 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Token Compression for Accelerating ViT-based Sparse Multi-View 3D Object Detectors
Apr 16, 2026Vision Transformer (ViT)-based sparse multi-view 3D object detectors have achieved remarkable accuracy but still suffer from high inference latency due to heavy token processing. To accelerate these models, token compression has been widely explored. However, our revisit of existing strategies, such as token pruning, merging, and patch size enlargement, reveals that they often discard informative background cues, disrupt contextual consistency, and lose fine-grained semantics, negatively affecting 3D detection. To overcome these limitations, we propose SEPatch3D, a novel framework that dynamically adjusts patch sizes while preserving critical semantic information within coarse patches. Specifically, we design Spatiotemporal-aware Patch Size Selection (SPSS) that assigns small patches to scenes containing nearby objects to preserve fine details and large patches to background-dominated scenes to reduce computation cost. To further mitigate potential detail loss, Informative Patch Selection (IPS) selects the informative patches for feature refinement, and Cross-Granularity Feature Enhancement (CGFE) injects fine-grained details into selected coarse patches, enriching semantic features. Experiments on the nuScenes and Argoverse 2 validation sets show that SEPatch3D achieves up to \textbf{57\%} faster inference than the StreamPETR baseline and \textbf{20\%} higher efficiency than the state-of-the-art ToC3D-faster, while preserving comparable detection accuracy. Code is available at https://github.com/Mingqj/SEPatch3D.
RayMamba: Ray-Aligned Serialization for Long-Range 3D Object Detection
Apr 03, 2026Long-range 3D object detection remains challenging because LiDAR observations become highly sparse and fragmented in the far field, making reliable context modeling difficult for existing detectors. To address this issue, recent state space model (SSM)-based methods have improved long-range modeling efficiency. However, their effectiveness is still limited by generic serialization strategies that fail to preserve meaningful contextual neighborhoods in sparse scenes. To address this issue, we propose RayMamba, a geometry-aware plug-and-play enhancement for voxel-based 3D detectors. RayMamba organizes sparse voxels into sector-wise ordered sequences through a ray-aligned serialization strategy, which preserves directional continuity and occlusion-related context for subsequent Mamba-based modeling. It is compatible with both LiDAR-only and multimodal detectors, while introducing only modest overhead. Extensive experiments on nuScenes and Argoverse 2 demonstrate consistent improvements across strong baselines. In particular, RayMamba achieves up to 2.49 mAP and 1.59 NDS gain in the challenging 40--50 m range on nuScenes, and further improves VoxelNeXt on Argoverse 2 from 30.3 to 31.2 mAP.
MambaIO: Global-Coordinate Inertial Odometry for Pedestrians via Multi-Scale Frequency-Decoupled Modeling
Nov 19, 2025Inertial Odometry (IO) enables real-time localization using only acceleration and angular velocity measurements from an Inertial Measurement Unit (IMU), making it a promising solution for localization in consumer-grade applications. Traditionally, IMU measurements in IO have been processed under two coordinate system paradigms: the body coordinate frame and the global coordinate frame, with the latter being widely adopted. However, recent studies in drone scenarios have demonstrated that the body frame can significantly improve localization accuracy, prompting a re-evaluation of the suitability of the global frame for pedestrian IO. To address this issue, this paper systematically evaluates the effectiveness of the global coordinate frame in pedestrian IO through theoretical analysis, qualitative inspection, and quantitative experiments. Building upon these findings, we further propose MambaIO, which decomposes IMU measurements into high-frequency and low-frequency components using a Laplacian pyramid. The low-frequency component is processed by a Mamba architecture to extract implicit contextual motion cues, while the high-frequency component is handled by a convolutional structure to capture fine-grained local motion details. Experiments on multiple public datasets show that MambaIO substantially reduces localization error and achieves state-of-the-art (SOTA) performance. To the best of our knowledge, this is the first application of the Mamba architecture to the inertial odometry task.
