 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBotSIM: An End-to-End Bot Simulation Toolkit for Commercial Task-Oriented Dialog Systems
Nov 30, 2022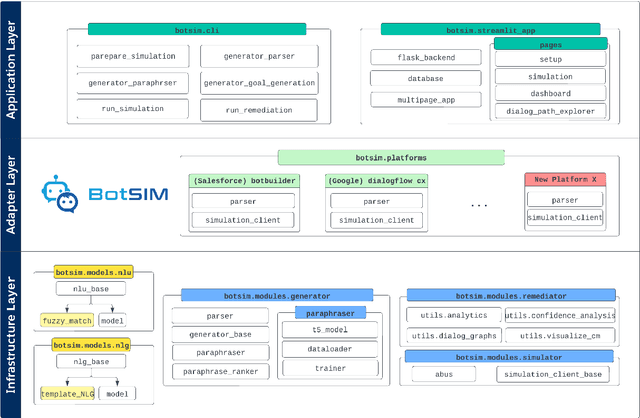
We introduce BotSIM, a modular, open-source Bot SIMulation environment with dialog generation, user simulation and conversation analytics capabilities. BotSIM aims to serve as a one-stop solution for large-scale data-efficient end-to-end evaluation, diagnosis and remediation of commercial task-oriented dialog (TOD) systems to significantly accelerate commercial bot development and evaluation, reduce cost and time-to-market. BotSIM adopts a layered design comprising the infrastructure layer, the adaptor layer and the application layer. The infrastructure layer hosts key models and components to support BotSIM's major functionalities via a streamlined "generation-simulation-remediation" pipeline. The adaptor layer is used to extend BotSIM to accommodate new bot platforms. The application layer provides a suite of command line tools and a Web App to significantly lower the entry barrier for BotSIM users such as bot admins or practitioners. In this report, we focus on the technical designs of various system components. A detailed case study using Einstein BotBuilder is also presented to show how to apply BotSIM pipeline for bot evaluation and remediation. The detailed system descriptions can be found in our system demo paper. The toolkit is available at: https://github.com/salesforce/BotSIM .
BotSIM: An End-to-End Bot Simulation Framework for Commercial Task-Oriented Dialog Systems
Nov 30, 2022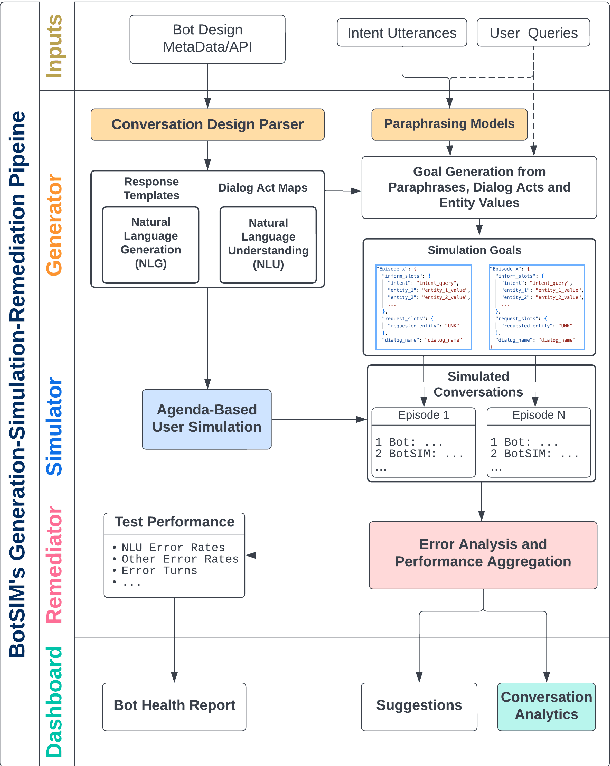


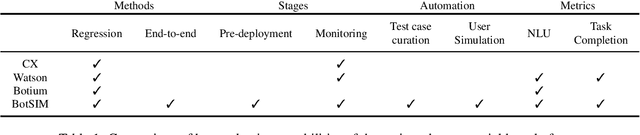
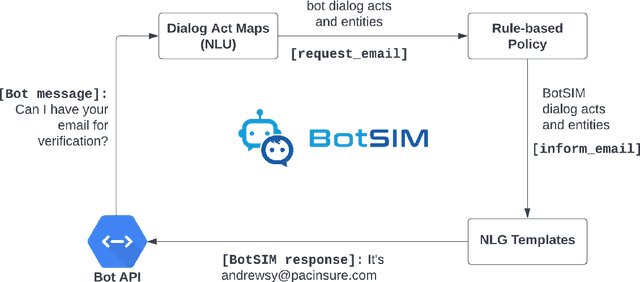
