 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Pre-trained Speech Language Model with Efficient Hierarchical Transformer
Jun 03, 2024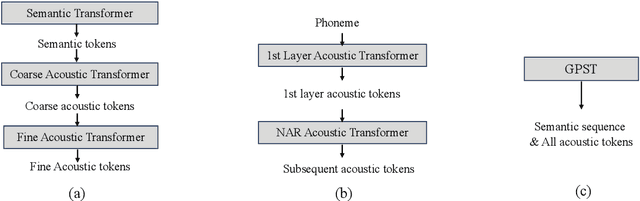
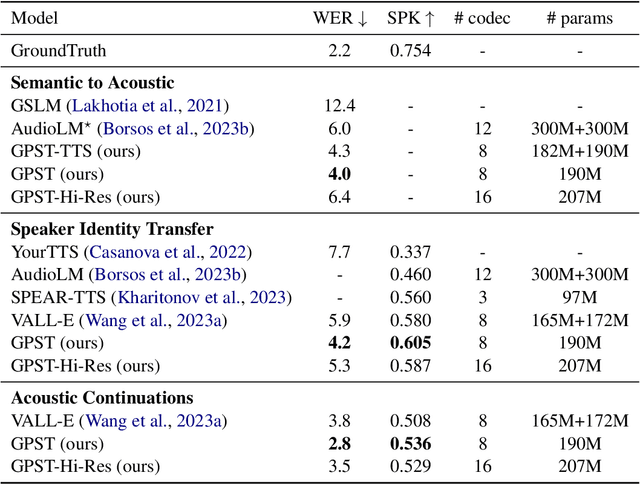
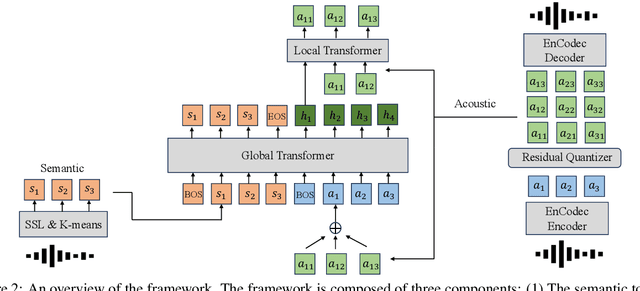
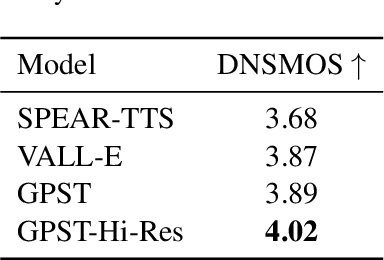
While recent advancements in speech language models have achieved significant progress, they face remarkable challenges in modeling the long acoustic sequences of neural audio codecs. In this paper, we introduce \textbf{G}enerative \textbf{P}re-trained \textbf{S}peech \textbf{T}ransformer (GPST), a hierarchical transformer designed for efficient speech language modeling. GPST quantizes audio waveforms into two distinct types of discrete speech representations and integrates them within a hierarchical transformer architecture, allowing for a unified one-stage generation process and enhancing Hi-Res audio generation capabilities. By training on large corpora of speeches in an end-to-end unsupervised manner, GPST can generate syntactically consistent speech with diverse speaker identities. Given a brief 3-second prompt, GPST can produce natural and coherent personalized speech, demonstrating in-context learning abilities. Moreover, our approach can be easily extended to spoken cross-lingual speech generation by incorporating multi-lingual semantic tokens and universal acoustic tokens. Experimental results indicate that GPST significantly outperforms the existing speech language models in terms of word error rate, speech quality, and speaker similarity. See \url{https://youngsheen.github.io/GPST/demo} for demo samples.
