 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhoStream: Benchmarking Real-World Streaming for Omnimodal Assistants in Mobile Scenarios
Jan 30, 2026Multimodal Large Language Models excel at offline audio-visual understanding, but their ability to serve as mobile assistants in continuous real-world streams remains underexplored. In daily phone use, mobile assistants must track streaming audio-visual inputs and respond at the right time, yet existing benchmarks are often restricted to multiple-choice questions or use shorter videos. In this paper, we introduce PhoStream, the first mobile-centric streaming benchmark that unifies on-screen and off-screen scenarios to evaluate video, audio, and temporal reasoning. PhoStream contains 5,572 open-ended QA pairs from 578 videos across 4 scenarios and 10 capabilities. We build it with an Automated Generative Pipeline backed by rigorous human verification, and evaluate models using a realistic Online Inference Pipeline and LLM-as-a-Judge evaluation for open-ended responses. Experiments reveal a temporal asymmetry in LLM-judged scores (0-100): models perform well on Instant and Backward tasks (Gemini 3 Pro exceeds 80), but drop sharply on Forward tasks (16.40), largely due to early responses before the required visual and audio cues appear. This highlights a fundamental limitation: current MLLMs struggle to decide when to speak, not just what to say. Code and datasets used in this work will be made publicly accessible at https://github.com/Lucky-Lance/PhoStream.
SpaceVista: All-Scale Visual Spatial Reasoning from mm to km
Oct 10, 2025With the current surge in spatial reasoning explorations, researchers have made significant progress in understanding indoor scenes, but still struggle with diverse applications such as robotics and autonomous driving. This paper aims to advance all-scale spatial reasoning across diverse scenarios by tackling two key challenges: 1) the heavy reliance on indoor 3D scans and labor-intensive manual annotations for dataset curation; 2) the absence of effective all-scale scene modeling, which often leads to overfitting to individual scenes. In this paper, we introduce a holistic solution that integrates a structured spatial reasoning knowledge system, scale-aware modeling, and a progressive training paradigm, as the first attempt to broaden the all-scale spatial intelligence of MLLMs to the best of our knowledge. Using a task-specific, specialist-driven automated pipeline, we curate over 38K video scenes across 5 spatial scales to create SpaceVista-1M, a dataset comprising approximately 1M spatial QA pairs spanning 19 diverse task types. While specialist models can inject useful domain knowledge, they are not reliable for evaluation. We then build an all-scale benchmark with precise annotations by manually recording, retrieving, and assembling video-based data. However, naive training with SpaceVista-1M often yields suboptimal results due to the potential knowledge conflict. Accordingly, we introduce SpaceVista-7B, a spatial reasoning model that accepts dense inputs beyond semantics and uses scale as an anchor for scale-aware experts and progressive rewards. Finally, extensive evaluations across 5 benchmarks, including our SpaceVista-Bench, demonstrate competitive performance, showcasing strong generalization across all scales and scenarios. Our dataset, model, and benchmark will be released on https://peiwensun2000.github.io/mm2km .
