 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning discriminative features in sequence training without requiring framewise labelled data
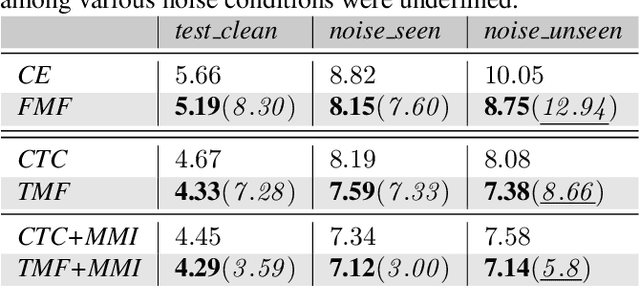
May 16, 2019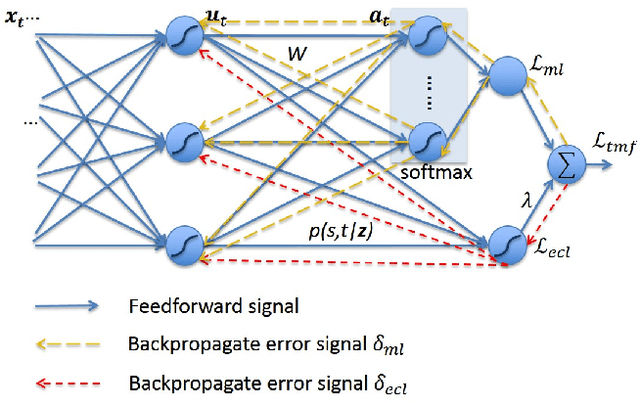
In this work, we try to answer two questions: Can deeply learned features with discriminative power benefit an ASR system's robustness to acoustic variability? And how to learn them without requiring framewise labelled sequence training data? As existing methods usually require knowing where the labels occur in the input sequence, they have so far been limited to many real-world sequence learning tasks. We propose a novel method which simultaneously models both the sequence discriminative training and the feature discriminative learning within a single network architecture, so that it can learn discriminative deep features in sequence training that obviates the need for presegmented training data. Our experiment in a realistic industrial ASR task shows that, without requiring any specific fine-tuning or additional complexity, our proposed models have consistently outperformed state-of-the-art models and significantly reduced Word Error Rate (WER) under all test conditions, and especially with highest improvements under unseen noise conditions, by relative 12.94%, 8.66% and 5.80%, showing our proposed models can generalize better to acoustic variability.