 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDASP: Self-supervised Nighttime Monocular Depth Estimation with Domain Adaptation of Spatiotemporal Priors
Dec 16, 2025Self-supervised monocular depth estimation has achieved notable success under daytime conditions. However, its performance deteriorates markedly at night due to low visibility and varying illumination, e.g., insufficient light causes textureless areas, and moving objects bring blurry regions. To this end, we propose a self-supervised framework named DASP that leverages spatiotemporal priors for nighttime depth estimation. Specifically, DASP consists of an adversarial branch for extracting spatiotemporal priors and a self-supervised branch for learning. In the adversarial branch, we first design an adversarial network where the discriminator is composed of four devised spatiotemporal priors learning blocks (SPLB) to exploit the daytime priors. In particular, the SPLB contains a spatial-based temporal learning module (STLM) that uses orthogonal differencing to extract motion-related variations along the time axis and an axial spatial learning module (ASLM) that adopts local asymmetric convolutions with global axial attention to capture the multiscale structural information. By combining STLM and ASLM, our model can acquire sufficient spatiotemporal features to restore textureless areas and estimate the blurry regions caused by dynamic objects. In the self-supervised branch, we propose a 3D consistency projection loss to bilaterally project the target frame and source frame into a shared 3D space, and calculate the 3D discrepancy between the two projected frames as a loss to optimize the 3D structural consistency and daytime priors. Extensive experiments on the Oxford RobotCar and nuScenes datasets demonstrate that our approach achieves state-of-the-art performance for nighttime depth estimation. Ablation studies further validate the effectiveness of each component.
GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning
Jul 02, 2025



We present GLM-4.1V-Thinking, a vision-language model (VLM) designed to advance general-purpose multimodal understanding and reasoning. In this report, we share our key findings in the development of the reasoning-centric training framework. We first develop a capable vision foundation model with significant potential through large-scale pre-training, which arguably sets the upper bound for the final performance. We then propose Reinforcement Learning with Curriculum Sampling (RLCS) to unlock the full potential of the model, leading to comprehensive capability enhancement across a diverse range of tasks, including STEM problem solving, video understanding, content recognition, coding, grounding, GUI-based agents, and long document understanding. We open-source GLM-4.1V-9B-Thinking, which achieves state-of-the-art performance among models of comparable size. In a comprehensive evaluation across 28 public benchmarks, our model outperforms Qwen2.5-VL-7B on nearly all tasks and achieves comparable or even superior performance on 18 benchmarks relative to the significantly larger Qwen2.5-VL-72B. Notably, GLM-4.1V-9B-Thinking also demonstrates competitive or superior performance compared to closed-source models such as GPT-4o on challenging tasks including long document understanding and STEM reasoning, further underscoring its strong capabilities. Code, models and more information are released at https://github.com/THUDM/GLM-4.1V-Thinking.
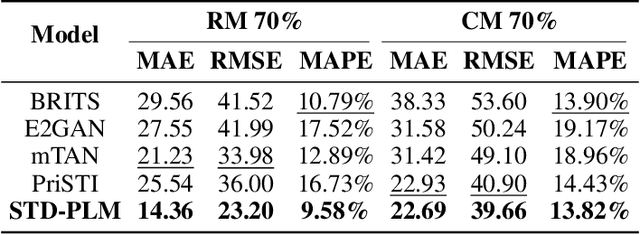
An Experimental Evaluation of Imputation Models for Spatial-Temporal Traffic Data
Dec 06, 2024



Traffic data imputation is a critical preprocessing step in intelligent transportation systems, enabling advanced transportation services. Despite significant advancements in this field, selecting the most suitable model for practical applications remains challenging due to three key issues: 1) incomprehensive consideration of missing patterns that describe how data loss along spatial and temporal dimensions, 2) the lack of test on standardized datasets, and 3) insufficient evaluations. To this end, we first propose practice-oriented taxonomies for missing patterns and imputation models, systematically identifying all possible forms of real-world traffic data loss and analyzing the characteristics of existing models. Furthermore, we introduce a unified benchmarking pipeline to comprehensively evaluate 10 representative models across various missing patterns and rates. This work aims to provide a holistic understanding of traffic data imputation research and serve as a practical guideline.