OmniAudio: Generating Spatial Audio from 360-Degree Video
Apr 21, 2025
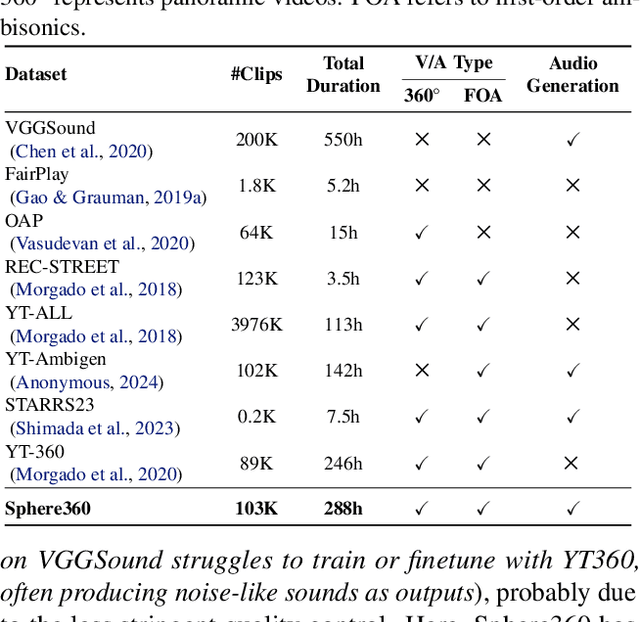
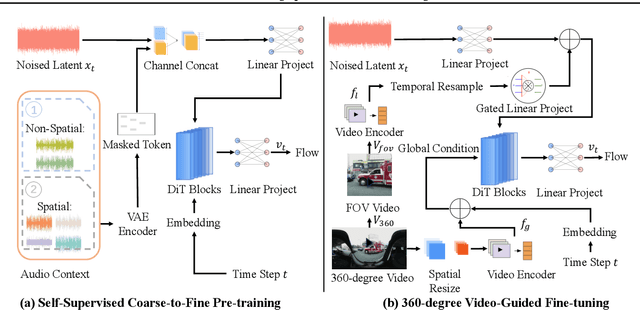
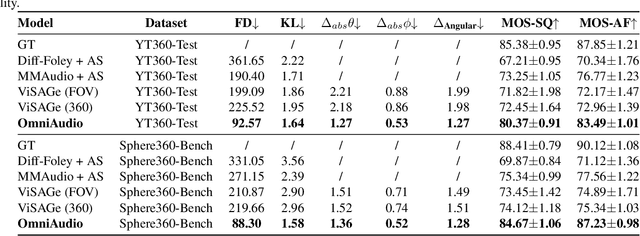
Traditional video-to-audio generation techniques primarily focus on field-of-view (FoV) video and non-spatial audio, often missing the spatial cues necessary for accurately representing sound sources in 3D environments. To address this limitation, we introduce a novel task, 360V2SA, to generate spatial audio from 360-degree videos, specifically producing First-order Ambisonics (FOA) audio - a standard format for representing 3D spatial audio that captures sound directionality and enables realistic 3D audio reproduction. We first create Sphere360, a novel dataset tailored for this task that is curated from real-world data. We also design an efficient semi-automated pipeline for collecting and cleaning paired video-audio data. To generate spatial audio from 360-degree video, we propose a novel framework OmniAudio, which leverages self-supervised pre-training using both spatial audio data (in FOA format) and large-scale non-spatial data. Furthermore, OmniAudio features a dual-branch framework that utilizes both panoramic and FoV video inputs to capture comprehensive local and global information from 360-degree videos. Experimental results demonstrate that OmniAudio achieves state-of-the-art performance across both objective and subjective metrics on Sphere360. Code and datasets will be released at https://github.com/liuhuadai/OmniAudio. The demo page is available at https://OmniAudio-360V2SA.github.io.
Both Ears Wide Open: Towards Language-Driven Spatial Audio Generation
Oct 14, 2024



Recently, diffusion models have achieved great success in mono-channel audio generation. However, when it comes to stereo audio generation, the soundscapes often have a complex scene of multiple objects and directions. Controlling stereo audio with spatial contexts remains challenging due to high data costs and unstable generative models. To the best of our knowledge, this work represents the first attempt to address these issues. We first construct a large-scale, simulation-based, and GPT-assisted dataset, BEWO-1M, with abundant soundscapes and descriptions even including moving and multiple sources. Beyond text modality, we have also acquired a set of images and rationally paired stereo audios through retrieval to advance multimodal generation. Existing audio generation models tend to generate rather random and indistinct spatial audio. To provide accurate guidance for latent diffusion models, we introduce the SpatialSonic model utilizing spatial-aware encoders and azimuth state matrices to reveal reasonable spatial guidance. By leveraging spatial guidance, our unified model not only achieves the objective of generating immersive and controllable spatial audio from text and image but also enables interactive audio generation during inference. Finally, under fair settings, we conduct subjective and objective evaluations on simulated and real-world data to compare our approach with prevailing methods. The results demonstrate the effectiveness of our method, highlighting its capability to generate spatial audio that adheres to physical rules.
