 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCovo-Audio Technical Report
Feb 10, 2026In this work, we present Covo-Audio, a 7B-parameter end-to-end LALM that directly processes continuous audio inputs and generates audio outputs within a single unified architecture. Through large-scale curated pretraining and targeted post-training, Covo-Audio achieves state-of-the-art or competitive performance among models of comparable scale across a broad spectrum of tasks, including speech-text modeling, spoken dialogue, speech understanding, audio understanding, and full-duplex voice interaction. Extensive evaluations demonstrate that the pretrained foundation model exhibits strong speech-text comprehension and semantic reasoning capabilities on multiple benchmarks, outperforming representative open-source models of comparable scale. Furthermore, Covo-Audio-Chat, the dialogue-oriented variant, demonstrates strong spoken conversational abilities, including understanding, contextual reasoning, instruction following, and generating contextually appropriate and empathetic responses, validating its applicability to real-world conversational assistant scenarios. Covo-Audio-Chat-FD, the evolved full-duplex model, achieves substantially superior performance on both spoken dialogue capabilities and full-duplex interaction behaviors, demonstrating its competence in practical robustness. To mitigate the high cost of deploying end-to-end LALMs for natural conversational systems, we propose an intelligence-speaker decoupling strategy that separates dialogue intelligence from voice rendering, enabling flexible voice customization with minimal text-to-speech (TTS) data while preserving dialogue performance. Overall, our results highlight the strong potential of 7B-scale models to integrate sophisticated audio intelligence with high-level semantic reasoning, and suggest a scalable path toward more capable and versatile LALMs.
AUV: Teaching Audio Universal Vector Quantization with Single Nested Codebook
Sep 26, 2025We propose AUV, a unified neural audio codec with a single codebook, which enables a favourable reconstruction of speech and further extends to general audio, including vocal, music, and sound. AUV is capable of tackling any 16 kHz mixed-domain audio segment at bit rates around 700 bps. To accomplish this, we guide the matryoshka codebook with nested domain-specific partitions, assigned with corresponding teacher models to perform distillation, all in a single-stage training. A conformer-style encoder-decoder architecture with STFT features as audio representation is employed, yielding better audio quality. Comprehensive evaluations demonstrate that AUV exhibits comparable audio reconstruction ability to state-of-the-art domain-specific single-layer quantizer codecs, showcasing the potential of audio universal vector quantization with a single codebook. The pre-trained model and demo samples are available at https://swivid.github.io/AUV/.
3M: Multi-loss, Multi-path and Multi-level Neural Networks for speech recognition
Apr 14, 2022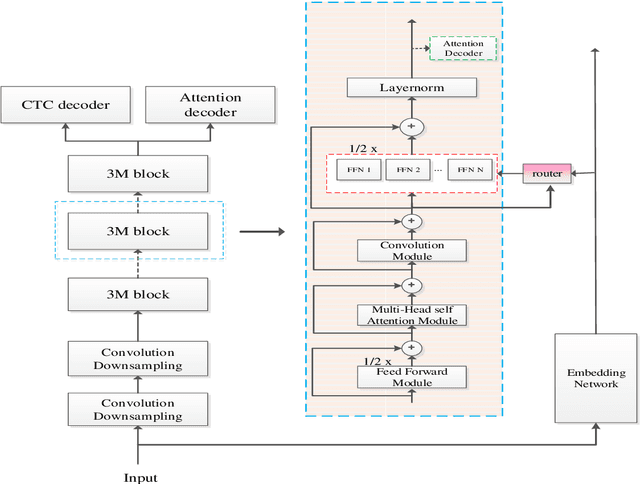
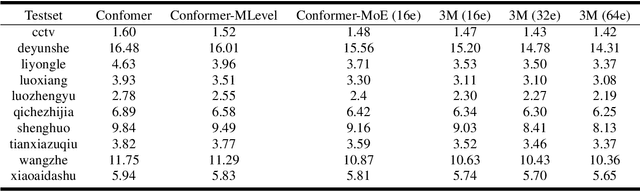
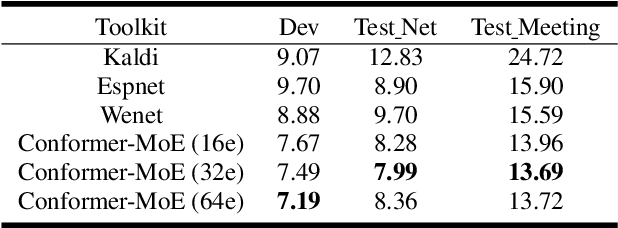
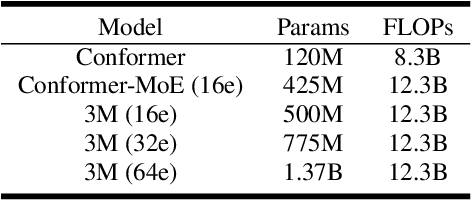
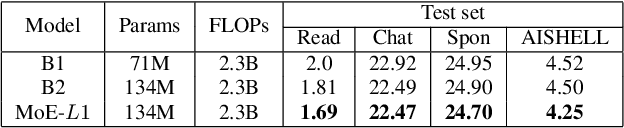
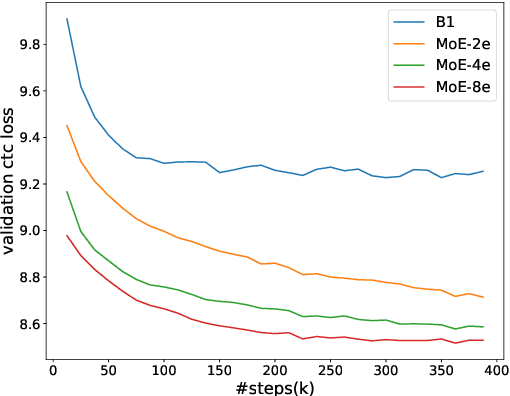