DistillGrasp: Integrating Features Correlation with Knowledge Distillation for Depth Completion of Transparent Objects
Aug 01, 2024Due to the visual properties of reflection and refraction, RGB-D cameras cannot accurately capture the depth of transparent objects, leading to incomplete depth maps. To fill in the missing points, recent studies tend to explore new visual features and design complex networks to reconstruct the depth, however, these approaches tremendously increase computation, and the correlation of different visual features remains a problem. To this end, we propose an efficient depth completion network named DistillGrasp which distillates knowledge from the teacher branch to the student branch. Specifically, in the teacher branch, we design a position correlation block (PCB) that leverages RGB images as the query and key to search for the corresponding values, guiding the model to establish correct correspondence between two features and transfer it to the transparent areas. For the student branch, we propose a consistent feature correlation module (CFCM) that retains the reliable regions of RGB images and depth maps respectively according to the consistency and adopts a CNN to capture the pairwise relationship for depth completion. To avoid the student branch only learning regional features from the teacher branch, we devise a distillation loss that not only considers the distance loss but also the object structure and edge information. Extensive experiments conducted on the ClearGrasp dataset manifest that our teacher network outperforms state-of-the-art methods in terms of accuracy and generalization, and the student network achieves competitive results with a higher speed of 48 FPS. In addition, the significant improvement in a real-world robotic grasping system illustrates the effectiveness and robustness of our proposed system.
STD-LLM: Understanding Both Spatial and Temporal Properties of Spatial-Temporal Data with LLMs
Jul 12, 2024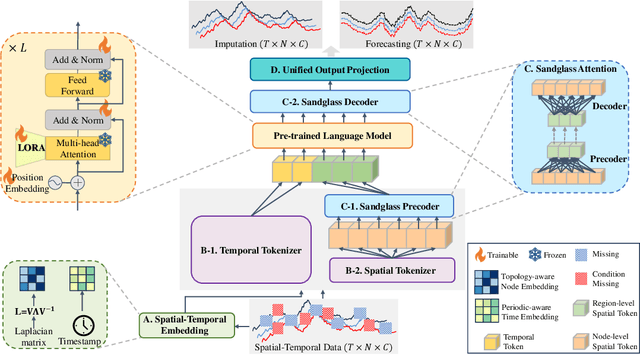
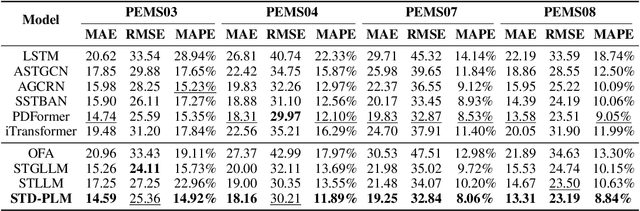

Spatial-temporal forecasting and imputation are important for real-world dynamic systems such as intelligent transportation, urban planning, and public health. Most existing methods are tailored for individual forecasting or imputation tasks but are not designed for both. Additionally, they are less effective for zero-shot and few-shot learning. While large language models (LLMs) have exhibited strong pattern recognition and reasoning abilities across various tasks, including few-shot and zero-shot learning, their development in understanding spatial-temporal data has been constrained by insufficient modeling of complex correlations such as the temporal correlations, spatial connectivity, non-pairwise and high-order spatial-temporal correlations within data. In this paper, we propose STD-LLM for understanding both spatial and temporal properties of \underline{S}patial-\underline{T}emporal \underline{D}ata with \underline{LLM}s, which is capable of implementing both spatial-temporal forecasting and imputation tasks. STD-LLM understands spatial-temporal correlations via explicitly designed spatial and temporal tokenizers as well as virtual nodes. Topology-aware node embeddings are designed for LLMs to comprehend and exploit the topology structure of data. Additionally, to capture the non-pairwise and higher-order correlations, we design a hypergraph learning module for LLMs, which can enhance the overall performance and improve efficiency. Extensive experiments demonstrate that STD-LLM exhibits strong performance and generalization capabilities across the forecasting and imputation tasks on various datasets. Moreover, STD-LLM achieves promising results on both few-shot and zero-shot learning tasks.