IONext: Unlocking the Next Era of Inertial Odometry
Jul 23, 2025Researchers have increasingly adopted Transformer-based models for inertial odometry. While Transformers excel at modeling long-range dependencies, their limited sensitivity to local, fine-grained motion variations and lack of inherent inductive biases often hinder localization accuracy and generalization. Recent studies have shown that incorporating large-kernel convolutions and Transformer-inspired architectural designs into CNN can effectively expand the receptive field, thereby improving global motion perception. Motivated by these insights, we propose a novel CNN-based module called the Dual-wing Adaptive Dynamic Mixer (DADM), which adaptively captures both global motion patterns and local, fine-grained motion features from dynamic inputs. This module dynamically generates selective weights based on the input, enabling efficient multi-scale feature aggregation. To further improve temporal modeling, we introduce the Spatio-Temporal Gating Unit (STGU), which selectively extracts representative and task-relevant motion features in the temporal domain. This unit addresses the limitations of temporal modeling observed in existing CNN approaches. Built upon DADM and STGU, we present a new CNN-based inertial odometry backbone, named Next Era of Inertial Odometry (IONext). Extensive experiments on six public datasets demonstrate that IONext consistently outperforms state-of-the-art (SOTA) Transformer- and CNN-based methods. For instance, on the RNIN dataset, IONext reduces the average ATE by 10% and the average RTE by 12% compared to the representative model iMOT.
DepthFusion: Depth-Aware Hybrid Feature Fusion for LiDAR-Camera 3D Object Detection
May 12, 2025State-of-the-art LiDAR-camera 3D object detectors usually focus on feature fusion. However, they neglect the factor of depth while designing the fusion strategy. In this work, we are the first to observe that different modalities play different roles as depth varies via statistical analysis and visualization. Based on this finding, we propose a Depth-Aware Hybrid Feature Fusion (DepthFusion) strategy that guides the weights of point cloud and RGB image modalities by introducing depth encoding at both global and local levels. Specifically, the Depth-GFusion module adaptively adjusts the weights of image Bird's-Eye-View (BEV) features in multi-modal global features via depth encoding. Furthermore, to compensate for the information lost when transferring raw features to the BEV space, we propose a Depth-LFusion module, which adaptively adjusts the weights of original voxel features and multi-view image features in multi-modal local features via depth encoding. Extensive experiments on the nuScenes and KITTI datasets demonstrate that our DepthFusion method surpasses previous state-of-the-art methods. Moreover, our DepthFusion is more robust to various kinds of corruptions, outperforming previous methods on the nuScenes-C dataset.
Safe Flow Matching: Robot Motion Planning with Control Barrier Functions
Apr 11, 2025Recent advances in generative modeling have led to promising results in robot motion planning, particularly through diffusion and flow-based models that capture complex, multimodal trajectory distributions. However, these methods are typically trained offline and remain limited when faced with unseen environments or dynamic constraints, often lacking explicit mechanisms to ensure safety during deployment. In this work, we propose, Safe Flow Matching (SafeFM), a motion planning approach for trajectory generation that integrates flow matching with safety guarantees. By incorporating the proposed flow matching barrier functions, SafeFM ensures that generated trajectories remain within safe regions throughout the planning horizon, even in the presence of previously unseen obstacles or state-action constraints. Unlike diffusion-based approaches, our method allows for direct, efficient sampling of constraint-satisfying trajectories, making it well-suited for real-time motion planning. We evaluate SafeFM on a diverse set of tasks, including planar robot navigation and 7-DoF manipulation, demonstrating superior safety, generalization, and planning performance compared to state-of-the-art generative planners. Comprehensive resources are available on the project website: https://safeflowmatching.github.io/SafeFM/
SoccerNet 2024 Challenges Results
Sep 16, 2024

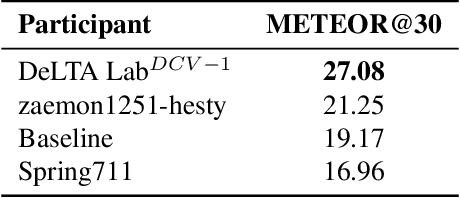
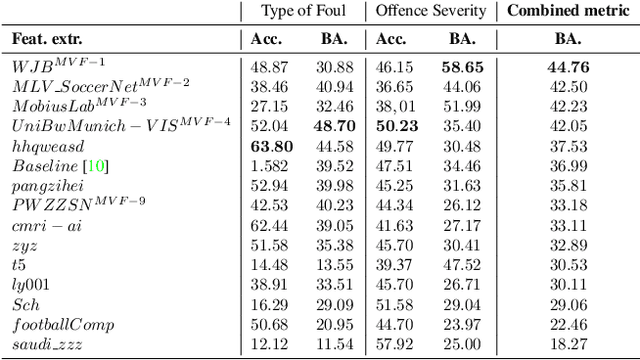
The SoccerNet 2024 challenges represent the fourth annual video understanding challenges organized by the SoccerNet team. These challenges aim to advance research across multiple themes in football, including broadcast video understanding, field understanding, and player understanding. This year, the challenges encompass four vision-based tasks. (1) Ball Action Spotting, focusing on precisely localizing when and which soccer actions related to the ball occur, (2) Dense Video Captioning, focusing on describing the broadcast with natural language and anchored timestamps, (3) Multi-View Foul Recognition, a novel task focusing on analyzing multiple viewpoints of a potential foul incident to classify whether a foul occurred and assess its severity, (4) Game State Reconstruction, another novel task focusing on reconstructing the game state from broadcast videos onto a 2D top-view map of the field. Detailed information about the tasks, challenges, and leaderboards can be found at https://www.soccer-net.org, with baselines and development kits available at https://github.com/SoccerNet.