Codec Does Matter: Exploring the Semantic Shortcoming of Codec for Audio Language Model
Aug 30, 2024



Recent advancements in audio generation have been significantly propelled by the capabilities of Large Language Models (LLMs). The existing research on audio LLM has primarily focused on enhancing the architecture and scale of audio language models, as well as leveraging larger datasets, and generally, acoustic codecs, such as EnCodec, are used for audio tokenization. However, these codecs were originally designed for audio compression, which may lead to suboptimal performance in the context of audio LLM. Our research aims to address the shortcomings of current audio LLM codecs, particularly their challenges in maintaining semantic integrity in generated audio. For instance, existing methods like VALL-E, which condition acoustic token generation on text transcriptions, often suffer from content inaccuracies and elevated word error rates (WER) due to semantic misinterpretations of acoustic tokens, resulting in word skipping and errors. To overcome these issues, we propose a straightforward yet effective approach called X-Codec. X-Codec incorporates semantic features from a pre-trained semantic encoder before the Residual Vector Quantization (RVQ) stage and introduces a semantic reconstruction loss after RVQ. By enhancing the semantic ability of the codec, X-Codec significantly reduces WER in speech synthesis tasks and extends these benefits to non-speech applications, including music and sound generation. Our experiments in text-to-speech, music continuation, and text-to-sound tasks demonstrate that integrating semantic information substantially improves the overall performance of language models in audio generation. Our code and demo are available (Demo: https://x-codec-audio.github.io Code: https://github.com/zhenye234/xcodec)
Unveiling and Mitigating Bias in Audio Visual Segmentation
Jul 23, 2024



Community researchers have developed a range of advanced audio-visual segmentation models aimed at improving the quality of sounding objects' masks. While masks created by these models may initially appear plausible, they occasionally exhibit anomalies with incorrect grounding logic. We attribute this to real-world inherent preferences and distributions as a simpler signal for learning than the complex audio-visual grounding, which leads to the disregard of important modality information. Generally, the anomalous phenomena are often complex and cannot be directly observed systematically. In this study, we made a pioneering effort with the proper synthetic data to categorize and analyze phenomena as two types "audio priming bias" and "visual prior" according to the source of anomalies. For audio priming bias, to enhance audio sensitivity to different intensities and semantics, a perception module specifically for audio perceives the latent semantic information and incorporates information into a limited set of queries, namely active queries. Moreover, the interaction mechanism related to such active queries in the transformer decoder is customized to adapt to the need for interaction regulating among audio semantics. For visual prior, multiple contrastive training strategies are explored to optimize the model by incorporating a biased branch, without even changing the structure of the model. During experiments, observation demonstrates the presence and the impact that has been produced by the biases of the existing model. Finally, through experimental evaluation of AVS benchmarks, we demonstrate the effectiveness of our methods in handling both types of biases, achieving competitive performance across all three subsets.
Stepping Stones: A Progressive Training Strategy for Audio-Visual Semantic Segmentation
Jul 16, 2024



Audio-Visual Segmentation (AVS) aims to achieve pixel-level localization of sound sources in videos, while Audio-Visual Semantic Segmentation (AVSS), as an extension of AVS, further pursues semantic understanding of audio-visual scenes. However, since the AVSS task requires the establishment of audio-visual correspondence and semantic understanding simultaneously, we observe that previous methods have struggled to handle this mashup of objectives in end-to-end training, resulting in insufficient learning and sub-optimization. Therefore, we propose a two-stage training strategy called \textit{Stepping Stones}, which decomposes the AVSS task into two simple subtasks from localization to semantic understanding, which are fully optimized in each stage to achieve step-by-step global optimization. This training strategy has also proved its generalization and effectiveness on existing methods. To further improve the performance of AVS tasks, we propose a novel framework Adaptive Audio Visual Segmentation, in which we incorporate an adaptive audio query generator and integrate masked attention into the transformer decoder, facilitating the adaptive fusion of visual and audio features. Extensive experiments demonstrate that our methods achieve state-of-the-art results on all three AVS benchmarks. The project homepage can be accessed at https://gewu-lab.github.io/stepping_stones/.