StableMoFusion: Towards Robust and Efficient Diffusion-based Motion Generation Framework
May 09, 2024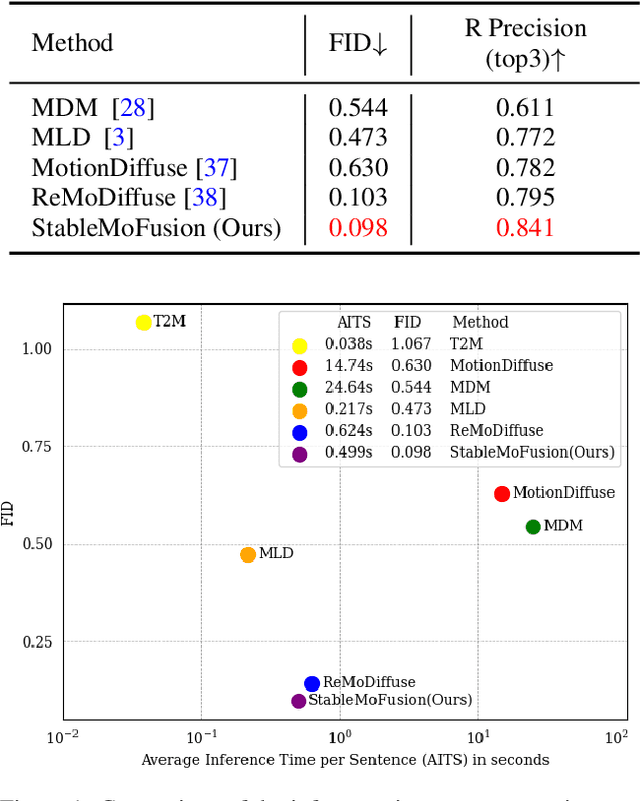
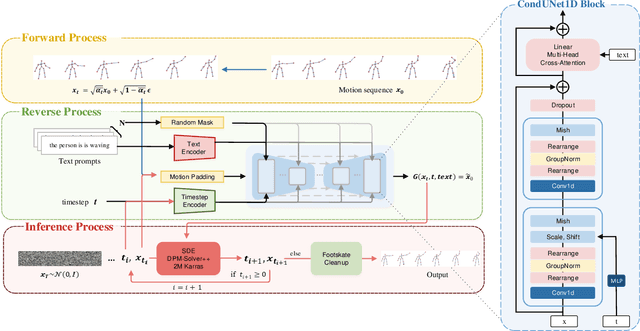
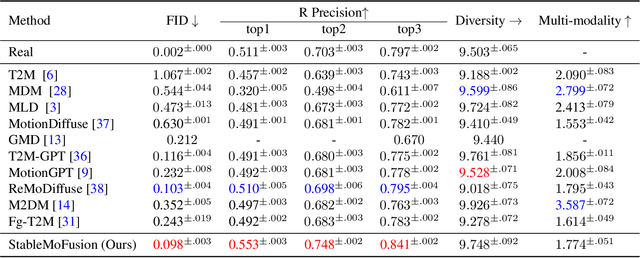
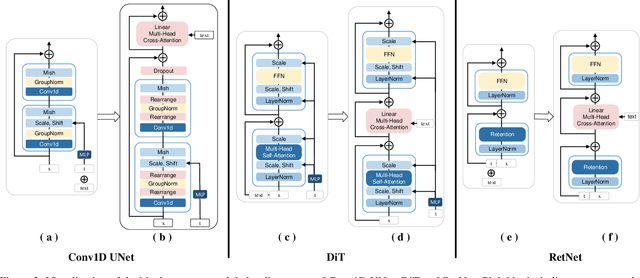
Thanks to the powerful generative capacity of diffusion models, recent years have witnessed rapid progress in human motion generation. Existing diffusion-based methods employ disparate network architectures and training strategies. The effect of the design of each component is still unclear. In addition, the iterative denoising process consumes considerable computational overhead, which is prohibitive for real-time scenarios such as virtual characters and humanoid robots. For this reason, we first conduct a comprehensive investigation into network architectures, training strategies, and inference processs. Based on the profound analysis, we tailor each component for efficient high-quality human motion generation. Despite the promising performance, the tailored model still suffers from foot skating which is an ubiquitous issue in diffusion-based solutions. To eliminate footskate, we identify foot-ground contact and correct foot motions along the denoising process. By organically combining these well-designed components together, we present StableMoFusion, a robust and efficient framework for human motion generation. Extensive experimental results show that our StableMoFusion performs favorably against current state-of-the-art methods. Project page: https://h-y1heng.github.io/StableMoFusion-page/
Diff-RNTraj: A Structure-aware Diffusion Model for Road Network-constrained Trajectory Generation
Feb 12, 2024Trajectory data is essential for various applications as it records the movement of vehicles. However, publicly available trajectory datasets remain limited in scale due to privacy concerns, which hinders the development of trajectory data mining and trajectory-based applications. To address this issue, some methods for generating synthetic trajectories have been proposed to expand the scale of the dataset. However, all existing methods generate trajectories in the geographical coordinate system, which poses two limitations for their utilization in practical applications: 1) the inability to ensure that the generated trajectories are constrained on the road. 2) the lack of road-related information. In this paper, we propose a new problem to meet the practical application need, \emph{i.e.