 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenTSE: Enhancing Target Speaker Extraction via a Coarse-to-Fine Generative Language Model
Dec 24, 2025Language Model (LM)-based generative modeling has emerged as a promising direction for TSE, offering potential for improved generalization and high-fidelity speech. We present GenTSE, a two-stage decoder-only generative LM approach for TSE: Stage-1 predicts coarse semantic tokens, and Stage-2 generates fine acoustic tokens. Separating semantics and acoustics stabilizes decoding and yields more faithful, content-aligned target speech. Both stages use continuous SSL or codec embeddings, offering richer context than discretized-prompt methods. To reduce exposure bias, we employ a Frozen-LM Conditioning training strategy that conditions the LMs on predicted tokens from earlier checkpoints to reduce the gap between teacher-forcing training and autoregressive inference. We further employ DPO to better align outputs with human perceptual preferences. Experiments on Libri2Mix show that GenTSE surpasses previous LM-based systems in speech quality, intelligibility, and speaker consistency.
Joint Training or Not: An Exploration of Pre-trained Speech Models in Audio-Visual Speaker Diarization
Dec 07, 2023



The scarcity of labeled audio-visual datasets is a constraint for training superior audio-visual speaker diarization systems. To improve the performance of audio-visual speaker diarization, we leverage pre-trained supervised and self-supervised speech models for audio-visual speaker diarization. Specifically, we adopt supervised~(ResNet and ECAPA-TDNN) and self-supervised pre-trained models~(WavLM and HuBERT) as the speaker and audio embedding extractors in an end-to-end audio-visual speaker diarization~(AVSD) system. Then we explore the effectiveness of different frameworks, including Transformer, Conformer, and cross-attention mechanism, in the audio-visual decoder. To mitigate the degradation of performance caused by separate training, we jointly train the audio encoder, speaker encoder, and audio-visual decoder in the AVSD system. Experiments on the MISP dataset demonstrate that the proposed method achieves superior performance and obtained third place in MISP Challenge 2022.
The FlySpeech Audio-Visual Speaker Diarization System for MISP Challenge 2022
Jul 28, 2023


This paper describes the FlySpeech speaker diarization system submitted to the second \textbf{M}ultimodal \textbf{I}nformation Based \textbf{S}peech \textbf{P}rocessing~(\textbf{MISP}) Challenge held in ICASSP 2022. We develop an end-to-end audio-visual speaker diarization~(AVSD) system, which consists of a lip encoder, a speaker encoder, and an audio-visual decoder. Specifically, to mitigate the degradation of diarization performance caused by separate training, we jointly train the speaker encoder and the audio-visual decoder. In addition, we leverage the large-data pretrained speaker extractor to initialize the speaker encoder.
MC-SpEx: Towards Effective Speaker Extraction with Multi-Scale Interfusion and Conditional Speaker Modulation
Jun 28, 2023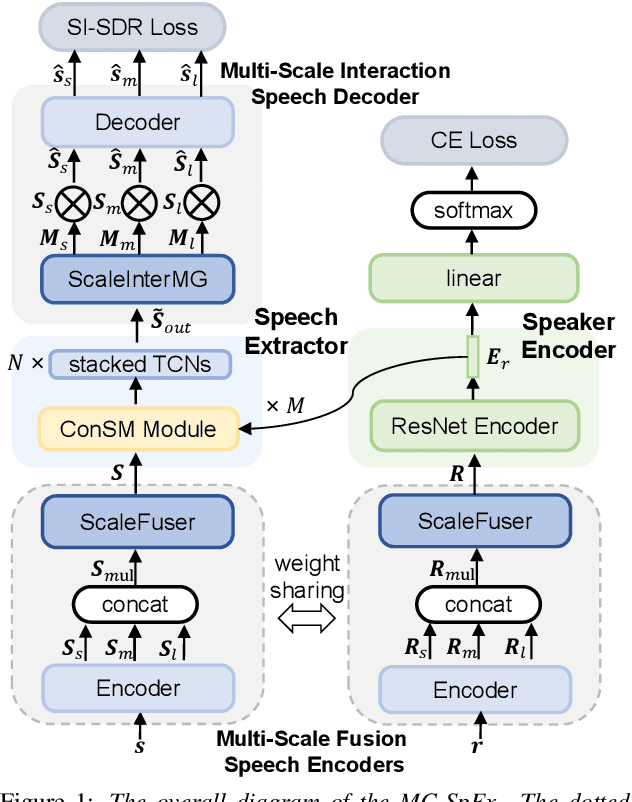