Recently, Conformer based CTC/AED model has become a mainstream architecture for ASR. In this paper, based on our prior work, we identify and integrate several approaches to achieve further improvements for ASR tasks, which we denote as multi-loss, multi-path and multi-level, summarized as "3M" model. Specifically, multi-loss refers to the joint CTC/AED loss and multi-path denotes the Mixture-of-Experts(MoE) architecture which can effectively increase the model capacity without remarkably increasing computation cost. Multi-level means that we introduce auxiliary loss at multiple level of a deep model to help training. We evaluate our proposed method on the public WenetSpeech dataset and experimental results show that the proposed method provides 12.2%-17.6% relative CER improvement over the baseline model trained by Wenet toolkit. On our large scale dataset of 150k hours corpus, the 3M model has also shown obvious superiority over the baseline Conformer model. Code is publicly available at https://github.com/tencent-ailab/3m-asr.
SpeechMoE2: Mixture-of-Experts Model with Improved Routing
Nov 23, 2021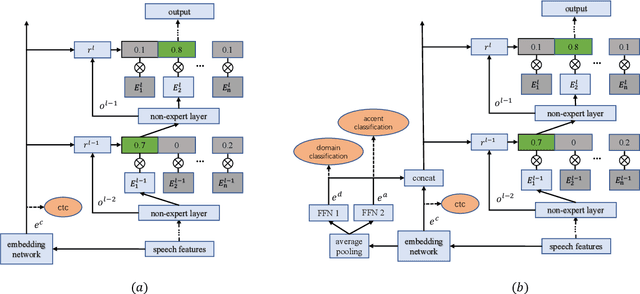
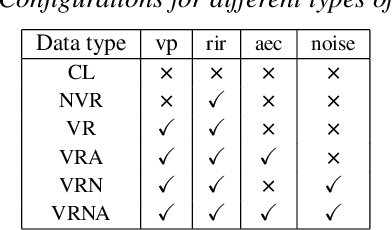
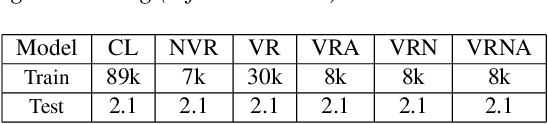
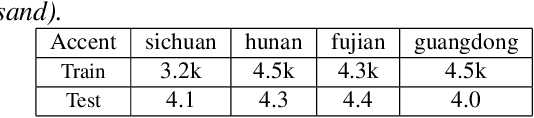
Mixture-of-experts based acoustic models with dynamic routing mechanisms have proved promising results for speech recognition. The design principle of router architecture is important for the large model capacity and high computational efficiency. Our previous work SpeechMoE only uses local grapheme embedding to help routers to make route decisions. To further improve speech recognition performance against varying domains and accents, we propose a new router architecture which integrates additional global domain and accent embedding into router input to promote adaptability. Experimental results show that the proposed SpeechMoE2 can achieve lower character error rate (CER) with comparable parameters than SpeechMoE on both multi-domain and multi-accent task. Primarily, the proposed method provides up to 1.6% - 4.8% relative CER improvement for the multidomain task and 1.9% - 17.7% relative CER improvement for the multi-accent task respectively. Besides, increasing the number of experts also achieves consistent performance improvement and keeps the computational cost constant.
Latency-Controlled Neural Architecture Search for Streaming Speech Recognition
May 08, 2021


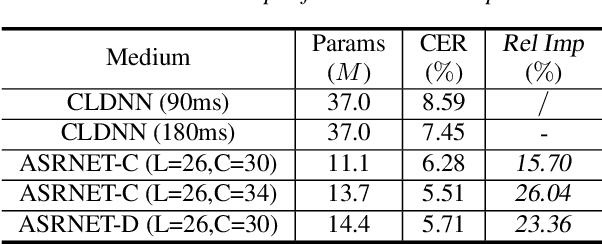
Recently, neural architecture search (NAS) has attracted much attention and has been explored for automatic speech recognition (ASR). Our prior work has shown promising results compared with hand-designed neural networks. In this work, we focus on streaming ASR scenarios and propose the latency-controlled NAS for acoustic modeling. First, based on the vanilla neural architecture, normal cells are altered to be causal cells, in order to control the total latency of the neural network. Second, a revised operation space with a smaller receptive field is proposed to generate the final architecture with low latency. Extensive experiments show that: 1) Based on the proposed neural architecture, the neural networks with a medium latency of 550ms (millisecond) and a low latency of 190ms can be learned in the vanilla and revised operation space respectively. 2) For the low latency setting, the evaluation network can achieve more than 19\% (average on the four test sets) relative improvements compared with the hybrid CLDNN baseline, on a 10k-hour large-scale dataset. Additional 11\% relative improvements can be achieved if the latency of the neural network is relaxed to the medium latency setting.