}, road network-constrained trajectory (RNTraj) generation, which can directly generate trajectories on the road network with road-related information. RNTraj is a hybrid type of data, in which each point is represented by a discrete road segment and a continuous moving rate. To generate RNTraj, we design a diffusion model called Diff-RNTraj. This model can effectively handle the hybrid RNTraj using a continuous diffusion framework by incorporating a pre-training strategy to embed hybrid RNTraj into continuous representations. During the sampling stage, a RNTraj decoder is designed to map the continuous representation generated by the diffusion model back to the hybrid RNTraj format. Furthermore, Diff-RNTraj introduces a novel loss function to enhance the spatial validity of the generated trajectories. Extensive experiments conducted on two real-world trajectory datasets demonstrate the effectiveness of the proposed model.
Non-Autoregressive Transformer ASR with CTC-Enhanced Decoder Input
Oct 28, 2020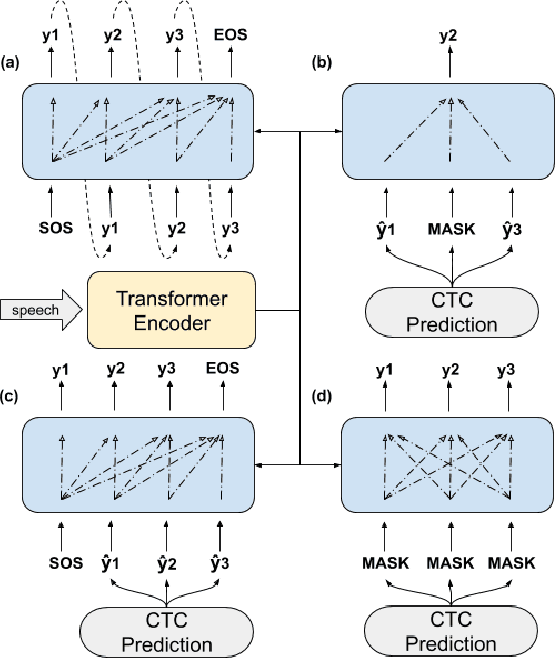
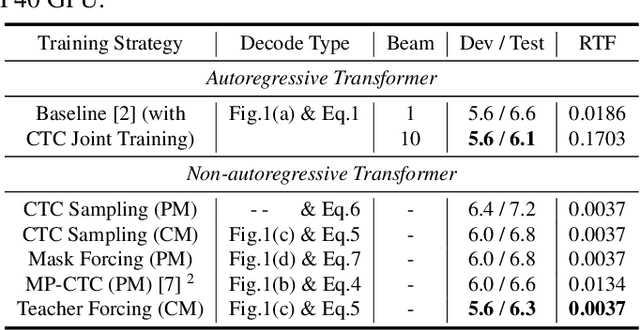
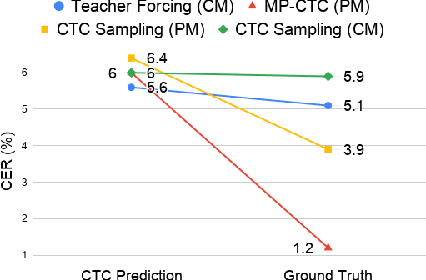

Non-autoregressive (NAR) transformer models have achieved significantly inference speedup but at the cost of inferior accuracy compared to autoregressive (AR) models in automatic speech recognition (ASR). Most of the NAR transformers take a fixed-length sequence filled with MASK tokens or a redundant sequence copied from encoder states as decoder input, they cannot provide efficient target-side information thus leading to accuracy degradation. To address this problem, we propose a CTC-enhanced NAR transformer, which generates target sequence by refining predictions of the CTC module. Experimental results show that our method outperforms all previous NAR counterparts and achieves 50x faster decoding speed than a strong AR baseline with only 0.0 ~ 0.3 absolute CER degradation on Aishell-1 and Aishell-2 datasets.
