 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep-Audio 2 Technical Report
Jul 24, 2025



This paper presents Step-Audio 2, an end-to-end multi-modal large language model designed for industry-strength audio understanding and speech conversation. By integrating a latent audio encoder and reasoning-centric reinforcement learning (RL), Step-Audio 2 achieves promising performance in automatic speech recognition (ASR) and audio understanding. To facilitate genuine end-to-end speech conversation, Step-Audio 2 incorporates the generation of discrete audio tokens into language modeling, significantly enhancing its responsiveness to paralinguistic information such as speaking styles and emotions. To effectively leverage the rich textual and acoustic knowledge in real-world data, Step-Audio 2 integrates retrieval-augmented generation (RAG) and is able to call external tools such as web search to mitigate hallucination and audio search to switch timbres. Trained on millions of hours of speech and audio data, Step-Audio 2 delivers intelligence and expressiveness across diverse conversational scenarios. Evaluation results demonstrate that Step-Audio 2 achieves state-of-the-art performance on various audio understanding and conversational benchmarks compared to other open-source and commercial solutions. Please visit https://github.com/stepfun-ai/Step-Audio2 for more information.
Text-Only Domain Adaptation for End-to-End Speech Recognition through Down-Sampling Acoustic Representation
Sep 04, 2023



Mapping two modalities, speech and text, into a shared representation space, is a research topic of using text-only data to improve end-to-end automatic speech recognition (ASR) performance in new domains. However, the length of speech representation and text representation is inconsistent. Although the previous method up-samples the text representation to align with acoustic modality, it may not match the expected actual duration. In this paper, we proposed novel representations match strategy through down-sampling acoustic representation to align with text modality. By introducing a continuous integrate-and-fire (CIF) module generating acoustic representations consistent with token length, our ASR model can learn unified representations from both modalities better, allowing for domain adaptation using text-only data of the target domain. Experiment results of new domain data demonstrate the effectiveness of the proposed method.
3M: Multi-loss, Multi-path and Multi-level Neural Networks for speech recognition
Apr 14, 2022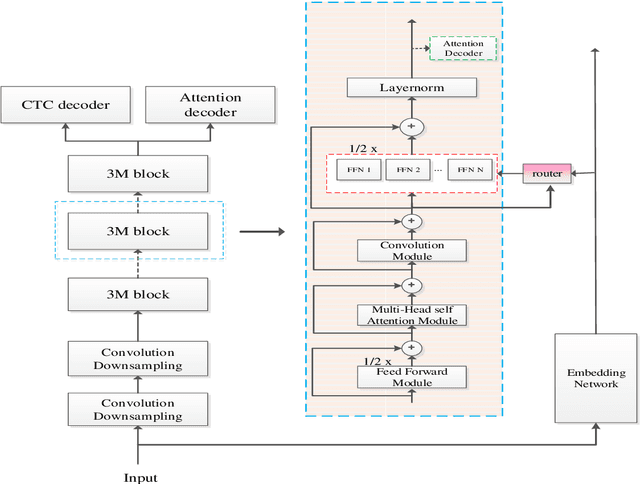
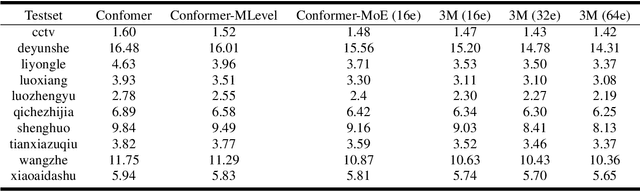
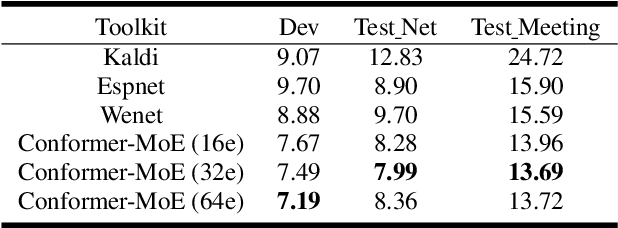
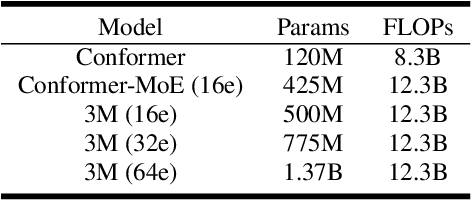
Recently, Conformer based CTC/AED model has become a mainstream architecture for ASR. In this paper, based on our prior work, we identify and integrate several approaches to achieve further improvements for ASR tasks, which we denote as multi-loss, multi-path and multi-level, summarized as "3M" model. Specifically, multi-loss refers to the joint CTC/AED loss and multi-path denotes the Mixture-of-Experts(MoE) architecture which can effectively increase the model capacity without remarkably increasing computation cost. Multi-level means that we introduce auxiliary loss at multiple level of a deep model to help training. We evaluate our proposed method on the public WenetSpeech dataset and experimental results show that the proposed method provides 12.2%-17.6% relative CER improvement over the baseline model trained by Wenet toolkit. On our large scale dataset of 150k hours corpus, the 3M model has also shown obvious superiority over the baseline Conformer model. Code is publicly available at https://github.com/tencent-ailab/3m-asr.