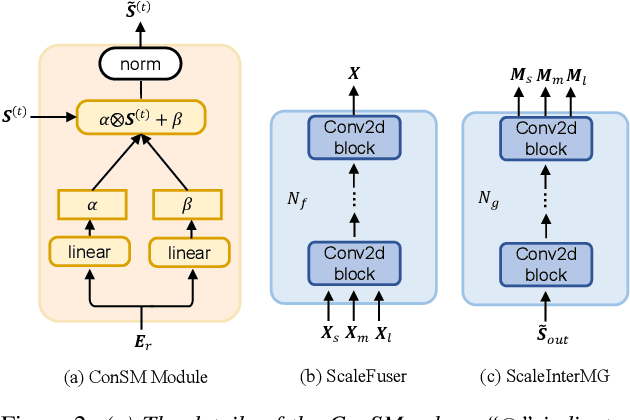

The previous SpEx+ has yielded outstanding performance in speaker extraction and attracted much attention. However, it still encounters inadequate utilization of multi-scale information and speaker embedding. To this end, this paper proposes a new effective speaker extraction system with multi-scale interfusion and conditional speaker modulation (ConSM), which is called MC-SpEx. First of all, we design the weight-share multi-scale fusers (ScaleFusers) for efficiently leveraging multi-scale information as well as ensuring consistency of the model's feature space. Then, to consider different scale information while generating masks, the multi-scale interactive mask generator (ScaleInterMG) is presented. Moreover, we introduce ConSM module to fully exploit speaker embedding in the speech extractor. Experimental results on the Libri2Mix dataset demonstrate the effectiveness of our improvements and the state-of-the-art performance of our proposed MC-SpEx.
Gesper: A Restoration-Enhancement Framework for General Speech Reconstruction
Jun 14, 2023This paper describes a real-time General Speech Reconstruction (Gesper) system submitted to the ICASSP 2023 Speech Signal Improvement (SSI) Challenge. This novel proposed system is a two-stage architecture, in which the speech restoration is performed, and then cascaded by speech enhancement. We propose a complex spectral mapping-based generative adversarial network (CSM-GAN) as the speech restoration module for the first time. For noise suppression and dereverberation, the enhancement module is performed with fullband-wideband parallel processing. On the blind test set of ICASSP 2023 SSI Challenge, the proposed Gesper system, which satisfies the real-time condition, achieves 3.27 P.804 overall mean opinion score (MOS) and 3.35 P.835 overall MOS, ranked 1st in both track 1 and track 2.
Inter-SubNet: Speech Enhancement with Subband Interaction
May 09, 2023



Subband-based approaches process subbands in parallel through the model with shared parameters to learn the commonality of local spectrums for noise reduction. In this way, they have achieved remarkable results with fewer parameters. However, in some complex environments, the lack of global spectral information has a negative impact on the performance of these subband-based approaches. To this end, this paper introduces the subband interaction as a new way to complement the subband model with the global spectral information such as cross-band dependencies and global spectral patterns, and proposes a new lightweight single-channel speech enhancement framework called Interactive Subband Network (Inter-SubNet). Experimental results on DNS Challenge - Interspeech 2021 dataset show that the proposed Inter-SubNet yields a significant improvement over the subband model and outperforms other state-of-the-art speech enhancement approaches, which demonstrate the effectiveness of subband interaction.
Distance-based Weight Transfer from Near-field to Far-field Speaker Verification
Mar 15, 2023


The scarcity of labeled far-field speech is a constraint for training superior far-field speaker verification systems. Fine-tuning the model pre-trained on large-scale near-field speech substantially outperforms training from scratch. However, the fine-tuning method suffers from two limitations--catastrophic forgetting and overfitting. In this paper, we propose a weight transfer regularization(WTR) loss to constrain the distance of the weights between the pre-trained model with large-scale near-field speech and the fine-tuned model through a small number of far-field speech. With the WTR loss, the fine-tuning process takes advantage of the previously acquired discriminative ability from the large-scale near-field speech without catastrophic forgetting. Meanwhile, we use the PAC-Bayes generalization theory to analyze the generalization bound of the fine-tuned model with the WTR loss. The analysis result indicates that the WTR term makes the fine-tuned model have a tighter generalization upper bound. Moreover, we explore three kinds of norm distance for weight transfer, which are L1-norm distance, L2-norm distance and Max-norm distance. Finally, we evaluate the effectiveness of the WTR loss on VoxCeleb (pre-trained dataset) and FFSVC (fine-tuned dataset) datasets.
TEA-PSE 3.0: Tencent-Ethereal-Audio-Lab Personalized Speech Enhancement System For ICASSP 2023 DNS Challenge
Mar 14, 2023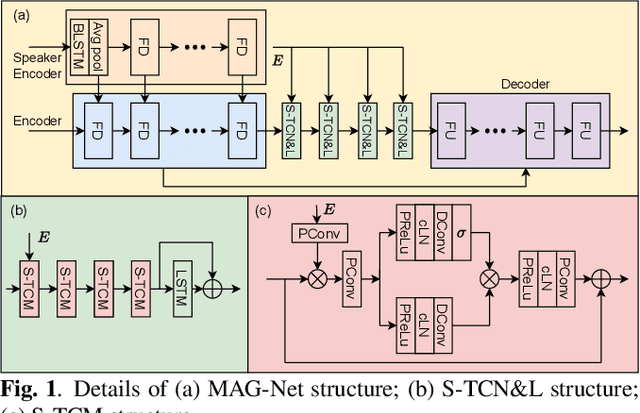


