 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Autoregressive Speech Synthesis Inference With Speech Speculative Decoding
May 21, 2025Modern autoregressive speech synthesis models leveraging language models have demonstrated remarkable performance. However, the sequential nature of next token prediction in these models leads to significant latency, hindering their deployment in scenarios where inference speed is critical. In this work, we propose Speech Speculative Decoding (SSD), a novel framework for autoregressive speech synthesis acceleration. Specifically, our method employs a lightweight draft model to generate candidate token sequences, which are subsequently verified in parallel by the target model using the proposed SSD framework. Experimental results demonstrate that SSD achieves a significant speedup of 1.4x compared with conventional autoregressive decoding, while maintaining high fidelity and naturalness. Subjective evaluations further validate the effectiveness of SSD in preserving the perceptual quality of the target model while accelerating inference.
Learning Audio-Visual embedding for Wild Person Verification
Sep 09, 2022



It has already been observed that audio-visual embedding can be extracted from these two modalities to gain robustness for person verification. However, the aggregator that used to generate a single utterance representation from each frame does not seem to be well explored. In this article, we proposed an audio-visual network that considers aggregator from a fusion perspective. We introduced improved attentive statistics pooling for the first time in face verification. Then we find that strong correlation exists between modalities during pooling, so joint attentive pooling is proposed which contains cycle consistency to learn the implicit inter-frame weight. Finally, fuse the modality with a gated attention mechanism. All the proposed models are trained on the VoxCeleb2 dev dataset and the best system obtains 0.18\%, 0.27\%, and 0.49\% EER on three official trail lists of VoxCeleb1 respectively, which is to our knowledge the best-published results for person verification. As an analysis, visualization maps are generated to explain how this system interact between modalities.
VRM-Phase I VKW system description of long-short video customizable keyword wakeup challenge
Oct 18, 2021Keyword wakeup technology has always been a research hotspot in speech processing, but many related works were done on different datasets. We organized a Chinese long-short video keyword wakeup challenge (Video Keyword Wakeup Challenge, VKW) for testing the ability of each participating team to build a keyword wakeup system under the public dataset. All submitted systems not only need to support the setting of multiple different keywords, but also need to support the wakeup of any costumed keyword.This paper mainly describes the basic situation of the VKW challenge and the experimental results of some participating teams.
Learning Acoustic Word Embeddings with Temporal Context for Query-by-Example Speech Search
Jun 17, 2018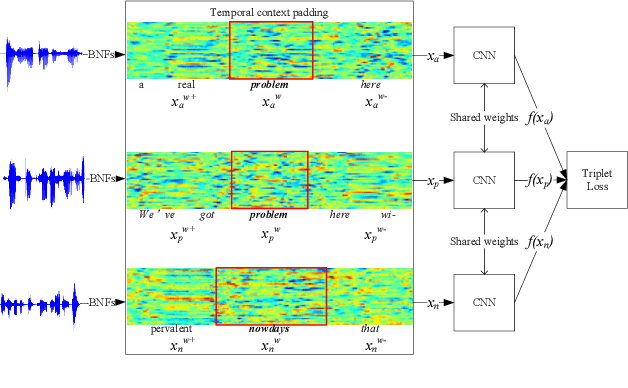
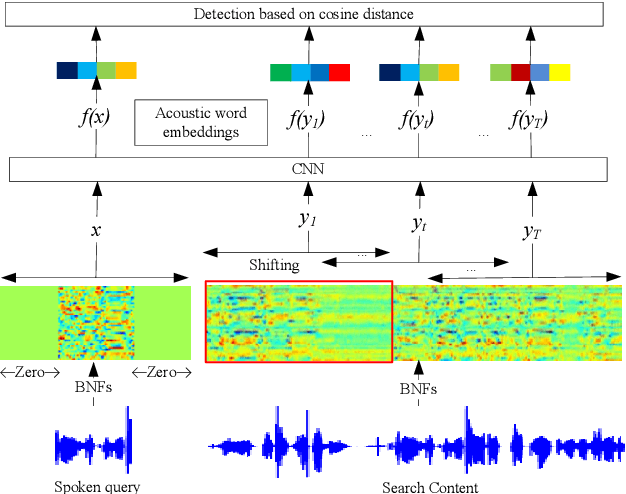
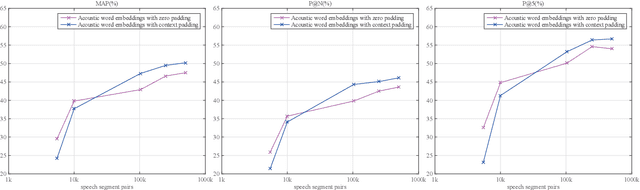
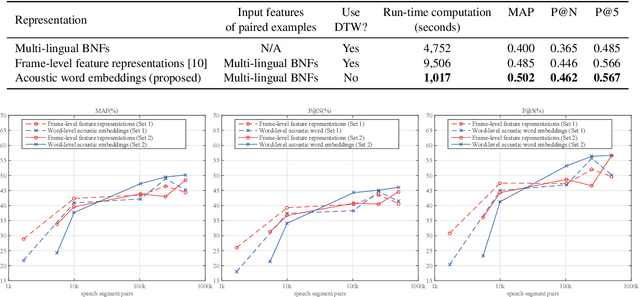
We propose to learn acoustic word embeddings with temporal context for query-by-example (QbE) speech search. The temporal context includes the leading and trailing word sequences of a word. We assume that there exist spoken word pairs in the training database. We pad the word pairs with their original temporal context to form fixed-length speech segment pairs. We obtain the acoustic word embeddings through a deep convolutional neural network (CNN) which is trained on the speech segment pairs with a triplet loss. Shifting a fixed-length analysis window through the search content, we obtain a running sequence of embeddings. In this way, searching for the spoken query is equivalent to the matching of acoustic word embeddings. The experiments show that our proposed acoustic word embeddings learned with temporal context are effective in QbE speech search. They outperform the state-of-the-art frame-level feature representations and reduce run-time computation since no dynamic time warping is required in QbE speech search. We also find that it is important to have sufficient speech segment pairs to train the deep CNN for effective acoustic word embeddings.