Imagine the Unseen: Occluded Pedestrian Detection via Adversarial Feature Completion
May 02, 2024Pedestrian detection has significantly progressed in recent years, thanks to the development of DNNs. However, detection performance at occluded scenes is still far from satisfactory, as occlusion increases the intra-class variance of pedestrians, hindering the model from finding an accurate classification boundary between pedestrians and background clutters. From the perspective of reducing intra-class variance, we propose to complete features for occluded regions so as to align the features of pedestrians across different occlusion patterns. An important premise for feature completion is to locate occluded regions. From our analysis, channel features of different pedestrian proposals only show high correlation values at visible parts and thus feature correlations can be used to model occlusion patterns. In order to narrow down the gap between completed features and real fully visible ones, we propose an adversarial learning method, which completes occluded features with a generator such that they can hardly be distinguished by the discriminator from real fully visible features. We report experimental results on the CityPersons, Caltech and CrowdHuman datasets. On CityPersons, we show significant improvements over five different baseline detectors, especially on the heavy occlusion subset. Furthermore, we show that our proposed method FeatComp++ achieves state-of-the-art results on all the above three datasets without relying on extra cues.
Fairness Optimization for Intelligent Reflecting Surface Aided Uplink Rate-Splitting Multiple Access
Mar 15, 2024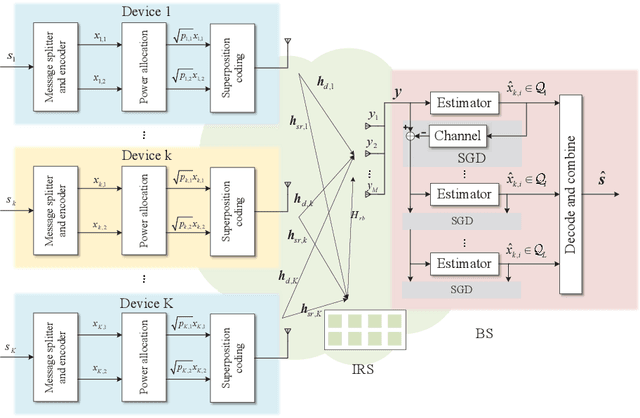
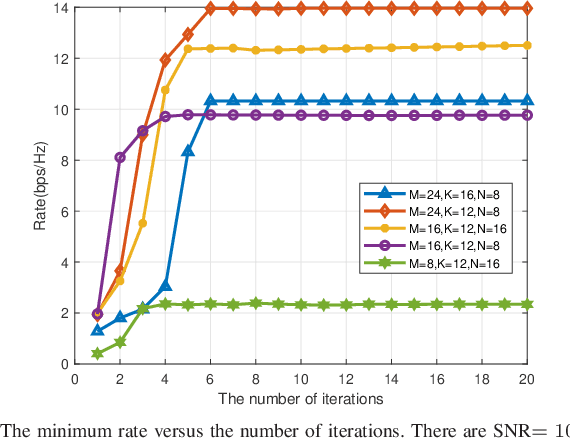
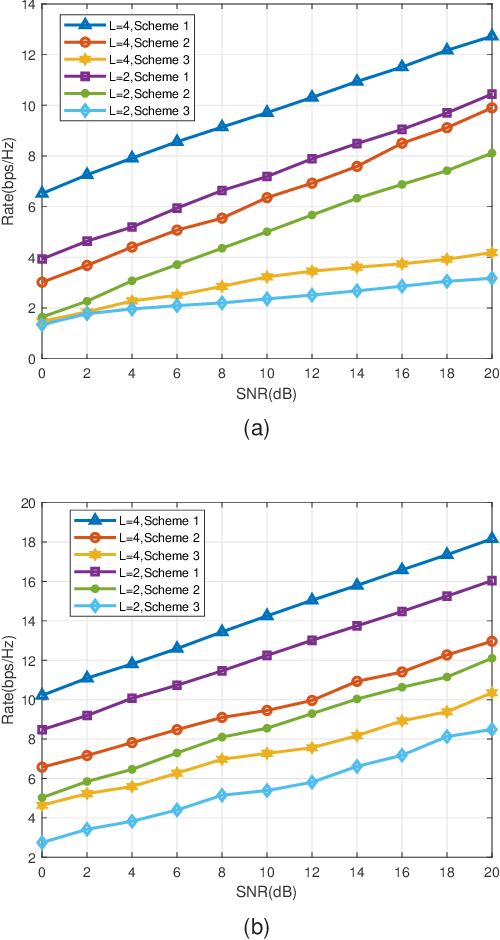
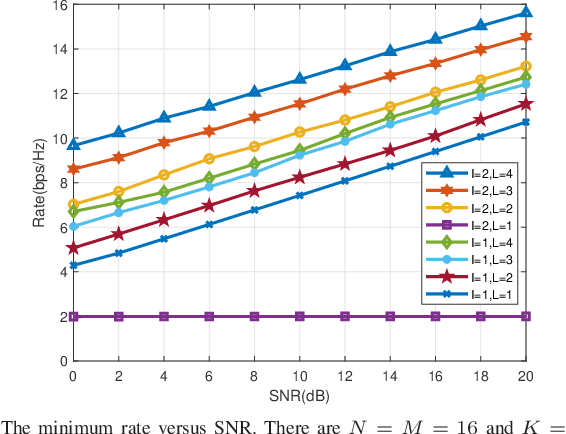
This paper studies the fair transmission design for an intelligent reflecting surface (IRS) aided rate-splitting multiple access (RSMA). IRS is used to establish a good signal propagation environment and enhance the RSMA transmission performance. The fair rate adaption problem is constructed as a max-min optimization problem. To solve the optimization problem, we adopt an alternative optimization (AO) algorithm to optimize the power allocation, beamforming, and decoding order, respectively. A generalized power iteration (GPI) method is proposed