We present BotSIM, a data-efficient end-to-end Bot SIMulation toolkit for commercial text-based task-oriented dialog (TOD) systems. BotSIM consists of three major components: 1) a Generator that can infer semantic-level dialog acts and entities from bot definitions and generate user queries via model-based paraphrasing; 2) an agenda-based dialog user Simulator (ABUS) to simulate conversations with the dialog agents; 3) a Remediator to analyze the simulated conversations, visualize the bot health reports and provide actionable remediation suggestions for bot troubleshooting and improvement. We demonstrate BotSIM's effectiveness in end-to-end evaluation, remediation and multi-intent dialog generation via case studies on two commercial bot platforms. BotSIM's "generation-simulation-remediation" paradigm accelerates the end-to-end bot evaluation and iteration process by: 1) reducing manual test cases creation efforts; 2) enabling a holistic gauge of the bot in terms of NLU and end-to-end performance via extensive dialog simulation; 3) improving the bot troubleshooting process with actionable suggestions. A demo of our system can be found at https://tinyurl.com/mryu74cd and a demo video at https://youtu.be/qLi5iSoly30. We have open-sourced the toolkit at https://github.com/salesforce/botsim
LAVIS: A Library for Language-Vision Intelligence
Sep 15, 2022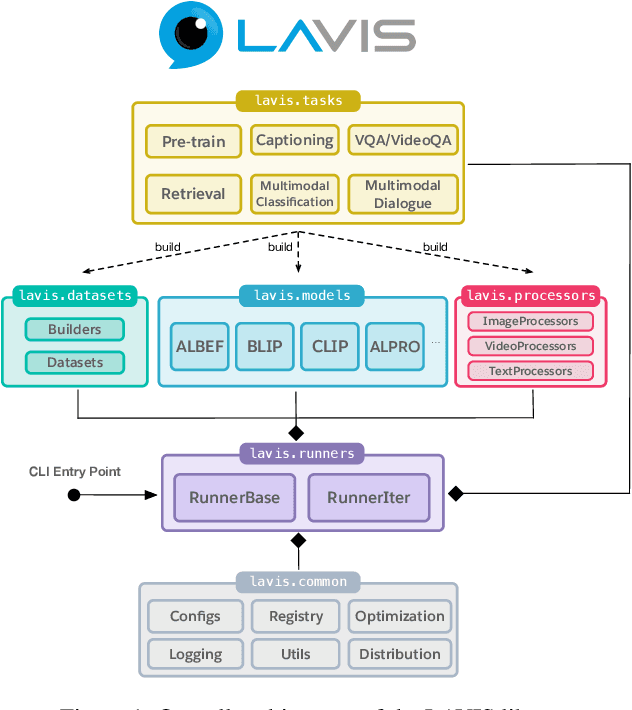
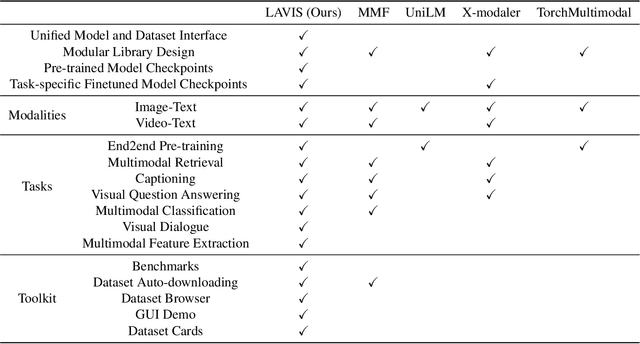
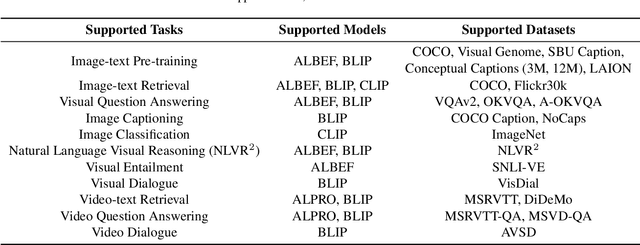

We introduce LAVIS, an open-source deep learning library for LAnguage-VISion research and applications. LAVIS aims to serve as a one-stop comprehensive library that brings recent advancements in the language-vision field accessible for researchers and practitioners, as well as fertilizing future research and development. It features a unified interface to easily access state-of-the-art image-language, video-language models and common datasets. LAVIS