Fuse after Align: Improving Face-Voice Association Learning via Multimodal Encoder
Apr 15, 2024Today, there have been many achievements in learning the association between voice and face. However, most previous work models rely on cosine similarity or L2 distance to evaluate the likeness of voices and faces following contrastive learning, subsequently applied to retrieval and matching tasks. This method only considers the embeddings as high-dimensional vectors, utilizing a minimal scope of available information. This paper introduces a novel framework within an unsupervised setting for learning voice-face associations. By employing a multimodal encoder after contrastive learning and addressing the problem through binary classification, we can learn the implicit information within the embeddings in a more effective and varied manner. Furthermore, by introducing an effective pair selection method, we enhance the learning outcomes of both contrastive learning and the matching task. Empirical evidence demonstrates that our framework achieves state-of-the-art results in voice-face matching, verification, and retrieval tasks, improving verification by approximately 3%, matching by about 2.5%, and retrieval by around 1.3%.
Latency-Controlled Neural Architecture Search for Streaming Speech Recognition
May 08, 2021


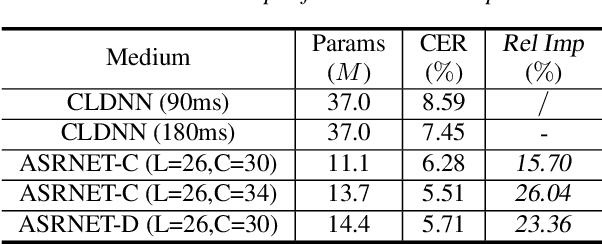
Recently, neural architecture search (NAS) has attracted much attention and has been explored for automatic speech recognition (ASR). Our prior work has shown promising results compared with hand-designed neural networks. In this work, we focus on streaming ASR scenarios and propose the latency-controlled NAS for acoustic modeling. First, based on the vanilla neural architecture, normal cells are altered to be causal cells, in order to control the total latency of the neural network. Second, a revised operation space with a smaller receptive field is proposed to generate the final architecture with low latency. Extensive experiments show that: 1) Based on the proposed neural architecture, the neural networks with a medium latency of 550ms (millisecond) and a low latency of 190ms can be learned in the vanilla and revised operation space respectively. 2) For the low latency setting, the evaluation network can achieve more than 19\% (average on the four test sets) relative improvements compared with the hybrid CLDNN baseline, on a 10k-hour large-scale dataset. Additional 11\% relative improvements can be achieved if the latency of the neural network is relaxed to the medium latency setting.
Phrase-Level Class based Language Model for Mandarin Smart Speaker Query Recognition
Sep 02, 2019
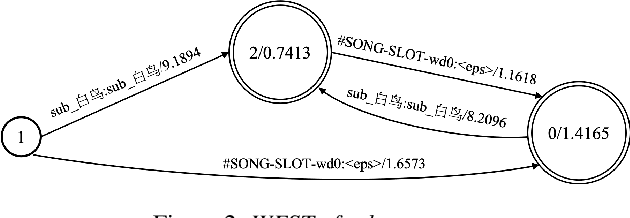
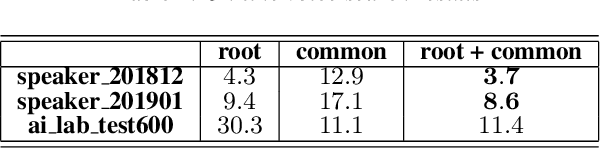
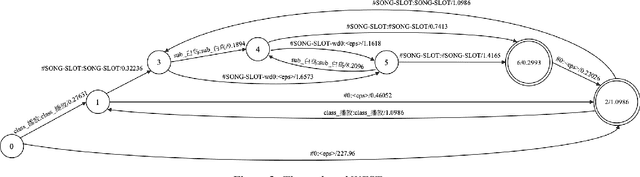
The success of speech assistants requires precise recognition of a number of entities on particular contexts. A common solution is to train a class-based n-gram language model and then expand the classes into specific words or phrases. However, when the class has a huge list, e.g., more than 20 million songs, a fully expansion will cause memory explosion. Worse still, the list items in the class need to be updated frequently, which requires a dynamic model updating technique. In this work, we propose to train pruned language models for the word classes to replace the slots in the root n-gram. We further propose to use a novel technique, named Difference Language Model (DLM), to correct the bias from the pruned language models. Once the decoding graph is built, we only need to recalculate the DLM when the entities in word classes are updated. Results show that the proposed method consistently and significantly outperforms the conventional approaches on all datasets, esp. for large lists, which the conventional approaches cannot handle.