SpeechMoE2: Mixture-of-Experts Model with Improved Routing
Nov 23, 2021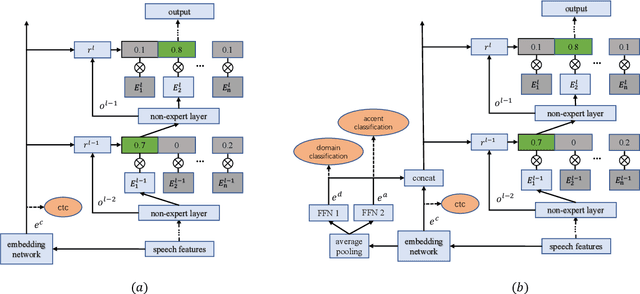
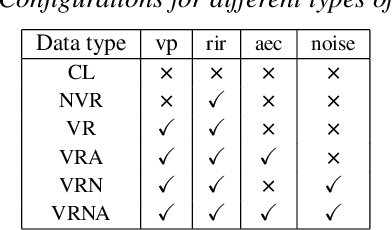
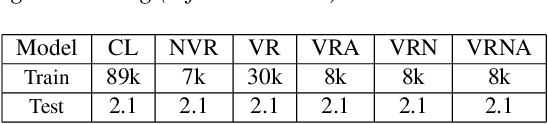
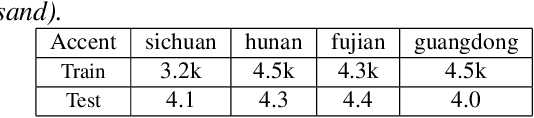
Mixture-of-experts based acoustic models with dynamic routing mechanisms have proved promising results for speech recognition. The design principle of router architecture is important for the large model capacity and high computational efficiency. Our previous work SpeechMoE only uses local grapheme embedding to help routers to make route decisions. To further improve speech recognition performance against varying domains and accents, we propose a new router architecture which integrates additional global domain and accent embedding into router input to promote adaptability. Experimental results show that the proposed SpeechMoE2 can achieve lower character error rate (CER) with comparable parameters than SpeechMoE on both multi-domain and multi-accent task. Primarily, the proposed method provides up to 1.6% - 4.8% relative CER improvement for the multidomain task and 1.9% - 17.7% relative CER improvement for the multi-accent task respectively. Besides, increasing the number of experts also achieves consistent performance improvement and keeps the computational cost constant.
GigaSpeech: An Evolving, Multi-domain ASR Corpus with 10,000 Hours of Transcribed Audio
Jun 13, 2021
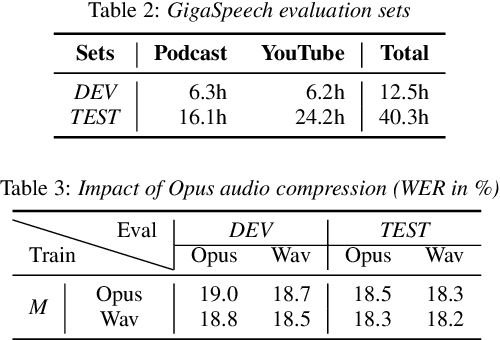
This paper introduces GigaSpeech, an evolving, multi-domain English speech recognition corpus with 10,000 hours of high quality labeled audio suitable for supervised training, and 40,000 hours of total audio suitable for semi-supervised and unsupervised training. Around 40,000 hours of transcribed audio is first collected from audiobooks, podcasts and YouTube, covering both read and spontaneous speaking styles, and a variety of topics, such as arts, science, sports, etc. A new forced alignment and segmentation pipeline is proposed to create sentence segments suitable for speech recognition training, and to filter out segments with low-quality transcription. For system training, GigaSpeech provides five subsets of different sizes, 10h, 250h, 1000h, 2500h, and 10000h. For our 10,000-hour XL training subset, we cap the word error rate at 4% during the filtering/validation stage, and for all our other smaller training subsets, we cap it at 0%. The DEV and TEST evaluation sets, on the other hand, are re-processed by professional human transcribers to ensure high transcription quality. Baseline systems are provided for popular speech recognition toolkits, namely Athena, ESPnet, Kaldi and Pika.