supports training, evaluation and benchmarking on a rich variety of tasks, including multimodal classification, retrieval, captioning, visual question answering, dialogue and pre-training. In the meantime, the library is also highly extensible and configurable, facilitating future development and customization. In this technical report, we describe design principles, key components and functionalities of the library, and also present benchmarking results across common language-vision tasks. The library is available at: https://github.com/salesforce/LAVIS.
Adapt-and-Adjust: Overcoming the Long-Tail Problem of Multilingual Speech Recognition
Dec 03, 2020
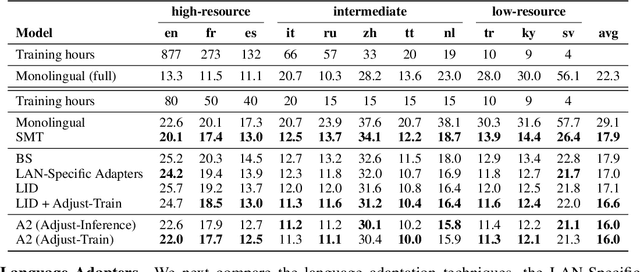
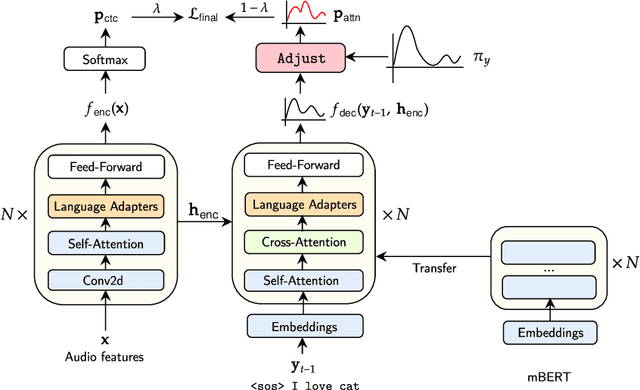
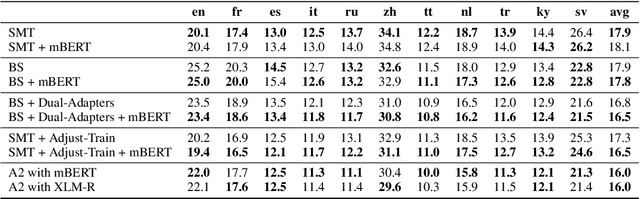
One crucial challenge of real-world multilingual speech recognition is the long-tailed distribution problem, where some resource-rich languages like English have abundant training data, but a long tail of low-resource languages have varying amounts of limited training data. To overcome the long-tail problem, in this paper, we propose Adapt-and-Adjust (A2), a transformer-based multi-task learning framework for end-to-end multilingual speech recognition. The A2 framework overcomes the long-tail problem via three techniques: (1) exploiting a pretrained multilingual language model (mBERT) to improve the performance of low-resource languages; (2) proposing dual adapters consisting of both language-specific and language-agnostic adaptation with minimal additional parameters; and (3) overcoming the class imbalance, either by imposing class priors in the loss during training or adjusting the logits of the softmax output during inference. Extensive experiments on the CommonVoice corpus show that A2 significantly outperforms conventional approaches.