Ref-AVS: Refer and Segment Objects in Audio-Visual Scenes
Jul 15, 2024Traditional reference segmentation tasks have predominantly focused on silent visual scenes, neglecting the integral role of multimodal perception and interaction in human experiences. In this work, we introduce a novel task called Reference Audio-Visual Segmentation (Ref-AVS), which seeks to segment objects within the visual domain based on expressions containing multimodal cues. Such expressions are articulated in natural language forms but are enriched with multimodal cues, including audio and visual descriptions. To facilitate this research, we construct the first Ref-AVS benchmark, which provides pixel-level annotations for objects described in corresponding multimodal-cue expressions. To tackle the Ref-AVS task, we propose a new method that adequately utilizes multimodal cues to offer precise segmentation guidance. Finally, we conduct quantitative and qualitative experiments on three test subsets to compare our approach with existing methods from related tasks. The results demonstrate the effectiveness of our method, highlighting its capability to precisely segment objects using multimodal-cue expressions. Dataset is available at \href{https://gewu-lab.github.io/Ref-AVS}{https://gewu-lab.github.io/Ref-AVS}.
Can Textual Semantics Mitigate Sounding Object Segmentation Preference?
Jul 15, 2024



The Audio-Visual Segmentation (AVS) task aims to segment sounding objects in the visual space using audio cues. However, in this work, it is recognized that previous AVS methods show a heavy reliance on detrimental segmentation preferences related to audible objects, rather than precise audio guidance. We argue that the primary reason is that audio lacks robust semantics compared to vision, especially in multi-source sounding scenes, resulting in weak audio guidance over the visual space. Motivated by the the fact that text modality is well explored and contains rich abstract semantics, we propose leveraging text cues from the visual scene to enhance audio guidance with the semantics inherent in text. Our approach begins by obtaining scene descriptions through an off-the-shelf image captioner and prompting a frozen large language model to deduce potential sounding objects as text cues. Subsequently, we introduce a novel semantics-driven audio modeling module with a dynamic mask to integrate audio features with text cues, leading to representative sounding object features. These features not only encompass audio cues but also possess vivid semantics, providing clearer guidance in the visual space. Experimental results on AVS benchmarks validate that our method exhibits enhanced sensitivity to audio when aided by text cues, achieving highly competitive performance on all three subsets. Project page: \href{https://github.com/GeWu-Lab/Sounding-Object-Segmentation-Preference}{https://github.com/GeWu-Lab/Sounding-Object-Segmentation-Preference}
FlashSpeech: Efficient Zero-Shot Speech Synthesis
Apr 25, 2024



Recent progress in large-scale zero-shot speech synthesis has been significantly advanced by language models and diffusion models. However, the generation process of both methods is slow and computationally intensive. Efficient speech synthesis using a lower computing budget to achieve quality on par with previous work remains a significant challenge. In this paper, we present FlashSpeech, a large-scale zero-shot speech synthesis system with approximately 5\% of the inference time compared with previous work. FlashSpeech is built on the latent consistency model and applies a novel adversarial consistency training approach that can train from scratch without the need for a pre-trained diffusion model as the teacher. Furthermore, a new prosody generator module enhances the diversity of prosody, making the rhythm of the speech sound more natural. The generation processes of FlashSpeech can be achieved efficiently with one or two sampling steps while maintaining high audio quality and high similarity to the audio prompt for zero-shot speech generation. Our experimental results demonstrate the superior performance of FlashSpeech. Notably, FlashSpeech can be about 20 times faster than other zero-shot speech synthesis systems while maintaining comparable performance in terms of voice quality and similarity. Furthermore, FlashSpeech demonstrates its versatility by efficiently performing tasks like voice conversion, speech editing, and diverse speech sampling. Audio samples can be found in https://flashspeech.github.io/.