SpeechMoE: Scaling to Large Acoustic Models with Dynamic Routing Mixture of Experts
May 07, 2021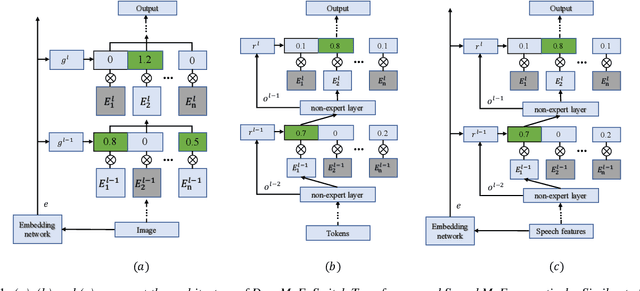
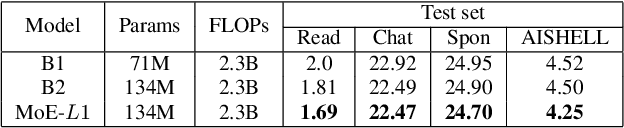
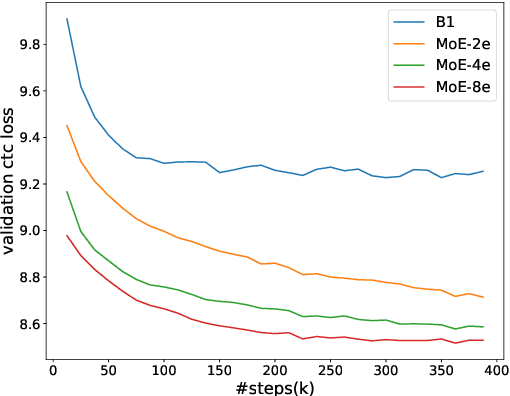
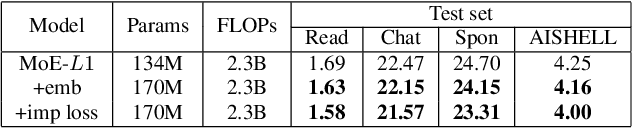
Recently, Mixture of Experts (MoE) based Transformer has shown promising results in many domains. This is largely due to the following advantages of this architecture: firstly, MoE based Transformer can increase model capacity without computational cost increasing both at training and inference time. Besides, MoE based Transformer is a dynamic network which can adapt to the varying complexity of input instances in realworld applications. In this work, we explore the MoE based model for speech recognition, named SpeechMoE. To further control the sparsity of router activation and improve the diversity of gate values, we propose a sparsity L1 loss and a mean importance loss respectively. In addition, a new router architecture is used in SpeechMoE which can simultaneously utilize the information from a shared embedding network and the hierarchical representation of different MoE layers. Experimental results show that SpeechMoE can achieve lower character error rate (CER) with comparable computation cost than traditional static networks, providing 7.0%-23.0% relative CER improvements on four evaluation datasets.
DFSMN-SAN with Persistent Memory Model for Automatic Speech Recognition
Oct 28, 2019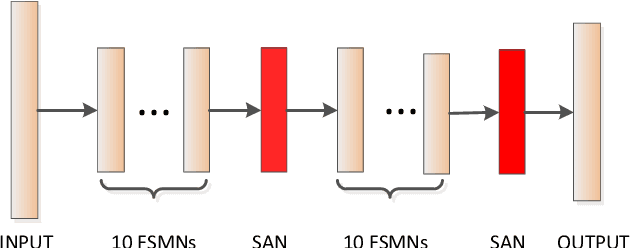



Self-attention networks (SAN) have been introduced into automatic speech recognition (ASR) and achieved state-of-the-art performance owing to its superior ability in capturing long term dependency. One of the key ingredients is the self-attention mechanism which can be effectively performed on the whole utterance level. In this paper, we try to investigate whether even more information beyond the whole utterance level can be exploited and beneficial. We propose to apply self-attention layer with augmented memory to ASR. Specifically, we first propose a variant model architecture which combines deep feed-forward sequential memory network (DFSMN) with self-attention layers to form a better baseline model compared with a purely self-attention network. Then, we propose and compare two kinds of additional memory structures added into self-attention layers. Experiments on large-scale LVCSR tasks show that on four individual test sets, the DFSMN-SAN architecture outperforms vanilla SAN encoder by 5% relatively in character error rate (CER). More importantly, the additional memory structure provides further 5% to 11% relative improvement in CER.
Teach an all-rounder with experts in different domains
Jul 09, 2019



In many automatic speech recognition (ASR) tasks, an ideal model has to be applicable over multiple domains. In this paper, we propose to teach an all-rounder with experts in different domains. Concretely, we build a multi-domain acoustic model by applying the teacher-student training framework. First, for each domain, a teacher model (domain-dependent model) is trained by fine-tuning a multi-condition model with domain-specific subset. Then all these teacher models are used to teach one single student model simultaneously. We perform experiments on two predefined domain setups. One is domains with different speaking styles, the other is nearfield, far-field and far-field with noise. Moreover, two types of models are examined: deep feedforward sequential memory network (DFSMN) and long short term memory (LSTM). Experimental results show that the model trained with this framework outperforms not only multi-condition model but also domain-dependent model. Specially, our training method provides up to 10.4% relative character error rate improvement over baseline model (multi-condition model).