate this matrix. We instead implement an invertible transformation that maps the preconditioner matrix into a new space where it becomes approximately diagonal. This enables a diagonal approximation of the preconditioner matrix in the transformed space, offering several computational advantages. Empirical results show that our approach can substantially enhance the convergence speed of modern adaptive optimizers. Notably, for large language models like LLaMA, we can achieve a speedup of 2x compared to the baseline Adam. Additionally, our method can be integrated with memory-efficient optimizers like Adafactor to manage computational overhead.
Cautious Optimizers: Improving Training with One Line of Code
Nov 25, 2024

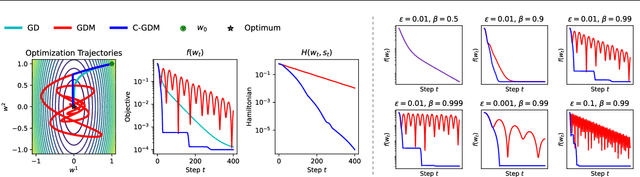

AdamW has been the default optimizer for transformer pretraining. For many years, our community searches for faster and more stable optimizers with only constraint positive outcomes. In this work, we propose a \textbf{single-line modification in Pytorch} to any momentum-based optimizer, which we rename Cautious Optimizer, e.g. C-AdamW and C-Lion. Our theoretical result shows that this modification preserves Adam's Hamiltonian function and it does not break the convergence guarantee under the Lyapunov analysis. In addition, a whole new family of optimizers is revealed by our theoretical insight. Among them, we pick the simplest one for empirical experiments, showing speed-up on Llama and MAE pretraining up to $1.47\times$. Code is available at https://github.com/kyleliang919/C-Optim
Memory-Efficient LLM Training with Online Subspace Descent
Aug 23, 2024Recently, a wide range of memory-efficient LLM training algorithms have gained substantial popularity. These methods leverage the low-rank structure of gradients to project optimizer states into a subspace using projection matrix found by singular value decomposition (SVD). However, convergence of these algorithms is highly dependent on the update rules of their projection matrix. In this work, we provide the \emph{first} convergence guarantee for arbitrary update rules of projection matrix. This guarantee is generally applicable to optimizers that can be analyzed with Hamiltonian Descent, including most common ones, such as LION, Adam. Inspired by our theoretical understanding, we propose Online Subspace Descent, a new family of subspace descent optimizer without SVD. Instead of updating the projection matrix with eigenvectors, Online Subspace Descent updates the projection matrix with online PCA. Online Subspace Descent is flexible and introduces only minimum overhead to training. We show that for the task of pretraining LLaMA models ranging from 60M to 7B parameters on the C4 dataset, Online Subspace Descent achieves lower perplexity and better downstream tasks performance than state-of-the-art low-rank training methods across different settings and narrows the gap with full-rank baselines.
H-Fac: Memory-Efficient Optimization with Factorized Hamiltonian Descent
Jun 17, 2024



In this study, we introduce a novel adaptive optimizer, H-Fac, which incorporates a factorized approach to momentum and scaling parameters. Our algorithm demonstrates competitive performances on both ResNets and Vision Transformers, while achieving sublinear memory costs through the use of rank-1 parameterizations for moment estimators. We develop our algorithms based on principles derived from Hamiltonian dynamics, providing robust theoretical underpinnings. These optimization algorithms are designed to be both straightforward and adaptable, facilitating easy implementation in diverse settings.
Communication Efficient Distributed Training with Distributed Lion
Mar 30, 2024



The Lion optimizer has been a promising competitor with the AdamW for training large AI models, with advantages on memory, computation, and sample efficiency. In this paper, we introduce Distributed Lion, an innovative adaptation of Lion for distributed training environments. Leveraging the sign operator in Lion, our Distributed Lion only requires communicating binary or lower-precision vectors between workers to the center server, significantly reducing the communication cost. Our theoretical analysis confirms Distributed Lion's convergence properties. Empirical results demonstrate its robustness across a range of tasks, worker counts, and batch sizes, on both vision and language problems. Notably, Distributed Lion attains comparable performance to standard Lion or AdamW optimizers applied on aggregated gradients, but with significantly reduced communication bandwidth. This feature is particularly advantageous for training large models. In addition, we also demonstrate that Distributed Lion presents a more favorable performance-bandwidth balance compared to existing efficient distributed methods such as deep gradient compression and ternary gradients.