 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication Efficient Distributed Training with Distributed Lion
Mar 30, 2024



The Lion optimizer has been a promising competitor with the AdamW for training large AI models, with advantages on memory, computation, and sample efficiency. In this paper, we introduce Distributed Lion, an innovative adaptation of Lion for distributed training environments. Leveraging the sign operator in Lion, our Distributed Lion only requires communicating binary or lower-precision vectors between workers to the center server, significantly reducing the communication cost. Our theoretical analysis confirms Distributed Lion's convergence properties. Empirical results demonstrate its robustness across a range of tasks, worker counts, and batch sizes, on both vision and language problems. Notably, Distributed Lion attains comparable performance to standard Lion or AdamW optimizers applied on aggregated gradients, but with significantly reduced communication bandwidth. This feature is particularly advantageous for training large models. In addition, we also demonstrate that Distributed Lion presents a more favorable performance-bandwidth balance compared to existing efficient distributed methods such as deep gradient compression and ternary gradients.
SCNet: Sparse Compression Network for Music Source Separation
Jan 24, 2024



Deep learning-based methods have made significant achievements in music source separation. However, obtaining good results while maintaining a low model complexity remains challenging in super wide-band music source separation. Previous works either overlook the differences in subbands or inadequately address the problem of information loss when generating subband features. In this paper, we propose SCNet, a novel frequency-domain network to explicitly split the spectrogram of the mixture into several subbands and introduce a sparsity-based encoder to model different frequency bands. We use a higher compression ratio on subbands with less information to improve the information density and focus on modeling subbands with more information. In this way, the separation performance can be significantly improved using lower computational consumption. Experiment results show that the proposed model achieves a signal to distortion ratio (SDR) of 9.0 dB on the MUSDB18-HQ dataset without using extra data, which outperforms state-of-the-art methods. Specifically, SCNet's CPU inference time is only 48% of HT Demucs, one of the previous state-of-the-art models.
SememeASR: Boosting Performance of End-to-End Speech Recognition against Domain and Long-Tailed Data Shift with Sememe Semantic Knowledge
Sep 04, 2023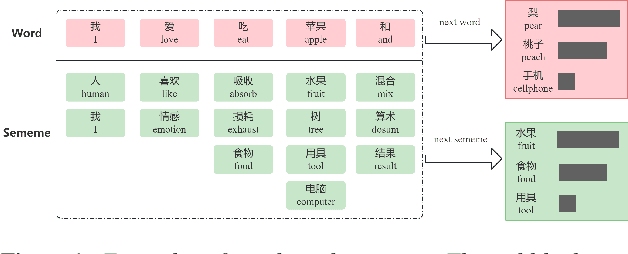



Recently, excellent progress has been made in speech recognition. However, pure data-driven approaches have struggled to solve the problem in domain-mismatch and long-tailed data. Considering that knowledge-driven approaches can help data-driven approaches alleviate their flaws, we introduce sememe-based semantic knowledge information to speech recognition (SememeASR). Sememe, according to the linguistic definition, is the minimum semantic unit in a language and is able to represent the implicit semantic information behind each word very well. Our experiments show that the introduction of sememe information can improve the effectiveness of speech recognition. In addition, our further experiments show that sememe knowledge can improve the model's recognition of long-tailed data and enhance the model's domain generalization ability.
Text-Only Domain Adaptation for End-to-End Speech Recognition through Down-Sampling Acoustic Representation
Sep 04, 2023



Mapping two modalities, speech and text, into a shared representation space, is a research topic of using text-only data to improve end-to-end automatic speech recognition (ASR) performance in new domains. However, the length of speech representation and text representation is inconsistent. Although the previous method up-samples the text representation to align with acoustic modality, it may not match the expected actual duration. In this paper, we proposed novel representations match strategy through down-sampling acoustic representation to align with text modality. By introducing a continuous integrate-and-fire (CIF) module generating acoustic representations consistent with token length, our ASR model can learn unified representations from both modalities better, allowing for domain adaptation using text-only data of the target domain. Experiment results of new domain data demonstrate the effectiveness of the proposed method.