SpeechMoE: Scaling to Large Acoustic Models with Dynamic Routing Mixture of Experts
May 07, 2021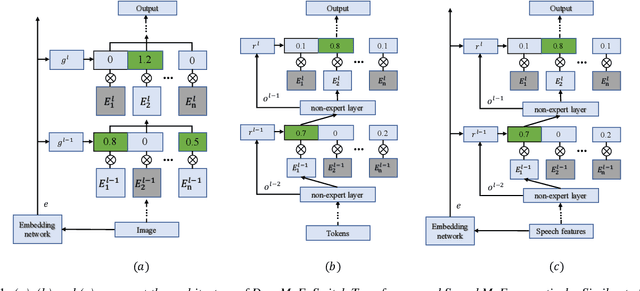
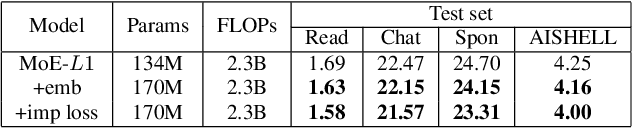
Recently, Mixture of Experts (MoE) based Transformer has shown promising results in many domains. This is largely due to the following advantages of this architecture: firstly, MoE based Transformer can increase model capacity without computational cost increasing both at training and inference time. Besides, MoE based Transformer is a dynamic network which can adapt to the varying complexity of input instances in realworld applications. In this work, we explore the MoE based model for speech recognition, named SpeechMoE. To further control the sparsity of router activation and improve the diversity of gate values, we propose a sparsity L1 loss and a mean importance loss respectively. In addition, a new router architecture is used in SpeechMoE which can simultaneously utilize the information from a shared embedding network and the hierarchical representation of different MoE layers. Experimental results show that SpeechMoE can achieve lower character error rate (CER) with comparable computation cost than traditional static networks, providing 7.0%-23.0% relative CER improvements on four evaluation datasets.
Learning discriminative features in sequence training without requiring framewise labelled data
May 16, 2019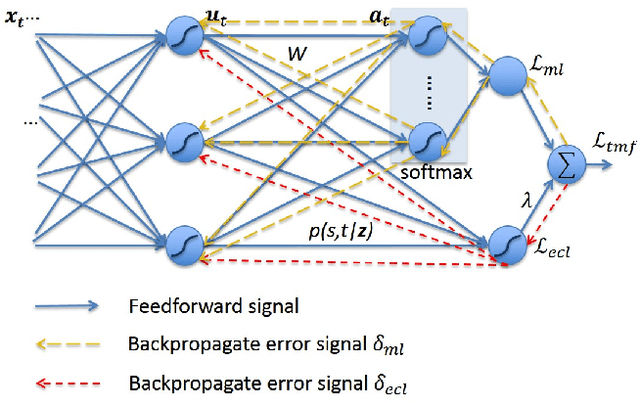
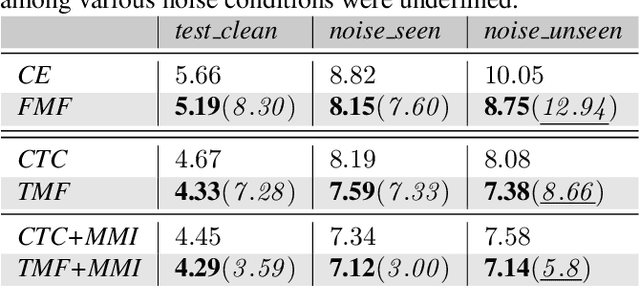
In this work, we try to answer two questions: Can deeply learned features with discriminative power benefit an ASR system's robustness to acoustic variability? And how to learn them without requiring framewise labelled sequence training data? As existing methods usually require knowing where the labels occur in the input sequence, they have so far been limited to many real-world sequence learning tasks. We propose a novel method which simultaneously models both the sequence discriminative training and the feature discriminative learning within a single network architecture, so that it can learn discriminative deep features in sequence training that obviates the need for presegmented training data. Our experiment in a realistic industrial ASR task shows that, without requiring any specific fine-tuning or additional complexity, our proposed models have consistently outperformed state-of-the-art models and significantly reduced Word Error Rate (WER) under all test conditions, and especially with highest improvements under unseen noise conditions, by relative 12.94%, 8.66% and 5.80%, showing our proposed models can generalize better to acoustic variability.