Speech-XLNet: Unsupervised Acoustic Model Pretraining For Self-Attention Networks
Oct 23, 2019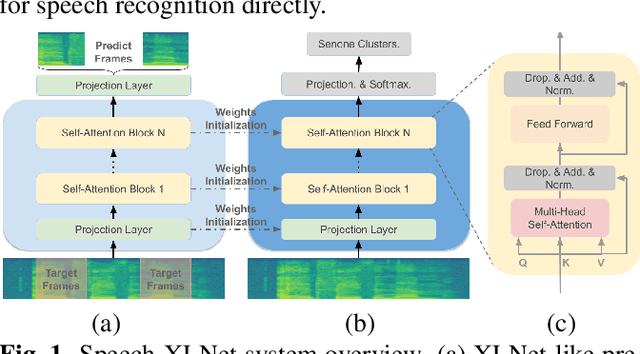
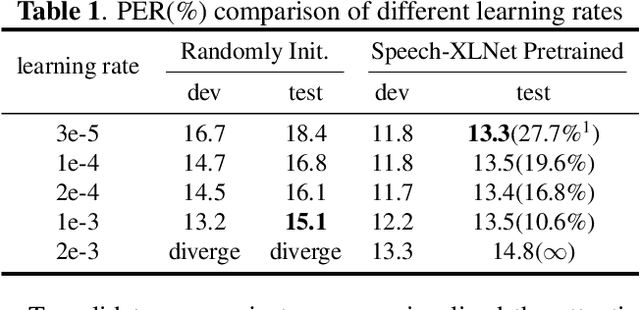
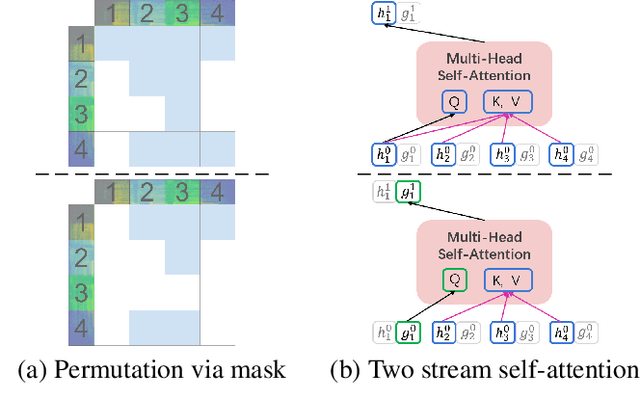
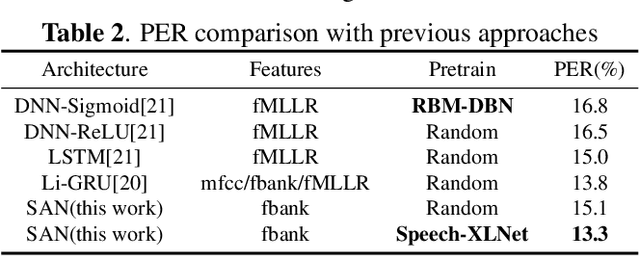
Self-attention network (SAN) can benefit significantly from the bi-directional representation learning through unsupervised pretraining paradigms such as BERT and XLNet. In this paper, we present an XLNet-like pretraining scheme "Speech-XLNet" for unsupervised acoustic model pretraining to learn speech representations with SAN. The pretrained SAN is finetuned under the hybrid SAN/HMM framework. We conjecture that by shuffling the speech frame orders, the permutation in Speech-XLNet serves as a strong regularizer to encourage the SAN to make inferences by focusing on global structures through its attention weights. In addition, Speech-XLNet also allows the model to explore the bi-directional contexts for effective speech representation learning. Experiments on TIMIT and WSJ demonstrate that Speech-XLNet greatly improves the SAN/HMM performance in terms of both convergence speed and recognition accuracy compared to the one trained from randomly initialized weights. Our best systems achieve a relative improvement of 11.9% and 8.3% on the TIMIT and WSJ tasks respectively. In particular, the best system achieves a phone error rate (PER) of 13.3% on the TIMIT test set, which to our best knowledge, is the lowest PER obtained from a single system.