This paper introduces the Unbeatable Team's submission to the ICASSP 2023 Deep Noise Suppression (DNS) Challenge. We expand our previous work, TEA-PSE, to its upgraded version -- TEA-PSE 3.0. Specifically, TEA-PSE 3.0 incorporates a residual LSTM after squeezed temporal convolution network (S-TCN) to enhance sequence modeling capabilities. Additionally, the local-global representation (LGR) structure is introduced to boost speaker information extraction, and multi-STFT resolution loss is used to effectively capture the time-frequency characteristics of the speech signals. Moreover, retraining methods are employed based on the freeze training strategy to fine-tune the system. According to the official results, TEA-PSE 3.0 ranks 1st in both ICASSP 2023 DNS-Challenge track 1 and track 2.
Speech Enhancement with Fullband-Subband Cross-Attention Network
Nov 10, 2022FullSubNet has shown its promising performance on speech enhancement by utilizing both fullband and subband information. However, the relationship between fullband and subband in FullSubNet is achieved by simply concatenating the output of fullband model and subband units. It only supplements the subband units with a small quantity of global information and has not considered the interaction between fullband and subband. This paper proposes a fullband-subband cross-attention (FSCA) module to interactively fuse the global and local information and applies it to FullSubNet. This new framework is called as FS-CANet. Moreover, different from FullSubNet, the proposed FS-CANet optimize the fullband extractor by temporal convolutional network (TCN) blocks to further reduce the model size. Experimental results on DNS Challenge - Interspeech 2021 dataset show that the proposed FS-CANet outperforms other state-of-the-art speech enhancement approaches, and demonstrate the effectiveness of fullband-subband cross-attention.
Speech Enhancement with Intelligent Neural Homomorphic Synthesis
Oct 28, 2022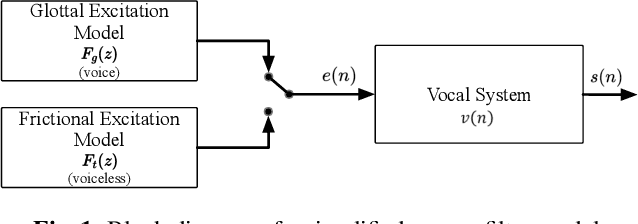
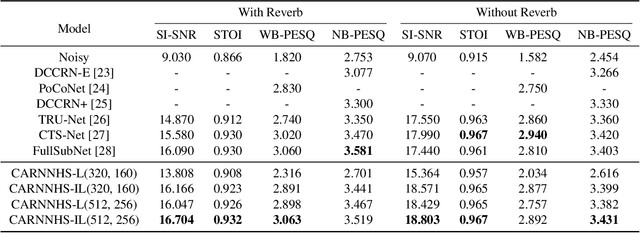

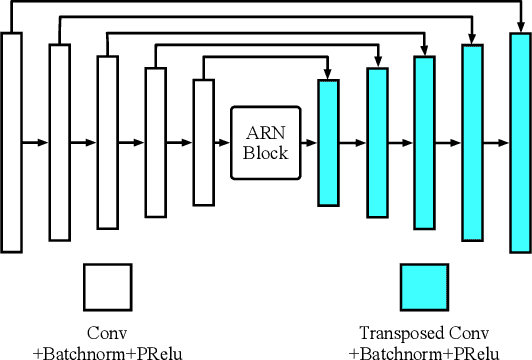
Most neural network speech enhancement models ignore speech production mathematical models by directly mapping Fourier transform spectrums or waveforms. In this work, we propose a neural source filter network for speech enhancement. Specifically, we use homomorphic signal processing and cepstral analysis to obtain noisy speech's excitation and vocal tract. Unlike traditional signal processing, we use an attentive recurrent network (ARN) model predicted ratio mask to replace the liftering separation function. Then two convolutional attentive recurrent network (CARN) networks are used to predict the excitation and vocal tract of clean speech, respectively. The system's output is synthesized from the estimated excitation and vocal. Experiments prove that our proposed method performs better, with SI-SNR improving by 1.363dB compared to FullSubNet.