Speech-XLNet: Unsupervised Acoustic Model Pretraining For Self-Attention Networks
Oct 23, 2019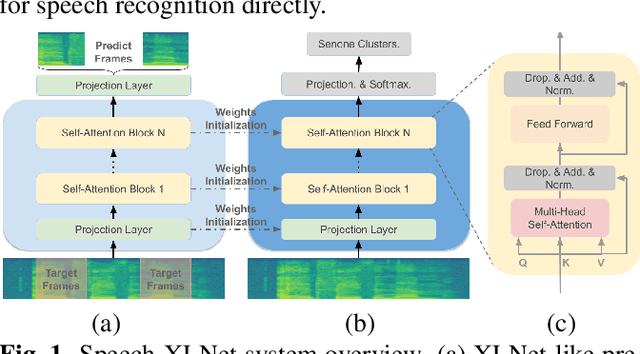
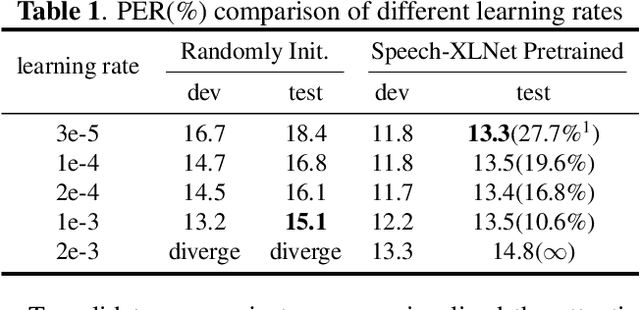
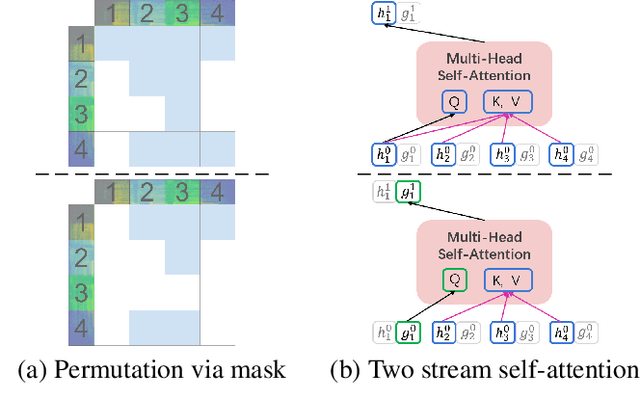
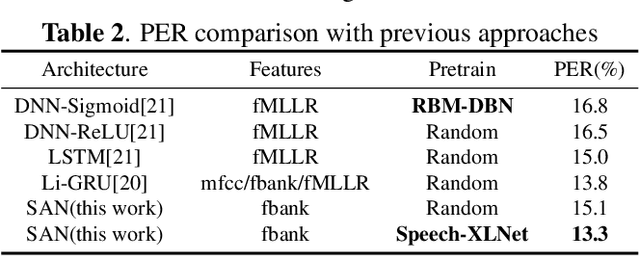
Self-attention network (SAN) can benefit significantly from the bi-directional representation learning through unsupervised pretraining paradigms such as BERT and XLNet. In this paper, we present an XLNet-like pretraining scheme "Speech-XLNet" for unsupervised acoustic model pretraining to learn speech representations with SAN. The pretrained SAN is finetuned under the hybrid SAN/HMM framework. We conjecture that by shuffling the speech frame orders, the permutation in Speech-XLNet serves as a strong regularizer to encourage the SAN to make inferences by focusing on global structures through its attention weights. In addition, Speech-XLNet also allows the model to explore the bi-directional contexts for effective speech representation learning. Experiments on TIMIT and WSJ demonstrate that Speech-XLNet greatly improves the SAN/HMM performance in terms of both convergence speed and recognition accuracy compared to the one trained from randomly initialized weights. Our best systems achieve a relative improvement of 11.9% and 8.3% on the TIMIT and WSJ tasks respectively. In particular, the best system achieves a phone error rate (PER) of 13.3% on the TIMIT test set, which to our best knowledge, is the lowest PER obtained from a single system.