to optimize the receive beamforming, which can improve the minimum rate of devices and reduce the optimization complexity. At the base station (BS), a successive group decoding (SGD) algorithm is proposed to tackle the uplink signal estimation, which trades off the fairness and complexity of decoding. At the same time, we also consider robust communication with imperfect channel state information at the transmitter (CSIT), which studies robust optimization by using lower bound expressions on the expected data rates. Extensive numerical results show that the proposed optimization algorithm can significantly improve the performance of fairness. It also provides reliable results for uplink communication with imperfect CSIT.
Rate-Splitting Multiple Access for Transmissive Reconfigurable Intelligent Surface Transceiver Empowered ISAC System
Feb 19, 2024In this paper, a novel transmissive reconfigurable intelligent surface (TRIS) transceiver empowered integrated sensing and communications (ISAC) system is proposed for future multi-demand terminals. To address interference management, we implement rate-splitting multiple access (RSMA), where the common stream is independently designed for the sensing service. We introduce the sensing quality of service (QoS) criteria based on this structure and construct an optimization problem with the sensing QoS criteria as the objective function to optimize the sensing stream precoding matrix and the communication stream precoding matrix. Due to the coupling of optimization variables, the formulated problem is a non-convex optimization problem that cannot be solved directly. To tackle the above-mentioned challenging problem, alternating optimization (AO) is utilized to decouple the optimization variables. Specifically, the problem is decoupled into three subproblems about the sensing stream precoding matrix, the communication stream precoding matrix, and the auxiliary variables, which is solved alternatively through AO until the convergence is reached. For solving the problem, successive convex approximation (SCA) is applied to deal with the sum-rate threshold constraints on communications, and difference-of-convex (DC) programming is utilized to solve rank-one non-convex constraints. Numerical simulation results verify the superiority of the proposed scheme in terms of improving the communication and sensing QoS.