 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Enhancement with Intelligent Neural Homomorphic Synthesis
Paper and Code
Oct 28, 2022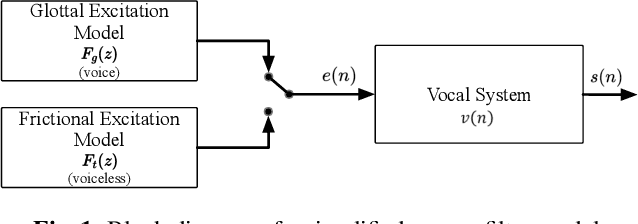
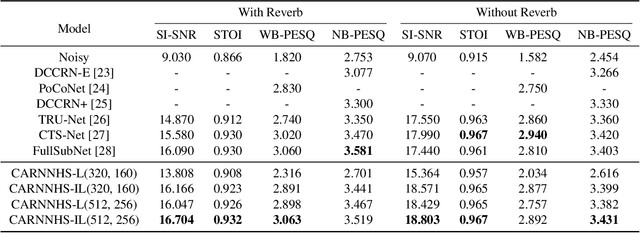

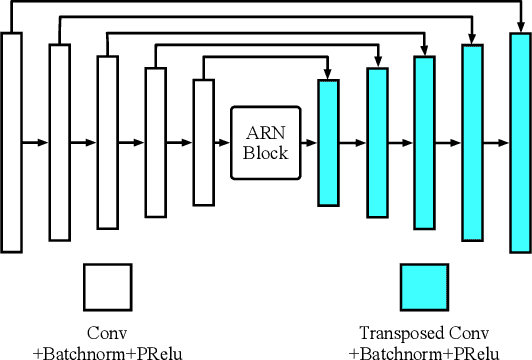
Most neural network speech enhancement models ignore speech production mathematical models by directly mapping Fourier transform spectrums or waveforms. In this work, we propose a neural source filter network for speech enhancement. Specifically, we use homomorphic signal processing and cepstral analysis to obtain noisy speech's excitation and vocal tract. Unlike traditional signal processing, we use an attentive recurrent network (ARN) model predicted ratio mask to replace the liftering separation function. Then two convolutional attentive recurrent network (CARN) networks are used to predict the excitation and vocal tract of clean speech, respectively. The system's output is synthesized from the estimated excitation and vocal. Experiments prove that our proposed method performs better, with SI-SNR improving by 1.363dB compared to FullSubNet.