A Random Gossip BMUF Process for Neural Language Modeling
Oct 16, 2019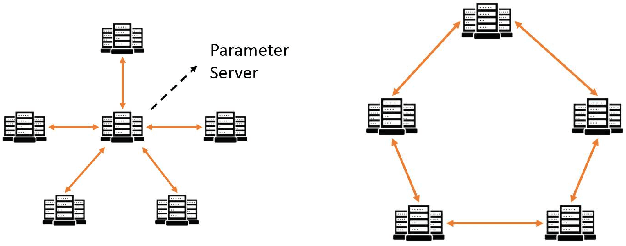
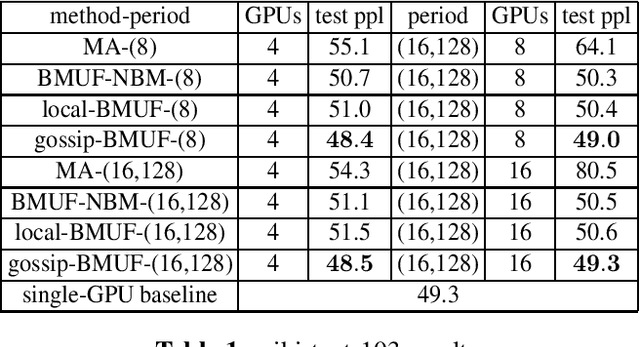
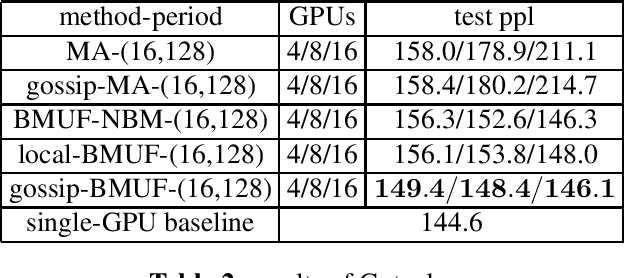
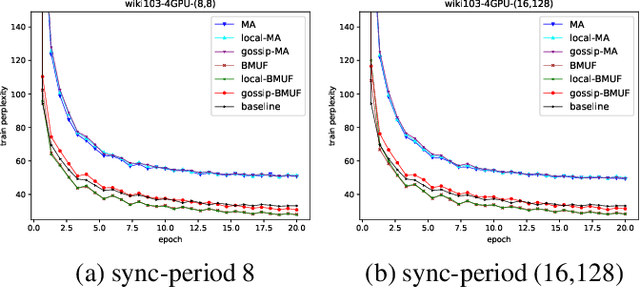
Neural network language model (NNLM) is an essential component of industrial ASR systems. One important challenge of training an NNLM is to leverage between scaling the learning process and handling big data. Conventional approaches such as block momentum provides a blockwise model update filtering (BMUF) process and achieves almost linear speedups with no performance degradation for speech recognition. However, it needs to calculate the model average from all computing nodes (e.g., GPUs) and when the number of computing nodes is large, the learning suffers from the severe communication latency. As a consequence, BMUF is not suitable under restricted network conditions. In this paper, we present a decentralized BMUF process, in which the model is split into different components, each of which is updated by communicating to some randomly chosen neighbor nodes with the same component, followed by a BMUF-like process. We apply this method to several LSTM language modeling tasks. Experimental results show that our approach achieves consistently better performance than conventional BMUF. In particular, we obtain a lower perplexity than the single-GPU baseline on the wiki-text-103 benchmark using 4 GPUs. In addition, no performance degradation is observed when scaling to 8 and 16 GPUs.
