 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Autoregressive Speech Synthesis Inference With Speech Speculative Decoding
May 21, 2025Modern autoregressive speech synthesis models leveraging language models have demonstrated remarkable performance. However, the sequential nature of next token prediction in these models leads to significant latency, hindering their deployment in scenarios where inference speed is critical. In this work, we propose Speech Speculative Decoding (SSD), a novel framework for autoregressive speech synthesis acceleration. Specifically, our method employs a lightweight draft model to generate candidate token sequences, which are subsequently verified in parallel by the target model using the proposed SSD framework. Experimental results demonstrate that SSD achieves a significant speedup of 1.4x compared with conventional autoregressive decoding, while maintaining high fidelity and naturalness. Subjective evaluations further validate the effectiveness of SSD in preserving the perceptual quality of the target model while accelerating inference.
Speech Enhancement with Intelligent Neural Homomorphic Synthesis
Oct 28, 2022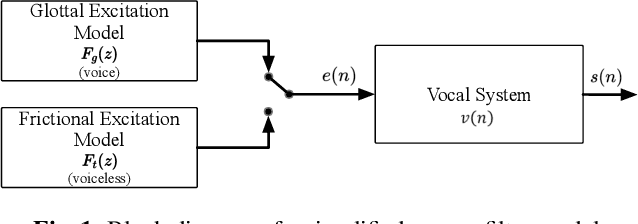
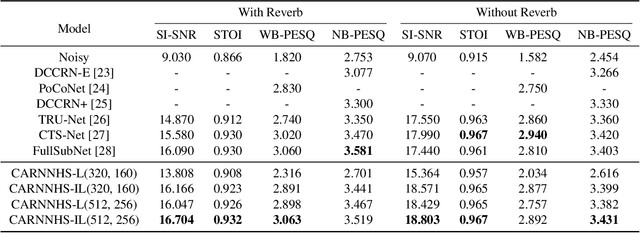

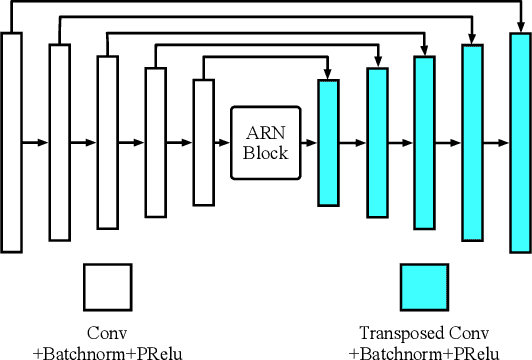
Most neural network speech enhancement models ignore speech production mathematical models by directly mapping Fourier transform spectrums or waveforms. In this work, we propose a neural source filter network for speech enhancement. Specifically, we use homomorphic signal processing and cepstral analysis to obtain noisy speech's excitation and vocal tract. Unlike traditional signal processing, we use an attentive recurrent network (ARN) model predicted ratio mask to replace the liftering separation function. Then two convolutional attentive recurrent network (CARN) networks are used to predict the excitation and vocal tract of clean speech, respectively. The system's output is synthesized from the estimated excitation and vocal. Experiments prove that our proposed method performs better, with SI-SNR improving by 1.363dB compared to FullSubNet.
LCSM: A Lightweight Complex Spectral Mapping Framework for Stereophonic Acoustic Echo Cancellation
Aug 15, 2022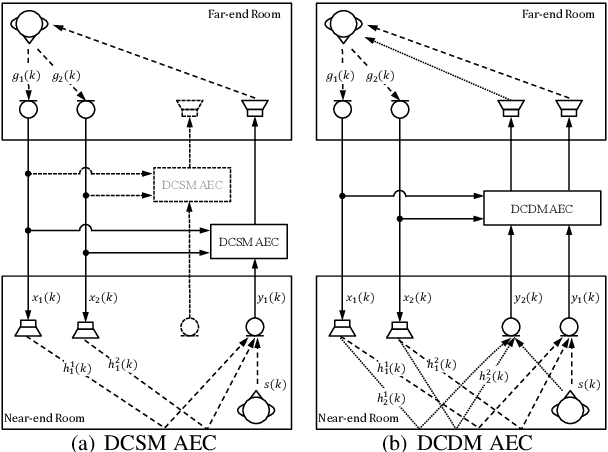


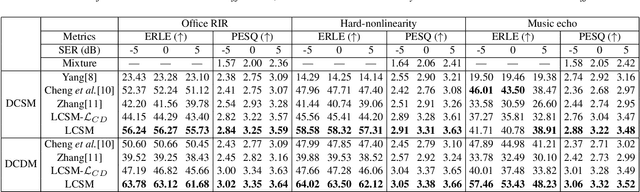
The traditional adaptive algorithms will face the non-uniqueness problem when dealing with stereophonic acoustic echo cancellation (SAEC). In this paper, we first propose an efficient multi-input and multi-output (MIMO) scheme based on deep learning to filter out echoes from all microphone signals at once. Then, we employ a lightweight complex spectral mapping framework (LCSM) for end-to-end SAEC without decorrelation preprocessing to the loudspeaker signals. Inplace convolution and channel-wise spatial modeling are utilized to ensure the near-end signal information is preserved. Finally, a cross-domain loss function is designed for better generalization capability. Experiments are evaluated on a variety of untrained conditions and results demonstrate that the LCSM significantly outperforms previous methods. Moreover, the proposed causal framework only has 0.55 million parameters, much less than the similar deep learning-based methods, which is important for the resource-limited devices.
Inplace Gated Convolutional Recurrent Neural Network For Dual-channel Speech Enhancement
Jul 26, 2021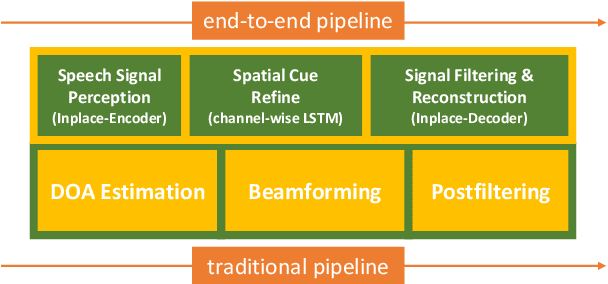
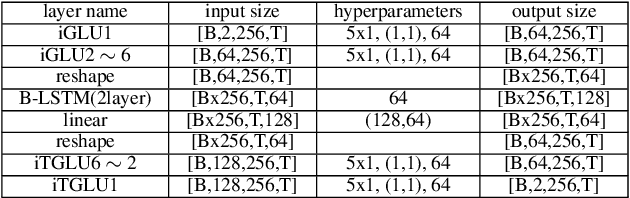


For dual-channel speech enhancement, it is a promising idea to design an end-to-end model based on the traditional array signal processing guideline and the manifold space of multi-channel signals. We found that the idea above can be effectively implemented by the classical convolutional recurrent neural networks (CRN) architecture. We propose a very compact in place gated convolutional recurrent neural network (inplace GCRN) for end-to-end multi-channel speech enhancement, which utilizes inplace-convolution for frequency pattern extraction and reconstruction. The inplace characteristics efficiently preserve spatial cues in each frequency bin for channel-wise long short-term memory neural networks (LSTM) tracing the spatial source. In addition, we come up with a new spectrum recovery method by predict amplitude mask, mapping, and phase, which effectively improves the speech quality.