A Random Gossip BMUF Process for Neural Language Modeling
Oct 16, 2019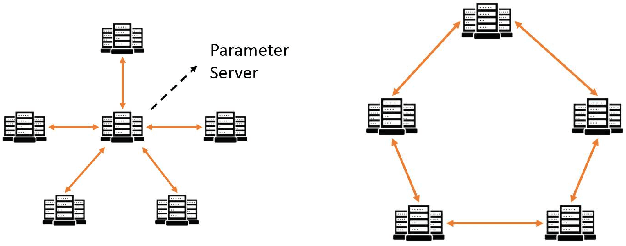
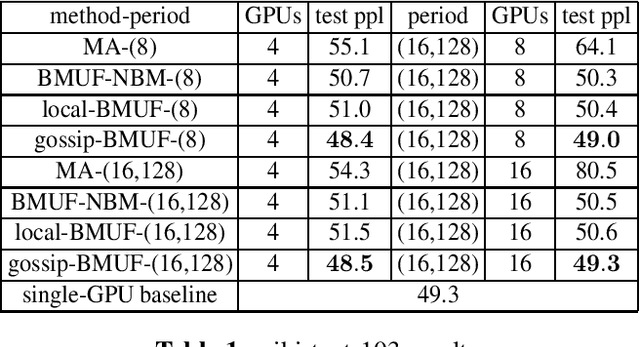
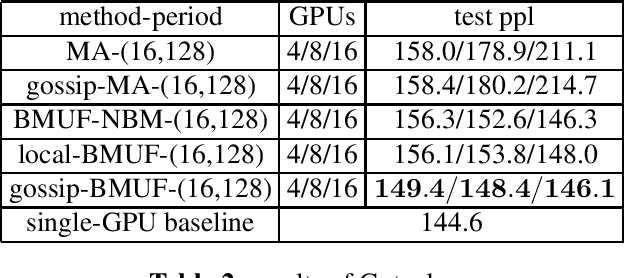
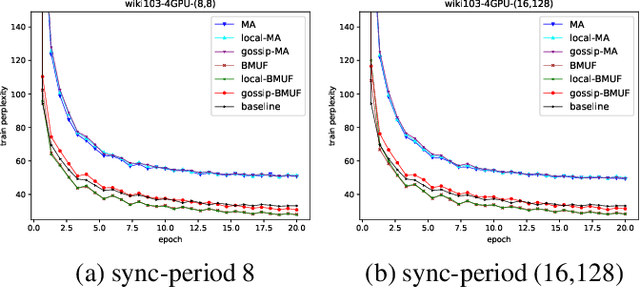
Neural network language model (NNLM) is an essential component of industrial ASR systems. One important challenge of training an NNLM is to leverage between scaling the learning process and handling big data. Conventional approaches such as block momentum provides a blockwise model update filtering (BMUF) process and achieves almost linear speedups with no performance degradation for speech recognition. However, it needs to calculate the model average from all computing nodes (e.g., GPUs) and when the number of computing nodes is large, the learning suffers from the severe communication latency. As a consequence, BMUF is not suitable under restricted network conditions. In this paper, we present a decentralized BMUF process, in which the model is split into different components, each of which is updated by communicating to some randomly chosen neighbor nodes with the same component, followed by a BMUF-like process. We apply this method to several LSTM language modeling tasks. Experimental results show that our approach achieves consistently better performance than conventional BMUF. In particular, we obtain a lower perplexity than the single-GPU baseline on the wiki-text-103 benchmark using 4 GPUs. In addition, no performance degradation is observed when scaling to 8 and 16 GPUs.