Phrase-Level Class based Language Model for Mandarin Smart Speaker Query Recognition
Sep 02, 2019
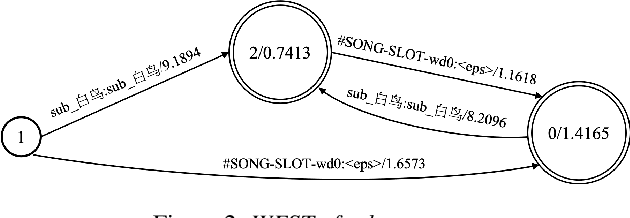
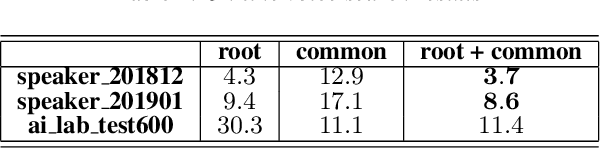
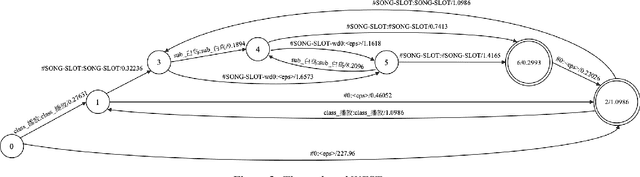
The success of speech assistants requires precise recognition of a number of entities on particular contexts. A common solution is to train a class-based n-gram language model and then expand the classes into specific words or phrases. However, when the class has a huge list, e.g., more than 20 million songs, a fully expansion will cause memory explosion. Worse still, the list items in the class need to be updated frequently, which requires a dynamic model updating technique. In this work, we propose to train pruned language models for the word classes to replace the slots in the root n-gram. We further propose to use a novel technique, named Difference Language Model (DLM), to correct the bias from the pruned language models. Once the decoding graph is built, we only need to recalculate the DLM when the entities in word classes are updated. Results show that the proposed method consistently and significantly outperforms the conventional approaches on all datasets, esp. for large lists, which the conventional approaches cannot handle.
Fantastic 4 system for NIST 2015 Language Recognition Evaluation
Feb 05, 2016
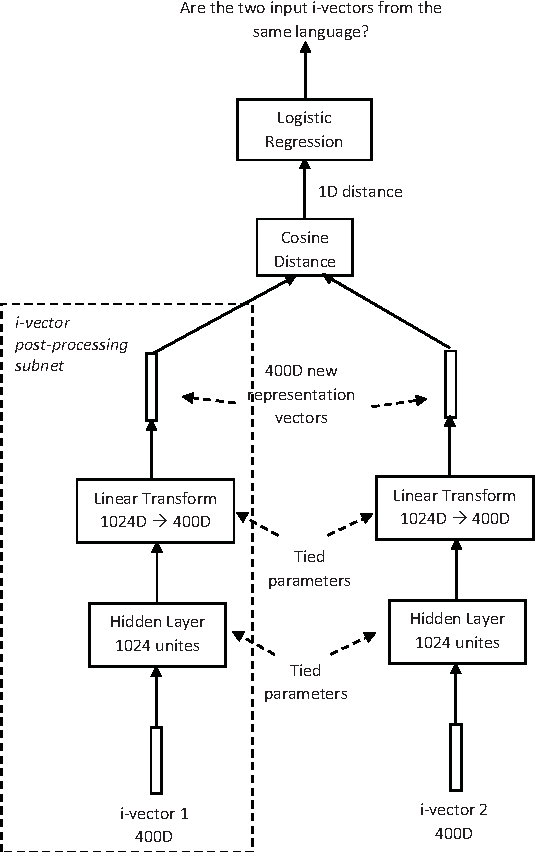
This article describes the systems jointly submitted by Institute for Infocomm (I$^2$R), the Laboratoire d'Informatique de l'Universit\'e du Maine (LIUM), Nanyang Technology University (NTU) and the University of Eastern Finland (UEF) for 2015 NIST Language Recognition Evaluation (LRE). The submitted system is a fusion of nine sub-systems based on i-vectors extracted from different types of features. Given the i-vectors, several classifiers are adopted for the language detection task including support vector machines (SVM), multi-class logistic regression (MCLR), Probabilistic Linear Discriminant Analysis (PLDA) and Deep Neural Networks (DNN).